
要避免的 14 個常見 WordPress Robots.txt 錯誤
已發表: 2025-01-14Robots.txt 是一個功能強大的伺服器文件,它告訴搜尋爬蟲和其他機器人如何在您的 WordPress 網站上表現。它可以極大地影響您網站的搜尋引擎優化 (SEO),無論是積極還是消極。
因此,您應該知道這個文件是什麼以及如何使用它。否則,您可能會損壞您的網站,或至少喪失其部分潛力。
為了幫助您避免這種情況,在這篇文章中,我們將詳細介紹 robots.txt 檔案。我們將定義它是什麼、它的用途、如何找到和管理您的文件以及它應該包含什麼。之後,我們將回顧人們在使用 WordPress robots.txt 時最常見的錯誤、避免這些錯誤的方法,以及發現錯誤時如何恢復。
什麼是 WordPress robots.txt?
如前所述,robots.txt 是一個伺服器設定檔。您通常可以在伺服器的根資料夾中找到它。
當你打開它時,內容看起來像這樣:
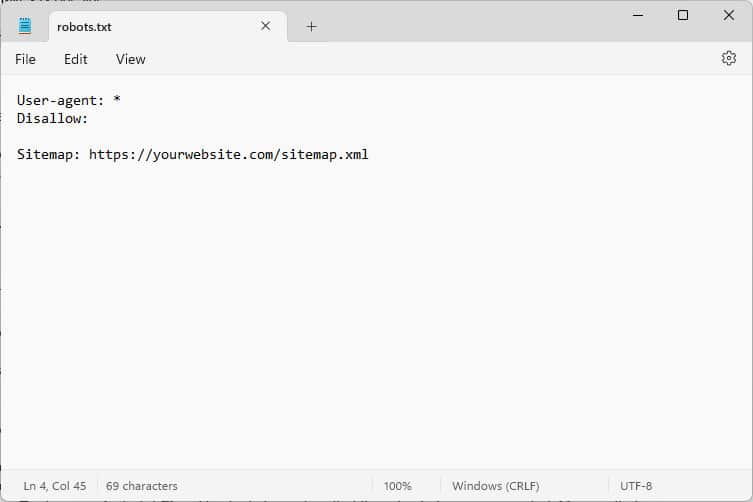
這些程式碼片段是指令,告訴訪問您網站的機器人如何在訪問您網站時進行行為,特別是訪問您網站的哪些部分,哪些部分不可以。
你問什麼機器人?
最常見的例子是來自搜尋引擎的自動爬蟲尋找網頁進行索引或更新,還有來自人工智慧模型和其他自動化工具的機器人。
您可以使用此文件給出什麼指令?
Robots.txt 基本上知道四個關鍵指令:
- 使用者代理– 定義誰,即遵循的規則適用於哪一組或單一機器人。
- 禁止– 聲明禁止使用者代理程式存取的目錄、檔案或資源。
- 允許– 可用於設定例外,例如允許存取禁止目錄中的單一資料夾或資源。
- 網站地圖– 將機器人指向網站網站地圖的 URL 位置。
只有User-agent和Disallow是文件完成其工作所必需的;其他兩個指令是可選的。例如,您可以透過以下方式阻止任何機器人造訪您的網站:
User-agent: * Disallow: /星號表示以下規則適用於所有使用者代理程式。 Disallow後的斜杠表示該站點上的所有目錄均不受限制。這是您通常在開發網站上找到的 robots.txt 文件,該文件不應被搜尋引擎索引。
但是,您也可以為單一機器人設定規則:
User-agent: Googlebot Allow: /private/resources/需要注意的是,robots.txt 不具有約束力。只有來自遵守機器人排除協議的組織的機器人才會遵守其指示。惡意機器人(例如那些在您的網站上尋找安全漏洞的機器人)可以並且將會忽略它們,您需要對它們採取額外的措施。
即使遵守該標準的組織也會忽略一些指示。我們將在下面進一步討論相關範例。
為什麼 robots.txt 很重要?
