
誤導性統計數據可能很危險(一些示例)
已發表: 2022-12-06人們依靠統計數據來獲取重要信息。 在商業世界中,統計數據可用於跟踪趨勢和最大限度地提高生產力。 但有時統計數據可能會以誤導的方式呈現。 例如,2007 年英國廣告標準局 (ADA) 收到了關於高露潔廣告的投訴。
該廣告著名地聲稱 80% 的牙醫推薦使用高露潔牙膏。 ADA 收到的投訴稱,這違反了英國的廣告規則。 在調查此事後,ADA 發現該廣告使用了誤導性統計數據。
誠然,很多牙醫都推薦高露潔牙膏。 但並非所有人都將高露潔列為第一推薦。 大多數牙醫也推薦其他種類的牙膏,而高露潔通常會在稍後的某個時候出現。
這只是如何使用誤導性統計數據的一個例子。 人們在生活的許多不同領域都會遇到誤導性統計示例。 你可以在新聞、廣告、政治甚至科學中找到例子。
這篇文章將幫助您學會識別誤導性統計數據和其他誤導性數據。 它將討論這些數據如何誤導人們。 您還將了解在做出關鍵決策時何時以及如何使用數據。
什麼是誤導性統計數據?
統計數據是收集數字數據、仔細分析然後進行解釋的結果。 如果您正在處理大量數據,那麼擁有統計數據尤其有用,但任何可以衡量的東西都可以成為統計數據。 統計數據通常可以揭示很多關於世界及其運作方式的信息。
然而,當該信息被濫用時,即使是偶然地,它也會變成誤導性統計數據。 誤導性統計數據為人們提供了欺騙他們而不是告知他們的虛假信息。
當人們斷章取義統計數據時,它就失去了價值,並可能導致人們得出錯誤的結論。 “誤導性統計”一詞描述了任何錯誤地表示數據的統計方法。 不管是有意還是無意,它仍然會被視為誤導性統計數據。
在收集統計數據時,需要牢記三個原則要點。 在這些時間點中的任何一個時間點都可能發生數據分析問題。
- 收集:在收集數據時
- 處理:分析數據及其含義時
- 演示:與他人分享您的發現時
樣本量小
樣本量調查是創建誤導性統計數據的一個例子。 對樣本量的受眾進行的調查或研究通常會產生誤導性的結果,以至於它們無法使用。
為了說明這一點,一項調查向 20 人詢問了一個是或否的問題。 19 人對調查的回答是肯定的。 所以結果表明 95% 的人會回答“是”。 但這不是一個好的調查,因為信息有限。
該統計數據沒有實際價值。 現在,如果您問 1,000 個人同樣的問題,而 950 人回答“是”,那麼這是一個更可靠的統計數據,表明 95% 的人會回答“是”。
要進行可靠的樣本量研究,您需要考慮三件事:
- 一:你在問什麼樣的問題?
- 二:您要查找的統計數據的意義是什麼?
- 第三:你會使用什麼統計技術?
要獲得可靠的結果,任何樣本量定量分析都應至少包括 200 人。
加載的問題

從中立來源尋找數據很重要。 否則,信息是傾斜的。 加載問題使用有爭議或不合理的假設來操縱響應。 這方面的一個例子是問一個以“你喜歡什麼”開頭的問題。 這個問題在收集積極反饋方面做得很好,但沒有教給你任何有用的東西。 它沒有為人們提供誠實的想法和意見的機會。
考慮以下兩個問題的區別:
- 您是否支持意味著更高稅收的稅制改革?
- 您是否支持有利於社會再分配的稅制改革?
