
PostgreSQL 複製:綜合指南
已發表: 2022-08-11正如任何網站所有者都會告訴您的那樣,數據丟失和停機時間,即使是最小的劑量,也可能是災難性的。 他們可以隨時打擊措手不及的人,從而導致生產力、可訪問性和產品信心降低。
為了保護您的站點的完整性,構建防止停機或數據丟失可能性的保護措施至關重要。
這就是數據複製的用武之地。
數據複製是一個自動備份過程,在該過程中,您的數據會從其主數據庫重複複製到另一個遠程位置以進行安全保護。 對於任何運行數據庫服務器的站點或應用程序來說,它都是一項不可或缺的技術。 您還可以利用複制的數據庫來處理只讀 SQL,從而允許在系統內運行更多進程。
在兩個數據庫之間設置複製提供了針對意外事故的容錯能力。 它被認為是在災難期間實現高可用性的最佳策略。
在本文中,我們將深入探討後端開發人員可以為無縫 PostgreSQL 複製實施的不同策略。
什麼是 PostgreSQL 複製?
PostgreSQL 複製被定義為將數據從 PostgreSQL 數據庫服務器複製到另一台服務器的過程。 源數據庫服務器也稱為“主”服務器,而接收復制數據的數據庫服務器稱為“副本”服務器。
PostgreSQL 數據庫遵循簡單的複制模型,其中所有寫入都轉到主節點。 然後主節點可以應用這些更改並將它們廣播到輔助節點。
什麼是自動故障轉移?
一旦在 PostgreSQL 中配置了物理流複製,如果數據庫的主服務器發生故障,就會發生故障轉移。 故障轉移用於定義恢復過程,這可能需要一段時間,因為它不提供用於確定服務器故障範圍的內置工具。
您不必依賴 PostgreSQL 進行故障轉移。 有專用工具允許自動故障轉移和自動切換到備用數據庫,從而減少數據庫停機時間。
通過設置故障轉移複製,您幾乎可以通過確保在主服務器崩潰時備用服務器可用來保證高可用性。
使用 PostgreSQL 複製的好處
以下是利用 PostgreSQL 複製的幾個主要好處:
- 數據遷移:您可以通過更改數據庫服務器硬件或通過系統部署利用 PostgreSQL 複製進行數據遷移。
- 容錯:如果主服務器發生故障,備用服務器可以充當服務器,因為主服務器和備用服務器包含的數據相同。
- 在線事務處理 (OLTP) 性能:您可以通過消除報告查詢負載來提高 OLTP 系統的事務處理時間和查詢時間。 事務處理時間是在事務完成之前執行給定查詢所需的持續時間。
- 並行系統測試:升級新系統時,您需要確保系統能夠很好地處理現有數據,因此需要在部署之前使用生產數據庫副本進行測試。
PostgreSQL 複製的工作原理
通常,人們認為,當您涉足主要和次要架構時,只有一種方法可以設置備份和復制,但 PostgreSQL 部署遵循以下三種方法之一:
- 卷級複製,在存儲層從主節點複製到輔助節點,然後將其備份到 Blob/S3 存儲。
- PostgreSQL 流複製將數據從主節點複製到輔助節點,然後將其備份到 blob/S3 存儲。
- 從主節點到 S3進行增量備份,同時從 S3 重建新的輔助節點。 當輔助節點在主節點附近時,您可以從主節點開始流式傳輸。
方法 1:流式傳輸
在所有服務器上安裝 PostgreSQL 後,可以無縫設置 PostgreSQL 流複製也稱為 WAL 複製。 這種複制方法基於將 WAL 文件從主數據庫移動到目標數據庫。
您可以使用主從配置來實現 PostgreSQL 流式複制。 主服務器是處理主數據庫及其所有操作的主要實例。 輔助服務器充當補充實例,並在其自身上執行對主數據庫所做的所有更改,並在此過程中生成相同的副本。 主服務器是讀/寫服務器,而輔助服務器只是只讀的。