您的 WordPress 網站不強制要求有 robots.txt 檔案。沒有它您的網站也能正常運行,搜尋引擎不會因為沒有它而懲罰您。但是,包括一個可以讓您:
- 將內容排除在搜尋結果之外,例如登入頁面或某些媒體檔案。
- 防止搜尋爬蟲將爬網預算浪費在網站的不重要部分,可能會忽略您希望它們建立索引的頁面。
- 將搜尋引擎指向您的網站地圖,以便他們可以更輕鬆地探索您網站的其餘部分。
- 透過阻止浪費的機器人來保護伺服器資源。
所有這些都有助於改善您的網站,尤其是您的 SEO,這就是為什麼了解如何使用 robots.txt 很重要。
如何尋找、編輯和建立 WordPress robots.txt
如前所述,robots.txt 通常位於伺服器上網站的根資料夾中。您可以使用 FileZilla 等 FTP 用戶端存取它,並使用任何文字編輯器對其進行編輯。
如果您沒有,可以簡單地建立一個空白文字文件,將其命名為“robots.txt”,用指令填滿它,然後上傳它。
至少查看文件的另一種方法是將/robots.txt添加到您的網域,例如 https://wp-rocket.me/robots.txt。
此外,還有多種方法可以從 WordPress 後端存取該檔案。許多 SEO 外掛程式可讓您從管理介面查看並經常對其進行更改。
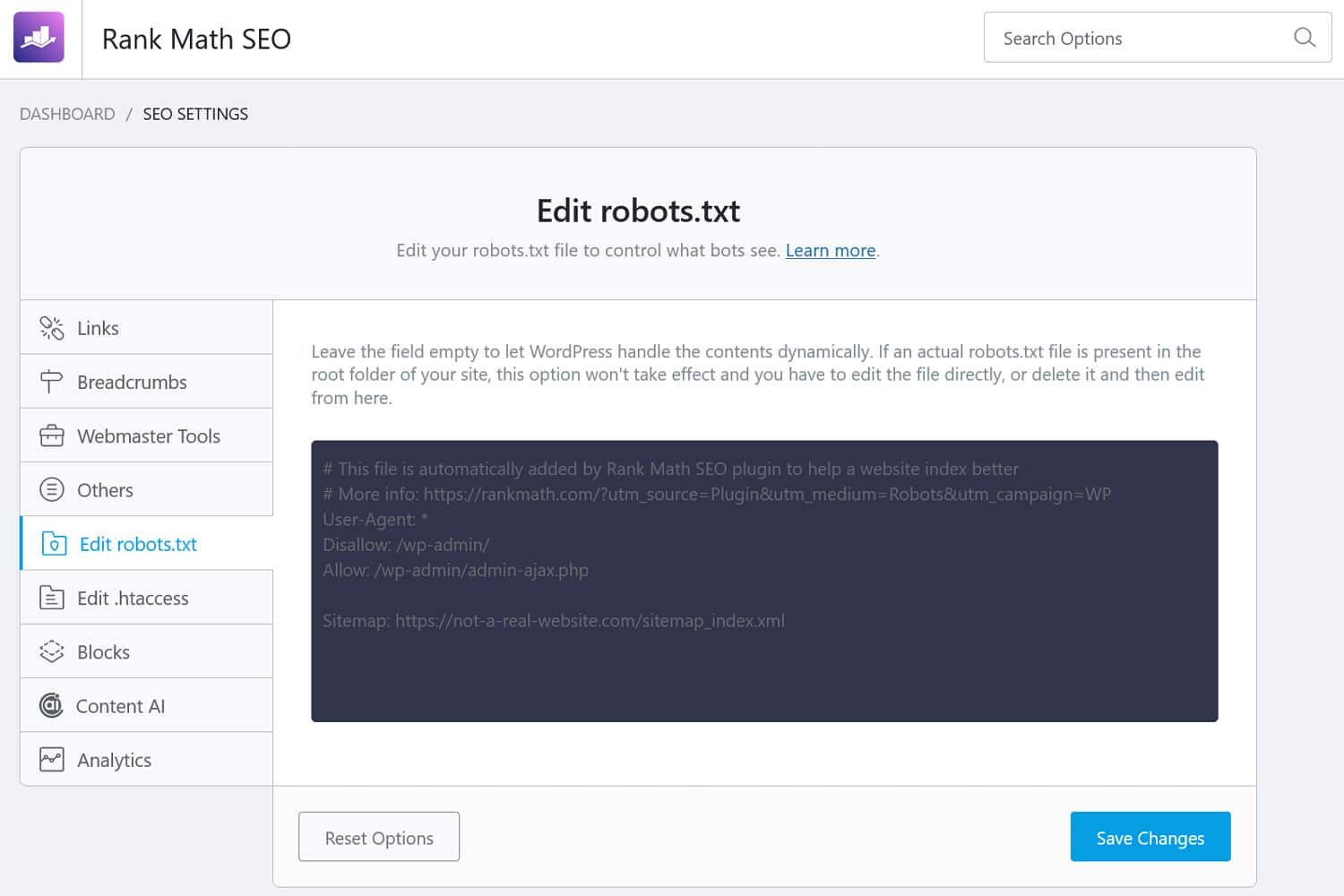
或者,您也可以使用 WPCode 等外掛程式。
一個好的 WordPress robots.txt 檔案是什麼樣的?