這個問題本質上與同一主題有關,但是每個問題的結果都會大不相同。 民意調查應以公正、無偏見的方式進行。 您希望獲得人們的真實意見和人們想法的全貌。 為此,您的問題不應暗示答案,也不應激起情緒反應。
引用誤導性的“平均值”
有些人使用“平均”一詞來掩蓋真相或撒謊以使信息看起來更好。
如果有人想讓數字看起來比實際更大或更好,則此技術特別有用。 例如,一所想要吸引新生的大學可能會為其學校的畢業生提供“平均”年薪。 但真正拿高薪的學生,可能只是屈指可數。 但他們的薪水使所有學生的平均收入更高。 對於整個平均值來說,這看起來更好。
平均值對於隱藏不平等也很有用。 再舉一個例子,假設一家公司每年向其 90 名員工支付 20,000 美元。 但他們的老闆每年收到 20 萬美元。 如果將老闆的工資和員工的工資合併,公司每位成員的平均收入為 21,978 美元。
在紙面上,這看起來很棒。 但這個數字並不能說明全部情況,因為其中一名員工(老闆)的收入遠遠高於其他員工。 所以這些類型的結果算作誤導性統計數據。
累積與年度數據
累積數據隨時間跟踪圖表上的信息。 每次將數據輸入圖表時,圖表都會上升。
年度數據顯示特定年份的所有數據。
每年的跟踪信息提供了更真實的總體趨勢圖。
累積圖的一個示例是 Worldometer COVID-19 圖。 在 COVID-19 大流行期間,出現了許多累積圖的例子。 它們通常反映特定地區 COVID 病例的累計數量。
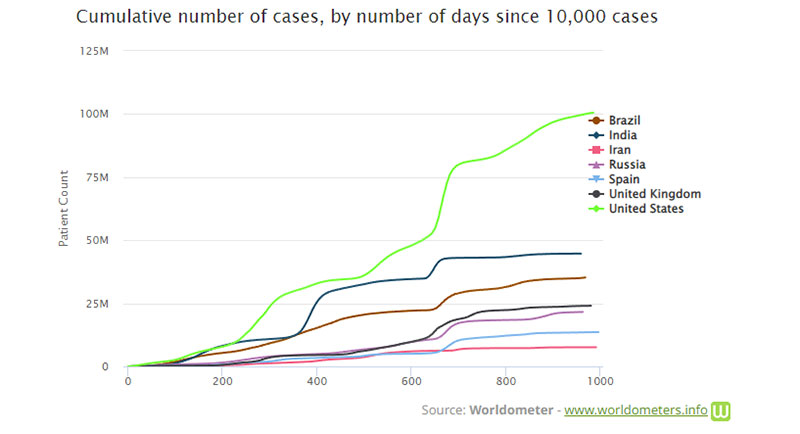
一些公司使用這樣的圖表來使銷售額看起來比實際情況更大。 2013 年,蘋果公司首席執行官蒂姆庫克因使用僅顯示 iPhone 累計銷量的演示文稿而受到批評。 當時許多人認為他故意這樣做是為了掩蓋 iPhone 銷量下降的事實。
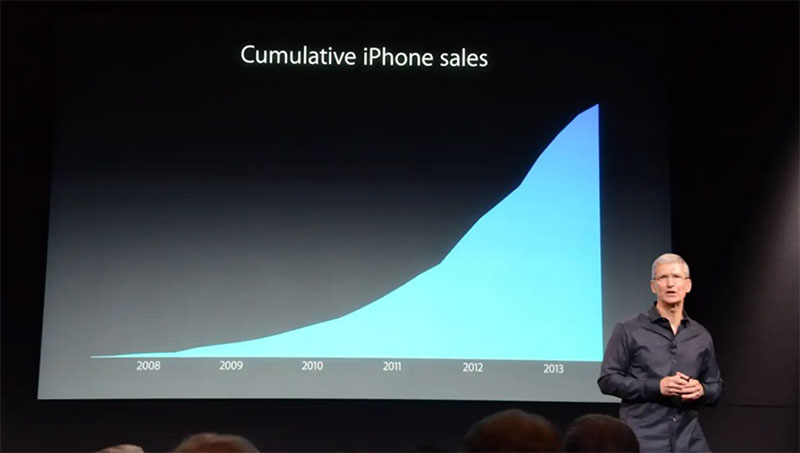
這並不是說所有累積數據都是錯誤的或錯誤的。 事實上,它可用於跟踪變化或增長以及各種總數。 但重要的是要注意數據的變化。 然後更深入地了解導致它們的原因,而不是依賴圖表來告訴您一切。