對於這種方法,您需要同時配置主節點和備用節點。 以下部分將闡明輕鬆配置它們所涉及的步驟。
配置主節點
您可以通過執行以下步驟來配置主節點以進行流式複制:
第 1 步:初始化數據庫
要初始化數據庫,您可以利用initidb utility命令。 接下來,您可以使用以下命令創建具有復制權限的新用戶:
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';用戶必須為給定的查詢提供密碼和用戶名。 replication 關鍵字用於為用戶提供所需的權限。 示例查詢如下所示:
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'步驟 2:配置流媒體屬性
接下來,您可以使用 PostgreSQL 配置文件 ( postgresql.conf ) 配置流屬性,該文件可以修改如下:
wal_level = logical wal_log_hints = on max_wal_senders = 8 max_wal_size = 1GB hot_standby = on以下是上一個片段中使用的參數的一些背景知識:
-
wal_log_hints:當備用服務器與主服務器不同步時,pg_rewind功能需要此參數。 -
wal_level:您可以使用此參數來啟用 PostgreSQL 流式複制,可能的值包括minimal、replica或logical。 -
max_wal_size:這可用於指定可以保留在日誌文件中的 WAL 文件的大小。 -
hot_standby:當它設置為 ON 時,您可以利用此參數與輔助節點建立讀取連接。 -
max_wal_senders:您可以使用max_wal_senders指定可以與備用服務器建立的最大並發連接數。
第 3 步:創建新條目
修改 postgresql.conf 文件中的參數後, pg_hba.conf文件中的新復制條目可以允許服務器相互建立連接以進行複制。
您通常可以在 PostgreSQL 的數據目錄中找到該文件。 您可以使用以下代碼片段:
host replication rep_user IPaddress md5 執行代碼片段後,主服務器允許名為rep_user的用戶連接並充當備用服務器,方法是使用指定的 IP 進行複制。 例如:
host replication rep_user 192.168.0.22/32 md5配置備用節點
要為流複製配置備用節點,請執行以下步驟:
步驟 1:備份主節點
要配置備用節點,請利用pg_basebackup實用程序生成主節點的備份。 這將作為備用節點的起點。 您可以使用以下語法使用此實用程序:
pg_basebackp -D -h -X stream -c fast -U rep_user -W上述語法中使用的參數如下:
-
-h:您可以使用它來提及主要主機。 -
-D:此參數表示您當前正在處理的目錄。 -
-C:您可以使用它來設置檢查點。 -
-X:此參數可用於包含必要的事務日誌文件。 -
-W:您可以使用此參數在鏈接到數據庫之前提示用戶輸入密碼。
步驟 2:設置複製配置文件
接下來,您需要檢查復製配置文件是否存在。 如果沒有,您可以將復製配置文件生成為 recovery.conf。
您應該在 PostgreSQL 安裝的數據目錄中創建此文件。 您可以使用pg_basebackup實用程序中的-R選項自動生成它。
recovery.conf文件應包含以下命令:
待機模式 = '開'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name=”host_name”'