對於網站文件中應包含哪些指令,沒有一刀切的答案;這取決於你的設定。以下是一個對許多 WordPress 網站都有意義的範例:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://yourwebsite.com/sitemap.xml這個例子實現了幾個結果:
- 它阻止對管理區域的訪問
- 允許存取基本的管理功能
- 提供網站地圖位置
此設定在安全性、SEO 性能和高效爬行之間取得了平衡。
不要犯這 14 個 WordPress robots.txt 錯誤
如果您的目標是為自己的網站設定和最佳化 robots.txt,請務必避免以下錯誤。
1.忽略內部WordPress robots.txt
即使您網站的根目錄中沒有「實體」robots.txt 文件,WordPress 也會附帶自己的虛擬文件。如果您發現搜尋引擎沒有為您的網站編制索引,請記住這一點尤其重要。
在這種情況下,您很有可能在「設定」>「閱讀」下啟用了阻止他們這樣做的選項。
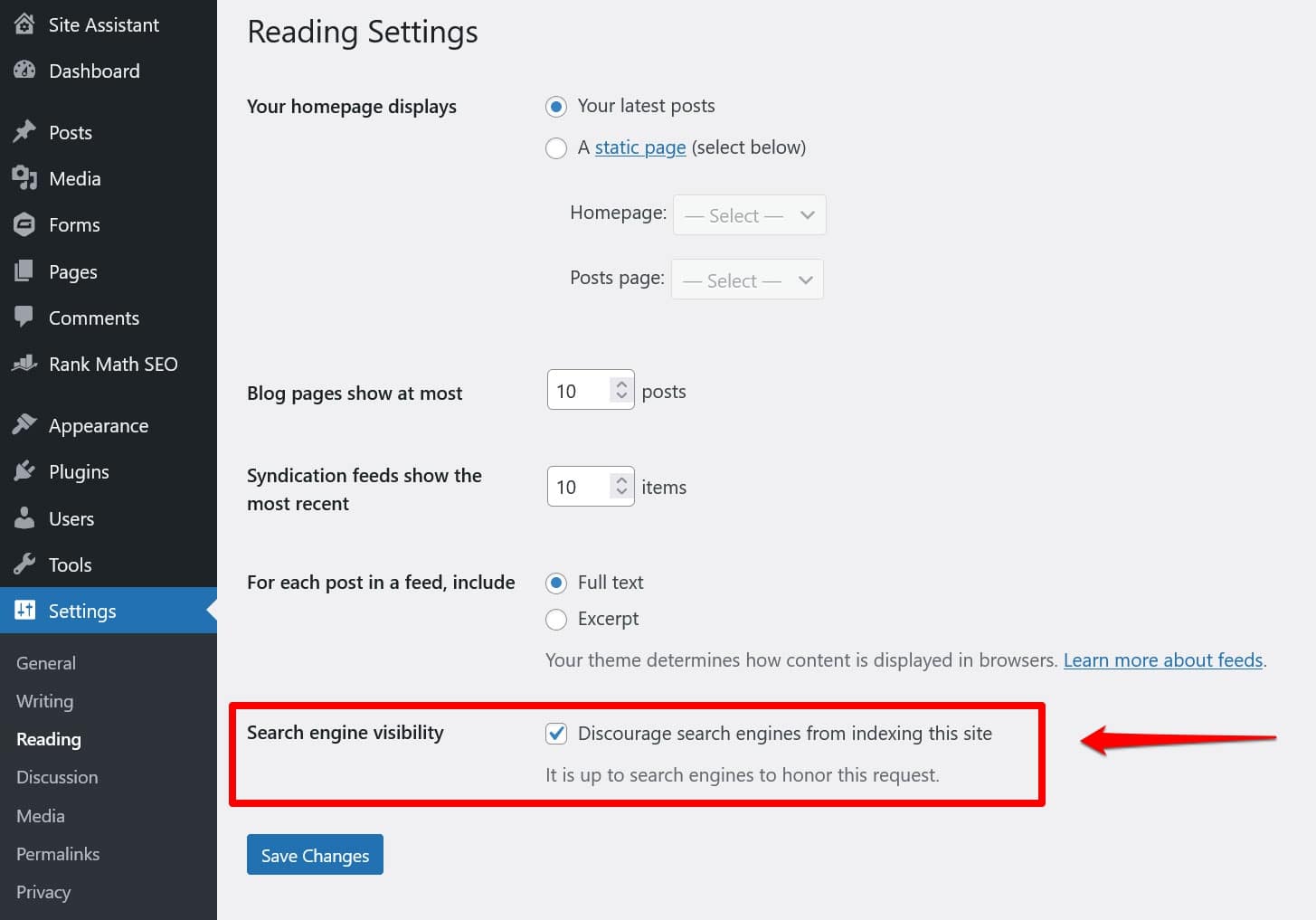
這會放置一條指令,將所有搜尋爬蟲排除在虛擬 robots.txt 中。若要停用它,請取消選取該方塊並將其保存在底部。
2. 放置位置錯誤
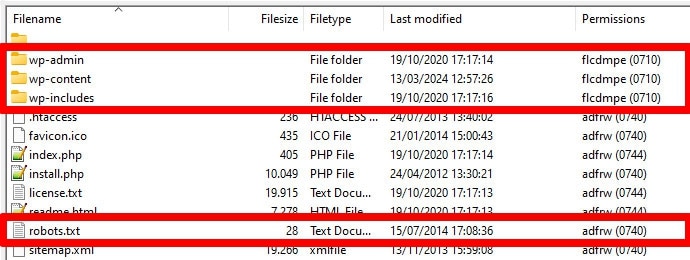
機器人(尤其是搜尋爬蟲)僅在一個位置(您網站的根目錄)尋找您的 robots.txt 檔案。如果您將其放在其他位置(例如資料夾中),他們將找不到它並忽略它。