過度概括和有偏差的樣本
當某人認為對一個人適用的東西對其他所有人都適用時,就會出現過度概括。 通常,當某人對特定人群進行研究時,就會出現這種謬誤。 然後他們假設結果將適用於另一組無關的人。
不具代表性的樣本或有偏差的樣本是不能準確代表一般人群的調查。
樣本偏差的一個例子發生在 1936 年的美國總統選舉期間。
當時流行的雜誌《文學文摘》進行了一項調查,以預測誰會贏得選舉。 結果預測阿爾弗雷德蘭登將以壓倒性優勢獲勝。
該雜誌以準確預測選舉結果而聞名。 然而今年,他們完全錯了。 富蘭克林·羅斯福以幾乎是對手兩倍的票數獲勝。
更多的研究表明,有兩個變量開始發揮作用,導致結果出現偏差。
首先,調查中的大多數參與者都是在電話簿和自動註冊列表中找到的人。 因此,該調查僅針對具有一定社會經濟地位的人進行。
第二個因素是那些投票給蘭登的人比那些選擇投票給羅斯福的人更願意回應調查。 所以結果反映了這種偏見。
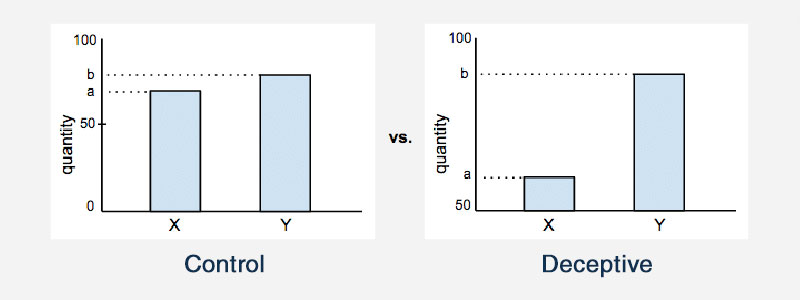
截斷軸
截斷圖表上的軸是誤導性統計數據的另一個例子。 在大多數統計圖中,x 軸和 y 軸大概都從零開始。 但是截斷軸意味著圖形實際上以其他值開始軸。 這會影響圖表的外觀,並影響人們得出的結論。
這是一個說明這一點的例子:
這方面的另一個例子最近發生在 2021 年 9 月。在福克斯新聞的一次廣播中,主播使用了一張圖表顯示自稱是基督徒的美國人人數。 該圖表顯示,在過去 10 年中,認定為基督徒的美國人人數急劇下降。
在下圖中,我們看到 2009 年 77% 的美國人被認定為基督徒。
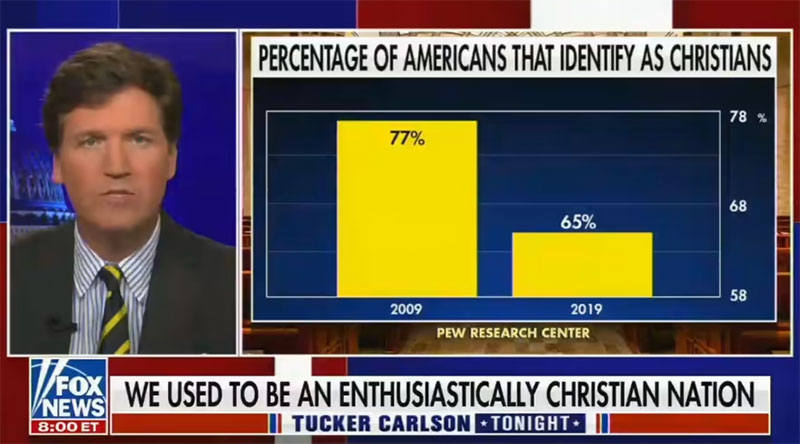
到 2019 年,這一數字下降到 65%。 實際上,這並不是一個巨大的下降。 但此圖表上的軸從 58% 開始,到 78% 停止。 因此,從 2009 年到 2019 年 12% 的下降看起來比實際情況要劇烈得多。
因果關係
可以很容易地假設兩個看似相連的數據點之間存在聯繫。 然而,據說相關性並不意味著因果關係。 為什麼呢?