recovery_target_timeline = '最新的'
上述命令中使用的參數如下:
-
primary_conninfo:您可以使用它通過利用連接字符串在主服務器和輔助服務器之間建立連接。 -
standby_mode:此參數可以使主服務器在打開時作為備用服務器啟動。 -
recovery_target_timeline:您可以使用它來設置恢復時間。
要建立連接,您需要提供用戶名、IP 地址和密碼作為 primary_conninfo 參數的值。 例如:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'步驟 3:重新啟動輔助服務器
最後,您可以重新啟動輔助服務器以完成配置過程。
但是,流式複制帶來了一些挑戰,例如:
- 各種 PostgreSQL 客戶端(用不同的編程語言編寫)與單個端點進行通信。 當主節點出現故障時,這些客戶端將繼續重試相同的 DNS 或 IP 名稱。 這使得故障轉移對應用程序可見。
- PostgreSQL 複製沒有內置故障轉移和監控功能。 當主節點發生故障時,您需要將輔助節點提升為新的主節點。 此提升需要以客戶端僅寫入一個主節點的方式執行,並且他們不會觀察到數據不一致。
- PostgreSQL 複製它的整個狀態。 當你需要開發一個新的從節點時,從節點需要從主節點回顧整個狀態變化的歷史,這是資源密集型的,並且使得消除頭部節點並創建新節點的成本很高。
方法二:複製塊設備
複製塊設備方法依賴於磁盤鏡像(也稱為卷複製)。 在這種方法中,更改被寫入持久卷,該卷被同步鏡像到另一個卷。
這種方法的額外好處是它在雲環境中與所有關係數據庫(包括 PostgreSQL、MySQL 和 SQL Server 等)的兼容性和數據持久性。
但是,PostgreSQL 複製的磁盤鏡像方法需要您複製 WAL 日誌和表數據。 由於現在對數據庫的每次寫入都需要通過網絡同步進行,因此您不能丟失一個字節,因為這可能會使您的數據庫處於損壞狀態。
這種方法通常使用 Azure PostgreSQL 和 Amazon RDS。
方法三:WAL
WAL 由段文件組成(默認為 16 MB)。 每個段都有一個或多個記錄。 日誌序列記錄 (LSN) 是指向 WAL 中記錄的指針,讓您知道記錄在日誌文件中保存的位置/位置。
備用服務器利用 WAL 段(在 PostgreSQL 術語中也稱為 XLOGS)來不斷複製其主服務器的更改。 您可以使用預寫日誌記錄來授予 DBMS 中的持久性和原子性,方法是在將字節數組數據塊(每個都有一個唯一的 LSN)序列化到穩定存儲之前,然後再將它們應用於數據庫。
將突變應用於數據庫可能會導致各種文件系統操作。 出現的一個相關問題是數據庫如何在文件系統更新過程中由於斷電而導致服務器故障的情況下確保原子性。 當數據庫啟動時,它會開始一個啟動或重放過程,該過程可以讀取可用的 WAL 段並將它們與存儲在每個數據頁上的 LSN 進行比較(每個數據頁都標記有影響該頁的最新 WAL 記錄的 LSN)。
基於日誌傳送的複制(塊級)
流式複制改進了日誌傳送過程。 與等待 WAL 切換相反,記錄在創建時發送,從而減少複製延遲。
流式複制還勝過日誌傳送,因為備用服務器通過利用複制協議通過網絡與主服務器鏈接。 然後,主服務器可以直接通過此連接發送 WAL 記錄,而無需依賴最終用戶提供的腳本。
基於日誌傳送的複制(文件級)
日誌傳送定義為將日誌文件複製到另一個 PostgreSQL 服務器以通過重放 WAL 文件來生成另一個備用服務器。 該服務器被配置為在恢復模式下工作,其唯一目的是應用任何出現的新 WAL 文件。