當您透過 FTP 存取伺服器時,您的根目錄應該是您登陸的位置,除非您已將 WordPress 放置在子目錄中。如果您看到wp-admin 、 wp-content和wp-includes資料夾,那麼您來對地方了。
3. 包括過時的標記
除了上面提到的指令之外,您可能還會在舊網站的 robots.txt 檔案中找到另外兩個指令:
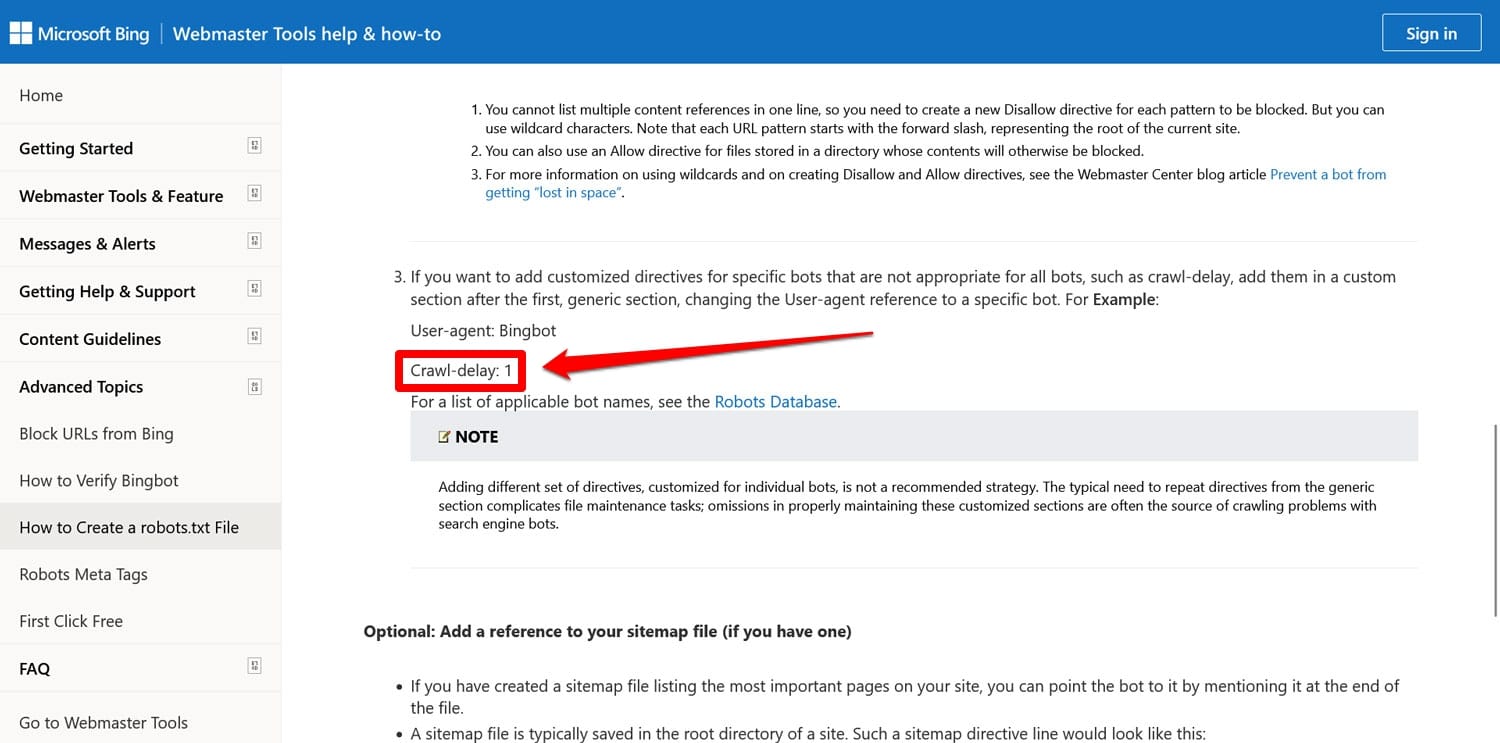
- Noindex – 用於指定搜尋引擎不應在您的網站上建立索引的 URL。
- 爬網延遲– 旨在限制爬網程式的指令,以便它們不會使 Web 伺服器資源超載。
這兩個指令現在都被忽略了,至少谷歌是這樣。至少 Bing 仍然尊重爬行延遲。
大多數情況下,最好不要使用這些指令。這有助於保持文件精簡並降低出錯風險。
提示:如果您的目標是阻止搜尋引擎對某些頁面建立索引,請改用noindex元標記。您可以使用 SEO 外掛程式在每個頁面上實現它。
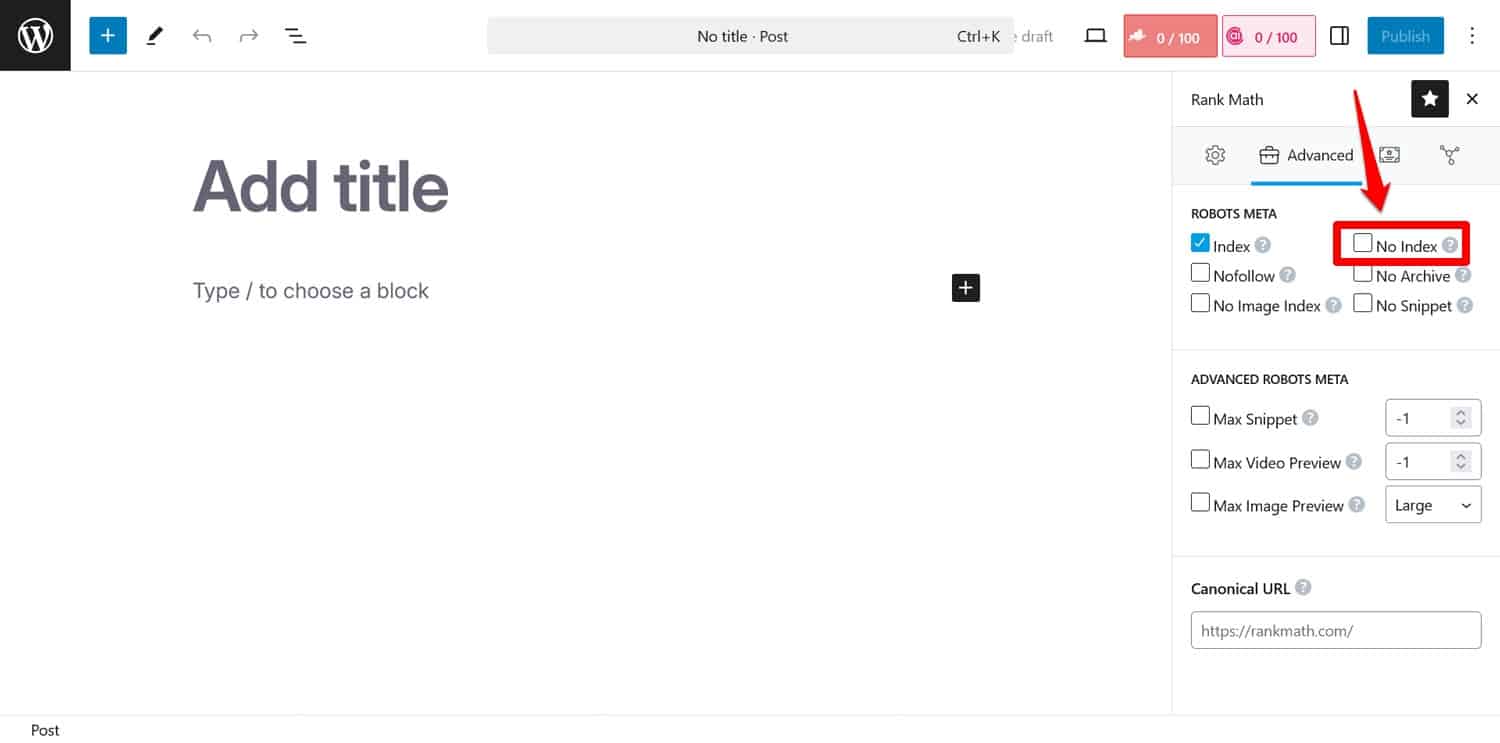
如果您透過 robots.txt 封鎖頁面,抓取工具將無法到達看到noindex標記的部分。這樣,他們可能仍然會索引您的頁面,但沒有其內容,這更糟。
4. 封鎖重要資源
人們犯的錯誤之一是使用 robots.txt 阻止對其 WordPress 網站上的所有樣式表(CSS 檔案)和腳本(JavaScript 檔案)的訪問,以保留抓取預算。
然而,這不是一個好主意。搜尋引擎機器人會像訪客一樣呈現頁面以「查看」它們。這有助於他們理解內容,以便他們可以相應地對其進行索引。