該圖說明了為什麼相關性與因果關係不同。
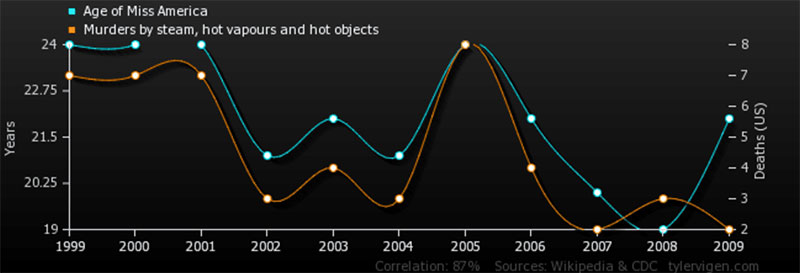
研究人員經常面臨發現新的有用數據的巨大壓力。 因此,倉促行事和過早下結論的誘惑總是存在的。 這就是為什麼在每種情況下尋找實際因果關係都很重要。
使用百分比隱藏數字和計算
百分比可以隱藏確切的數字,並使結果看起來比實際情況更有信譽和更可靠。
例如,如果三分之二的人喜歡某種清潔產品,則可以說 66.667% 的人喜歡該產品。 這使數字看起來更正式,尤其是包含小數點後的數字。
以下是小數和百分比掩蓋真相的其他幾種方式:
- 隱藏原始數據和小樣本量。 百分比掩蓋了原始數字的絕對值。 這使得它們對於想要隱藏不討人喜歡的數字或小樣本量結果的人很有用。
- 使用不同的基地。 因為百分比不提供它們所基於的原始數字,所以很容易扭曲結果。 如果有人想讓一個數字看起來更好,他們可以根據不同的基數計算該數字。
在《紐約時報》發布的一篇關於工會工人的報導中,就出現過一次這種情況。 工人們一年減薪 20%,次年,《泰晤士報》報導工會工人加薪 5%。 所以聲稱他們得到了減薪的四分之一。
然而,工人們根據他們目前的工資獲得了 5% 的加薪,而不是減薪前的工資。 因此,儘管在紙面上看起來不錯,但減薪 20% 和加薪 5% 是根據不同的基數計算得出的。 這兩個數字根本沒有可比性。
櫻桃採摘/丟棄不利數據
術語“櫻桃採摘”是基於只從樹上採摘最好的果實的想法。 任何人看到這種果子一定會認為樹上所有的果子都同樣健康。 顯然,情況不一定如此。
同樣的原則也適用於氣候變化。 許多圖表將其數據框限制為僅顯示 2000 年至 2013 年的氣候變化。
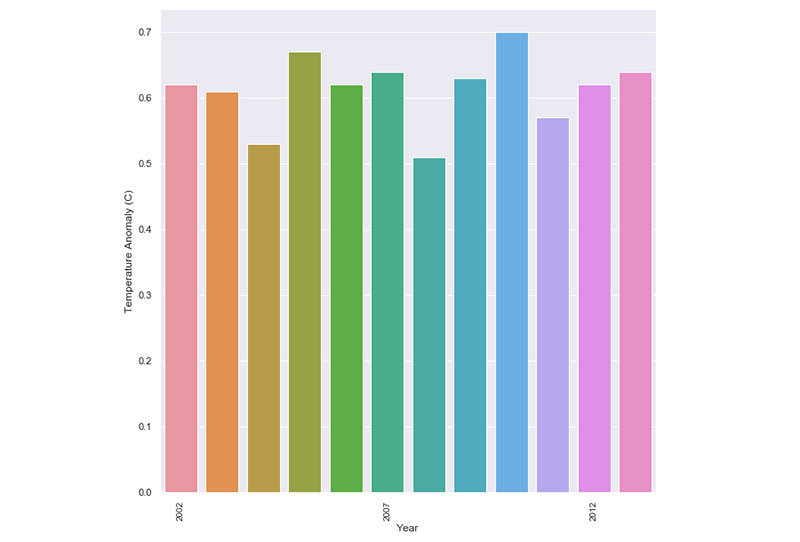
結果,溫度變化和異常似乎是一致的,變化不大。 但是,當您退後一步並從大局著眼時,就會清楚變化和異常在哪裡。
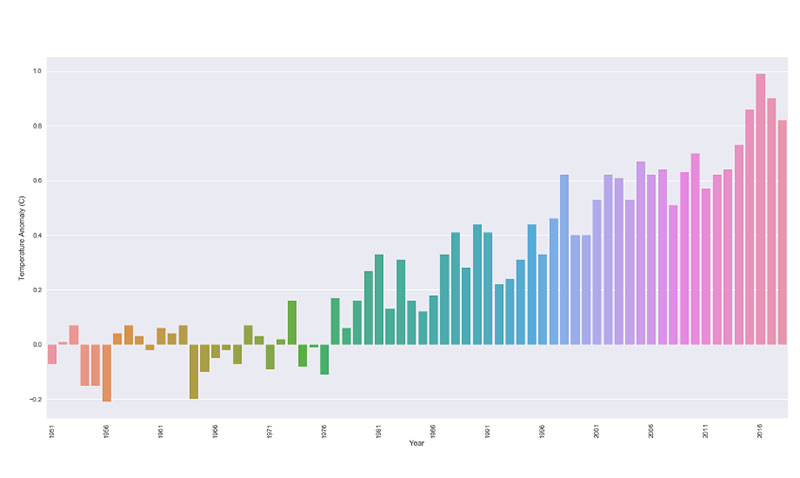