然後,此輔助服務器將成為主 PostgreSQL 服務器的熱備份。 它還可以配置為只讀副本,它可以提供只讀查詢,也稱為熱備用。
連續 WAL 歸檔
在創建 WAL 文件時將它們複製到pg_wal子目錄以外的任何位置以歸檔它們稱為 WAL 歸檔。 每次創建 WAL 文件時,PostgreSQL 都會調用用戶提供的腳本進行歸檔。
該腳本可以利用scp命令將文件複製到一個或多個位置,例如 NFS 掛載。 歸檔後,可以利用 WAL 段文件在任何給定時間點恢復數據庫。
其他基於日誌的配置包括:
- 同步複製:在每個同步複製事務被提交之前,主服務器等待直到備用服務器確認他們獲得了數據。 這種配置的好處是不會因為並行寫入過程而引起任何衝突。
- 同步多主複製:在這裡,每個服務器都可以接受寫入請求,並且在每個事務提交之前,將修改的數據從原始服務器傳輸到每個其他服務器。 它利用 2PC 協議並遵守全有或全無規則。
WAL 流協議詳細信息
在備用服務器上運行的稱為 WAL 接收器的進程利用recovery.conf的primary_conninfo參數中提供的連接詳細信息,並通過利用 TCP/IP 連接連接到主服務器。
要開始流式複制,前端可以在啟動消息中發送複製參數。 布爾值 true、yes、1 或 ON 讓後端知道它需要進入物理複製 walsender 模式。
WAL sender 是另一個在主服務器上運行的進程,負責在 WAL 記錄生成時將其發送到備用服務器。 WAL 接收器將 WAL 記錄保存在 WAL 中,就好像它們是由本地連接的客戶端的客戶端活動創建的一樣。
一旦 WAL 記錄到達 WAL 段文件,備用服務器會不斷地重播 WAL,以便主服務器和備用服務器是最新的。
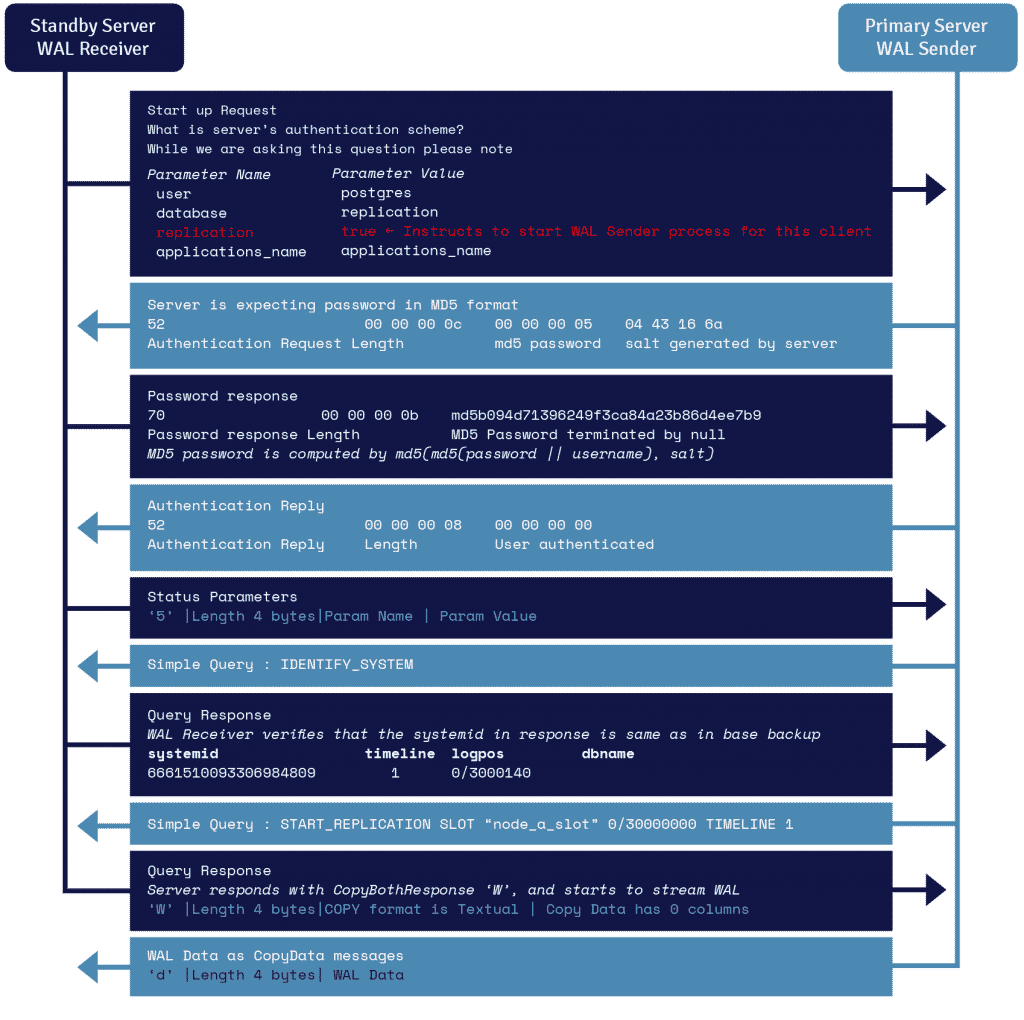
PostgreSQL 複製的元素
在本節中,您將深入了解PostgreSQL複製的常用模型(單主和多主複製)、類型(物理和邏輯複製)和模式(同步和異步)。
PostgreSQL 數據庫複製的模型
可擴展性是指在現有節點上增加更多的資源/硬件,以增強數據庫存儲和處理更多數據的能力,可以橫向和縱向實現。 PostgreSQL 複製是水平可伸縮性的一個例子,它比垂直可伸縮性更難實現。 我們主要通過單主複製(SMR)和多主複製(MMR)來實現橫向擴展。

單主複製允許僅在單個節點上修改數據,並且這些修改被複製到一個或多個節點。 副本數據庫中的複製表不允許接受任何更改,除了來自主服務器的更改。 即使他們這樣做了,更改也不會復制回主服務器。
大多數時候,SMR 對應用程序來說已經足夠了,因為它的配置和管理不太複雜,而且沒有衝突的機會。 單主複製也是單向的,因為複制數據主要沿一個方向流動,從主數據庫到副本數據庫。
在某些情況下,僅 SMR 可能還不夠,您可能需要實施 MMR。 MMR 允許多個節點充當主節點。 對多個指定主數據庫中表行的更改將復製到每個其他主數據庫中的對應表。 在這個模型中,經常使用衝突解決方案來避免重複主鍵等問題。
使用 MMR 有幾個優點,即:
- 在主機故障的情況下,其他主機仍然可以提供更新和插入服務。
- 主節點分散在幾個不同的位置,因此所有主節點發生故障的機會非常小。
- 能夠使用主要數據庫的廣域網 (WAN),該數據庫在地理位置上可以靠近客戶端組,同時保持整個網絡的數據一致性。
然而,實施 MMR 的缺點是複雜性和解決衝突的難度。