透過阻止這些資源,您可能會給搜尋引擎留下對您的頁面的錯誤印象,可能導致它們無法正確索引或損害其排名。
如果您認為 CSS 和 JavaScript 檔案可能會影響網站的效能,那麼最好對它們進行最佳化,使其能夠快速加載,無論是對機器人還是普通訪客。您可以透過縮小程式碼和壓縮網站檔案來實現這一點,以便它們傳輸得更快。此外,還可以透過消除未使用的程式碼和延遲渲染阻塞資源來優化其交付。

提示:您可以使用 WP Rocket 等效能外掛程式來簡化此過程。其用戶友好的介面可讓您透過選取「檔案優化」功能表中的幾個方塊來優化檔案傳輸。
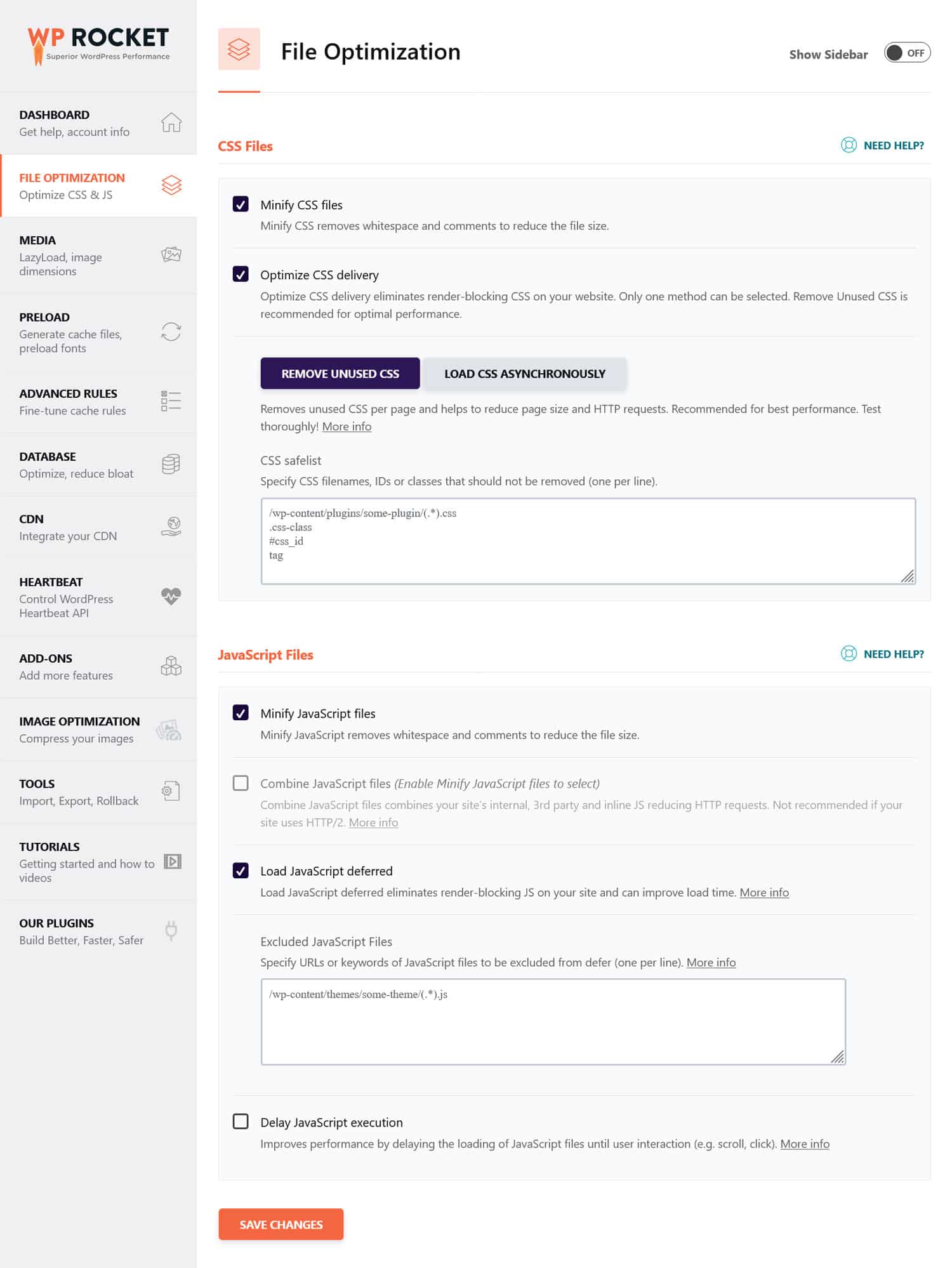
WP Rocket 還配備了額外的功能來提高網站效能,包括:
- 緩存,具有專用的移動緩存
- 圖片和影片的延遲加載
- 預先載入快取、連結、外部檔案和字體
- 資料庫最佳化
此外,該外掛程式會自動執行許多最佳化步驟。例如瀏覽器和伺服器快取、GZIP 壓縮以及優化首屏圖像以改進 LCP。這樣,只需打開 WP Rocket,您的網站就會變得更快。
該插件還提供 14 天退款保證,因此您可以無風險地測試它。
5. 未能更新您的開發 robots.txt
在建立網站時,開發人員通常會包含一個 robots.txt 文件,該文件禁止所有機器人訪問該網站。這是有道理的;您最不想看到的就是您未完成的網站出現在搜尋結果中。
只有當您不小心將此文件傳輸到生產伺服器並阻止搜尋引擎對您的即時網站建立索引時,才會出現問題。如果您的內容拒絕出現在搜尋結果中,請務必檢查此項目。