這也發生在獸醫學領域。 當獸醫被要求展示一種新試驗藥物的結果時,他們往往會展示最好的結果。 特別是如果一家製藥公司支持試驗,他們只想看到最好的結果。
你的美數據值得上線
wpDataTables可以做到這一點。 它是用於創建響應式表格和圖表的排名第一的 WordPress 插件,這是有充分理由的。
做這樣的事情真的很容易:
- 您提供表格數據
- 配置和自定義它
- 在帖子或頁面中發布
它不僅漂亮,而且實用。 您可以創建包含多達數百萬行的大型表格,或者您可以使用高級過濾器和搜索,或者您可以瘋狂地使其可編輯。
“是的,但我太喜歡 Excel 了,網站上沒有類似的東西”。 是的,有。 您可以使用 Excel 或 Google 表格中的條件格式。
我是否告訴過您也可以用您的數據創建圖表? 而這只是一小部分。 還有許多其他功能適合您。
數據釣魚
數據釣魚,也稱為數據挖掘,是對大量數據的分析,目的是找到相關性。 然而,正如本文前面所討論的,相關性並不意味著因果關係。 堅持認為這只會導致誤導性統計數據。
每天都能看到行業領域數據釣魚的例子。 一周後發布了有關數據挖掘的醜聞,一周後又被一份更離譜的報告駁斥。
這種數據分析的另一個問題是人們只選擇支持他們觀點的數據而忽略其餘部分。 通過省略相互矛盾的信息,它們使結果看起來更有說服力。
混淆圖形和圖表標籤
當 COVID-19 大流行開始時,比以往任何時候都更多的人轉向病毒傳播的數據可視化。 那些從來不需要處理統計數據可視化表示的人突然被甩出了統計數據的深淵。
此外,組織經常試圖快速獲取人員信息。 有時這意味著犧牲準確的統計數據。 這導致誤導性統計數據和對數據的誤解激增。
在 COVID-19 開始傳播大約五個月後,美國佐治亞州公共衛生部發布了這張圖表:
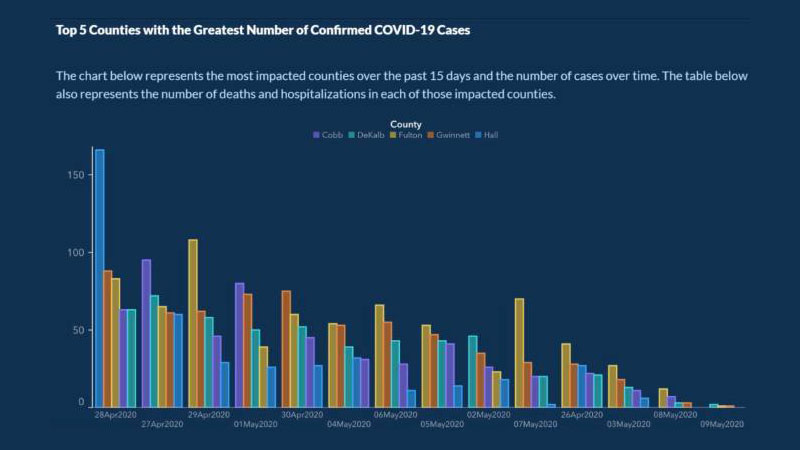
該圖表的目的是顯示過去 15 天內 COVID 病例最多的 5 個國家,以及一段時間內的病例數。