一些分支和應用程序提供了 MMR 解決方案,因為 PostgreSQL 本身並不支持它。 這些解決方案可能是開源的、免費的或付費的。 一種這樣的擴展是雙向複製 (BDR),它是異步的並且基於 PostgreSQL 邏輯解碼功能。
由於 BDR 應用程序在其他節點上重放事務,如果正在應用的事務與在接收節點上提交的事務之間存在衝突,則重放操作可能會失敗。
PostgreSQL 複製的類型
PostgreSQL 複製有兩種類型:邏輯複製和物理複製。
一個簡單的邏輯操作“initdb”將執行為集群創建基本目錄的物理操作。 同樣,一個簡單的邏輯操作“CREATE DATABASE”將執行在基本目錄中創建子目錄的物理操作。
物理複製通常處理文件和目錄。 它不知道這些文件和目錄代表什麼。 這些方法用於維護單個集群的全部數據的完整副本,通常在另一台機器上,並且在文件系統級別或磁盤級別完成,並使用確切的塊地址。
邏輯複製是一種複制數據實體及其修改的方法,基於它們的複制身份(通常是主鍵)。 與物理複製不同,它處理數據庫、表和 DML 操作,並在數據庫集群級別完成。 它使用發布和訂閱模型,其中一個或多個訂閱者訂閱發布者節點上的一個或多個發布。
複製過程首先對發布者數據庫上的數據進行快照,然後將其複製到訂閱者。 訂閱者從他們訂閱的發布中提取數據,並且可以稍後重新發布數據以允許級聯複製或更複雜的配置。 訂閱者以與發布者相同的順序應用數據,從而保證單個訂閱中發布的事務一致性,也稱為事務複製。
邏輯複製的典型用例是:
- 將單個數據庫(或數據庫子集)中的增量更改發送給訂閱者。
- 在多個數據庫之間共享數據庫的一個子集。
- 當單個更改到達訂閱者時觸發它們的觸發。
- 將多個數據庫合併為一個。
- 向不同的用戶組提供對複制數據的訪問。
訂閱者數據庫的行為方式與任何其他 PostgreSQL 實例相同,並且可以通過定義其發布來用作其他數據庫的發布者。
當訂閱者被應用程序視為只讀時,單個訂閱不會發生衝突。 另一方面,如果應用程序或其他訂閱者對同一組表進行了其他寫入,則可能會出現衝突。
PostgreSQL 同時支持這兩種機制。 邏輯複製允許對數據複製和安全性進行細粒度控制。
複製模式
PostgreSQL複製主要有兩種模式:同步和異步。 同步複製允許數據同時寫入主服務器和從服務器,而異步複製確保數據先寫入主機,然後再复製到從服務器。
在同步模式複制中,僅當這些更改已復製到所有副本時,主數據庫上的事務才被視為完成。 副本服務器必須始終可用,以便在主服務器上完成事務。 同步複製模式用於具有即時故障轉移要求的高端事務環境。
在異步模式下,當僅在主服務器上完成更改時,可以聲明主服務器上的事務完成。 然後這些更改會在稍後的時間複製到副本中。 副本服務器可以在一定時間內保持不同步,稱為複制滯後。 在崩潰的情況下,可能會發生數據丟失,但異步複製提供的開銷很小,因此在大多數情況下是可以接受的(它不會使主機負擔過重)。 從主數據庫故障轉移到輔助數據庫的時間比同步複製要長。
如何設置 PostgreSQL 複製
在本節中,我們將演示如何在 Linux 操作系統上設置 PostgreSQL 複製過程。 在本例中,我們將使用 Ubuntu 18.04 LTS 和 PostgreSQL 10。
讓我們深入挖掘!
安裝
您將首先通過以下步驟在 Linux 上安裝 PostgreSQL:
- 首先,您必須通過在終端中鍵入以下命令來導入 PostgreSQL 簽名密鑰:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - 然後,通過在終端中鍵入以下命令來添加 PostgreSQL 存儲庫:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - 通過在終端中鍵入以下命令來更新存儲庫索引:
sudo apt-get update - 使用 apt 命令安裝 PostgreSQL 包:
sudo apt-get install -y postgresql-10 - 最後,使用以下命令設置 PostgreSQL 用戶的密碼:
sudo passwd postgres
在開始 PostgreSQL 複製過程之前,主服務器和輔助服務器都必須安裝 PostgreSQL。
為兩台服務器設置 PostgreSQL 後,您可以繼續進行主服務器和輔助服務器的複制設置。
在主服務器中設置複製
在主服務器和輔助服務器上安裝 PostgreSQL 後執行這些步驟。
- 首先,使用以下命令登錄 PostgreSQL 數據庫:
su - postgres - 使用以下命令創建複製用戶:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - 在 Ubuntu 中使用任何 nano 應用程序編輯pg_hba.cnf並添加以下配置:文件編輯命令
nano /etc/postgresql/10/main/pg_hba.conf要配置文件,請使用以下命令:
host replication replication MasterIP/24 md5 - 打開並編輯 postgresql.conf 並將以下配置放入主服務器:
nano /etc/postgresql/10/main/postgresql.conf使用以下配置設置:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - 最後,在主主服務器中重新啟動 PostgreSQL:
systemctl restart postgresql您現在已經完成了主服務器中的設置。
在輔助服務器中設置複製
按照以下步驟在輔助服務器中設置複製:
- 使用以下命令登錄 PostgreSQL RDMS:
su - postgres - 停止 PostgreSQL 服務的工作以使我們能夠使用以下命令對其進行處理:
systemctl stop postgresql - 使用此命令編輯pg_hba.conf文件並添加以下配置:
編輯命令nano /etc/postgresql/10/main/pg_hba.conf配置
host replication replication MasterIP/24 md5 - 在輔助服務器中打開並編輯postgresql.conf並放置以下配置或取消註釋(如果已註釋):編輯命令
配置nano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP 是從服務器的地址
- 訪問輔助服務器中的 PostgreSQL 數據目錄並刪除所有內容:
cd /var/lib/postgresql/10/mainrm -rfv * - 將 PostgreSQL 主服務器數據目錄文件複製到 PostgreSQL 輔助服務器數據目錄,並在輔助服務器中寫入此命令:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - 輸入主服務器 PostgreSQL 密碼並回車。 接下來,為恢復配置添加以下命令:編輯命令
nano /var/lib/postgresql/10/main/recovery.conf配置