6. 不包含網站地圖的鏈接
從 robots.txt 連結到網站地圖可為搜尋引擎抓取工具提供所有內容的清單。這增加了他們索引更多內容的機會,而不僅僅是他們登陸的當前頁面。
只需一行:
Sitemap: https://yourwebsite.com/sitemap.xml是的,您也可以直接在 Google Search Console 等工具中提交網站地圖。
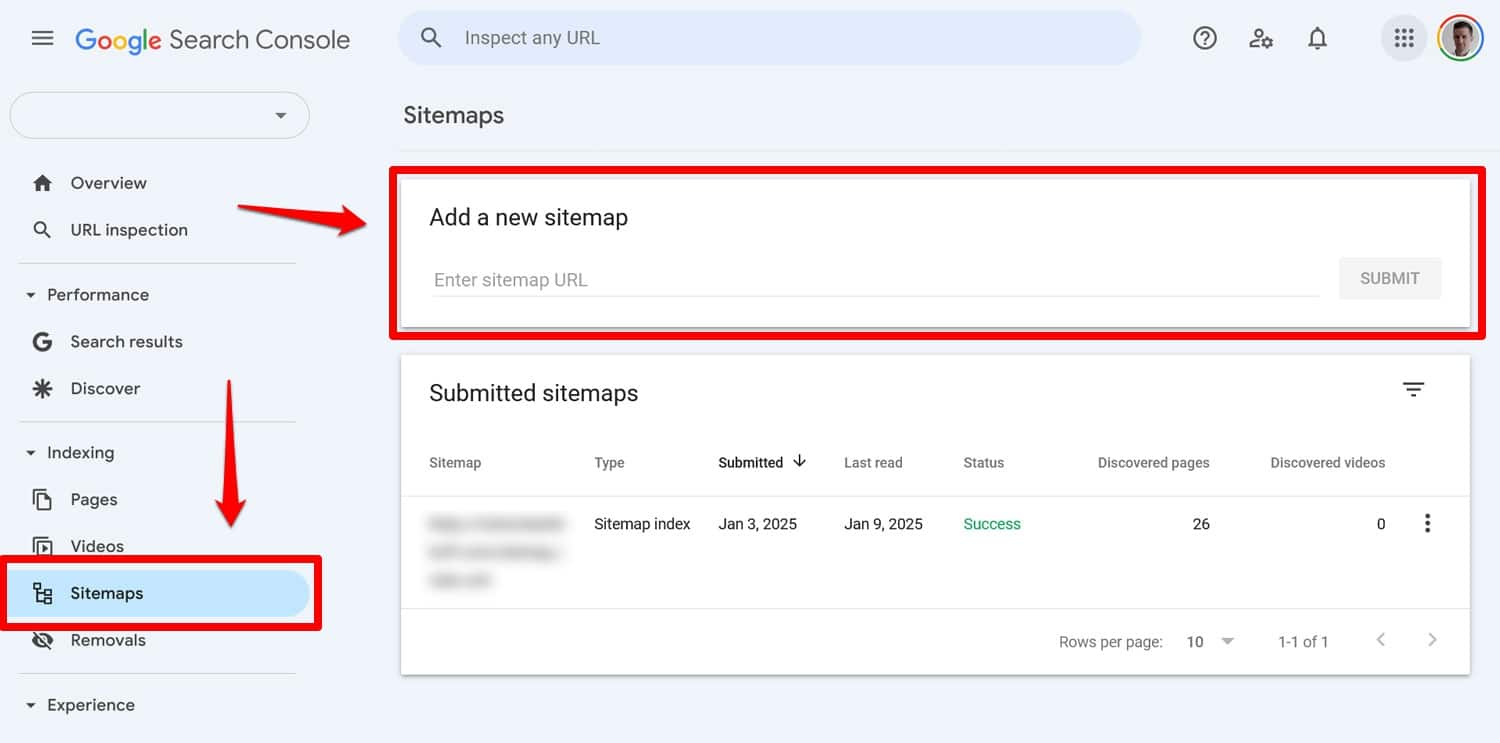
但是,將其包含在您的 robots.txt 檔案中仍然有用,特別是對於您不使用其網站管理員工具的搜尋引擎。
7. 使用衝突的規則
建立 robots.txt 檔案時的一個常見錯誤是新增相互矛盾的規則,例如:
User-agent: * Disallow: /blog/ Allow: /blog/上述指示讓搜尋引擎不清楚是否該抓取/blog/目錄。這會導致不可預測的結果,並可能損害您的搜尋引擎優化。
| 想知道還有哪些因素會損害您網站的搜尋排名以及如何避免?在我們的 SEO 錯誤指南中了解這一點。 |
為避免衝突,請遵循以下最佳實務:
- 首先使用具體規則-將更具體的規則放在更廣泛的規則之前。
- 避免冗餘– 不要在同一路徑中包含相反的指令。
- 測試您的 robots.txt 檔案– 使用工具確認規則的行為符合預期。下面詳細介紹一下。
8.嘗試使用robots.txt隱藏敏感內容
如前所述,robots.txt 並不是一個將內容排除在搜尋結果之外的工具。事實上,由於該文件是可公開存取的,因此使用它來阻止敏感內容可能會無意中洩露該內容的確切位置。