這張圖表有一些錯誤,很容易引起誤解。 例如,x 軸沒有標籤來解釋它代表案例隨時間的進展。
更糟糕的是,圖表上的日期不是按時間順序排列的。 4 月和 5 月的日期散佈在整個圖表中,以表明病例數似乎在穩步下降。 每個國家也以某種方式列出,使案件看起來正在下降。
後來,他們重新發布了具有更好組織的日期和縣的圖表:
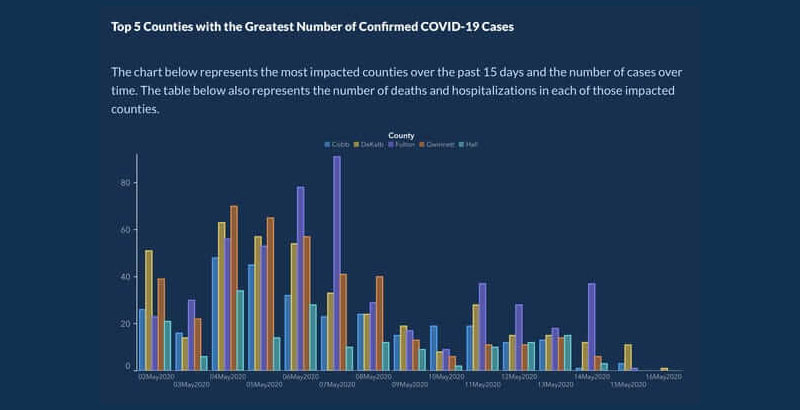
數字不准確
誤導性統計數據的另一個例子是不准確的數字。 請注意舊 Reebok 活動中的此聲明。
該廣告聲稱,與其他運動鞋相比,這雙鞋可以使人的腿筋和小腿更加堅硬 11% ,並且可以使人的臀部更加結實28% 。 人們所要做的就是穿著運動鞋走路。
這些數字表明 Reebok 對這款鞋的優點進行了廣泛研究。
事實上,這些數字完全是編造的。 該品牌因使用此類誤導性統計數據而受到處罰。 他們還必須更改聲明並刪除假號碼。
如何避免和識別統計數據的濫用
統計數據有可能非常有用。 但誤導性統計數據也有可能迷惑和欺騙人們。 統計數據賦予陳述以權威,並說服人們相信某個論點。
可靠、真實的統計數據有助於為人們提供洞察力並幫助他們做出決策。 但誤導性統計數據是危險的。 他們不是幫助人們避免陷阱和坑洞,而是引導人們進入他們想要避免的境地。
但有可能識別出誤導性的統計數據和數據。 當您遇到統計數據時,停下來問以下問題:
- 這些數據從何而來?
- 源頭是否受控? 或者它是一個樣本量的實驗?
- 還有哪些其他因素可以影響這一結果?
- 這些信息是在試圖告訴我,還是在引導我得出一個預先確定的結論?
無論您是在收集數據還是在查看他人的研究結果,請確保數據準確無誤。 這樣您就不會助長誤導性統計數據的傳播。
如果您喜歡閱讀這篇關於誤導統計的文章,您還應該閱讀以下內容:
- 您將在網上找到的最令人印象深刻的交互式數據可視化
- 您可以找到的最好的 WordPress 數據可視化工具
- 最適合您的數據可視化工具和平台