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'這裡,YOUR_PASSWORD 是 PostgreSQL 創建的主服務器中復制用戶的密碼
- 設置密碼後,您必須重新啟動輔助 PostgreSQL 數據庫,因為它已停止:
systemctl start postgresql測試您的設置
現在我們已經執行了這些步驟,讓我們測試複製過程並觀察輔助服務器數據庫。 為此,我們在主服務器中創建一個表,並觀察它是否反映在輔助服務器上。
讓我們開始吧。
- 由於我們在主服務器中創建表,您需要登錄到主服務器:
su - postgres psql - 現在我們創建一個名為“testtable”的簡單表,並通過在終端中運行以下 PostgreSQL 查詢將數據插入到表中:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - 登錄從服務器觀察從服務器PostgreSQL數據庫:
su - postgres psql - 現在,我們檢查表 'testtable' 是否存在,並且可以通過在終端中運行以下 PostgreSQL 查詢來返回數據。 該命令實質上顯示了整個表格。
select * from testtable;
這是測試表的輸出:
| websites | ------------------- | section.com | | google.com | | github.com | --------------------您應該能夠觀察到與主服務器中的數據相同的數據。
如果您看到以上內容,那麼您已經成功進行了複製過程!
PostgreSQL 手動故障轉移步驟是什麼?
讓我們回顧一下 PostgreSQL 手動故障轉移的步驟:
- 使主服務器崩潰。
- 通過在備用服務器上運行以下命令來提升備用服務器:
./pg_ctl promote -D ../sb_data/ server promoting - 連接到提升的備用服務器並插入一行:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values (4,'Four');
如果插入工作正常,則備用服務器(以前是只讀服務器)已升級為新的主服務器。
如何在 PostgreSQL 中自動進行故障轉移
設置自動故障轉移很容易。
您將需要 EDB PostgreSQL 故障轉移管理器 (EFM)。 在每個主節點和備用節點上下載並安裝 EFM 後,您可以創建一個 EFM 集群,該集群由一個主節點、一個或多個備用節點以及一個在發生故障時確認斷言的可選見證節點組成。
EFM 持續監控系統運行狀況並根據系統事件發送電子郵件警報。 當發生故障時,它會自動切換到最新的備用服務器並重新配置所有其他備用服務器以識別新的主節點。
它還重新配置負載平衡器(例如 pgPool)並防止“裂腦”(當兩個節點都認為它們是主節點時)發生。
概括
由於數據量大,可伸縮性和安全性已成為數據庫管理中最重要的兩個標準,尤其是在事務環境中。 雖然我們可以通過向現有節點添加更多資源/硬件來縱向提高可擴展性,但這並不總是可行的,通常是由於添加新硬件的成本或限制。
因此,需要水平可擴展性,這意味著向現有網絡節點添加更多節點,而不是增強現有節點的功能。 這就是 PostgreSQL 複製出現的地方。
在本文中,我們討論了 PostgreSQL 複製的類型、優勢、複製模式、安裝以及 SMR 和 MMR 之間的 PostgreSQL 故障轉移。 現在讓我們聽聽你的意見。
你通常實現哪一個? 哪個數據庫功能對您來說最重要,為什麼? 我們很樂意閱讀您的想法! 在下面的評論部分分享它們。