提示:使用noindex元標記將內容排除在搜尋結果之外。此外,使用密碼保護網站的敏感區域,以確保它們免受機器人和未經授權使用者的攻擊。
9. 通配符使用不當
通配符允許您在指令中包含大量路徑或檔案。我們之前已經見過一個符號,即 * 符號。它的意思是“每個實例”,最常用於設定適用於所有用戶代理的規則。
另一個通配符是 $,它將規則套用於 URL 的末尾部分。例如,如果您想阻止爬蟲訪問您網站上的所有 PDF 文件,您可以使用它:
Disallow: /*.pdf$雖然通配符很有用,但它們可能會產生廣泛的影響。小心使用它們,並始終測試您的 robots.txt 檔案以確保您沒有犯任何錯誤。
10. 混淆絕對 URL 和相對 URL
以下是絕對 URL 和相對 URL 之間的差異:
- 絕對 URL – https://yourwebsite.com/private/
- 相對 URL – /private/
建議您在 robots.txt 指令中使用相對 URL,例如:
Disallow: /private/絕對 URL 可能會導致機器人可能忽略或誤解該指令的問題。唯一的例外是網站地圖的路徑,它必須是絕對 URL。
11. 忽略大小寫
Robots.txt 指令區分大小寫。這意味著以下兩個指令不可互換:
Disallow: /Private/ Disallow: /private/如果您發現 robots.txt 檔案的行為不符合預期,請檢查是否有大小寫錯誤的問題。
12. 錯誤地使用尾部斜杠
尾部斜線是 URL 末端的斜線:
- 沒有尾部斜線:/directory
- 附尾部斜線:/directory/
在 robots.txt 中,它決定允許和禁止哪些網站資源。這是一個例子:
Disallow: /private/上述規則阻止爬蟲存取您網站上的「私有」目錄及其中的所有內容。另一方面,假設您省略了尾部斜杠,如下所示:
Disallow: /private在這種情況下,該規則也會阻止您網站上以「private」開頭的其他實例,例如:
- https://yourwebsite.com/private.html
- https://yourwebsite.com/privateer
因此,準確非常重要。如有疑問,請測試您的文件。
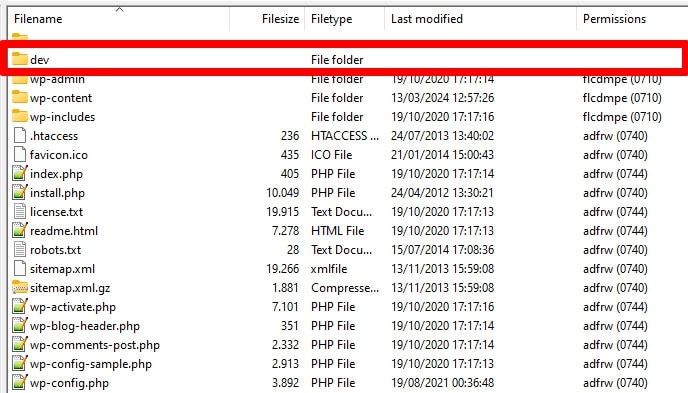
13. 子網域缺少 robots.txt
您網站上的每個子網域(例如 dev.yourwebsite.com)都需要自己的 robots.txt 文件,因為搜尋引擎將它們視為單獨的網路實體。如果沒有適當的文件,您可能會面臨爬網程式對您想要隱藏的部分網站建立索引的風險。
例如,如果您的開發版本位於名為「dev」的資料夾中並使用子網域,請確保它有一個專用的 robots.txt 檔案來阻止搜尋爬蟲。
14. 不測試您的 robots.txt 文件
配置 WordPress robots.txt 檔案時最大的錯誤之一是未能對其進行測試,尤其是在進行更改之後。
如我們所見,即使是語法或邏輯上的小錯誤也可能導致嚴重的 SEO 問題。因此,請務必測試您的 robots.txt 檔案。
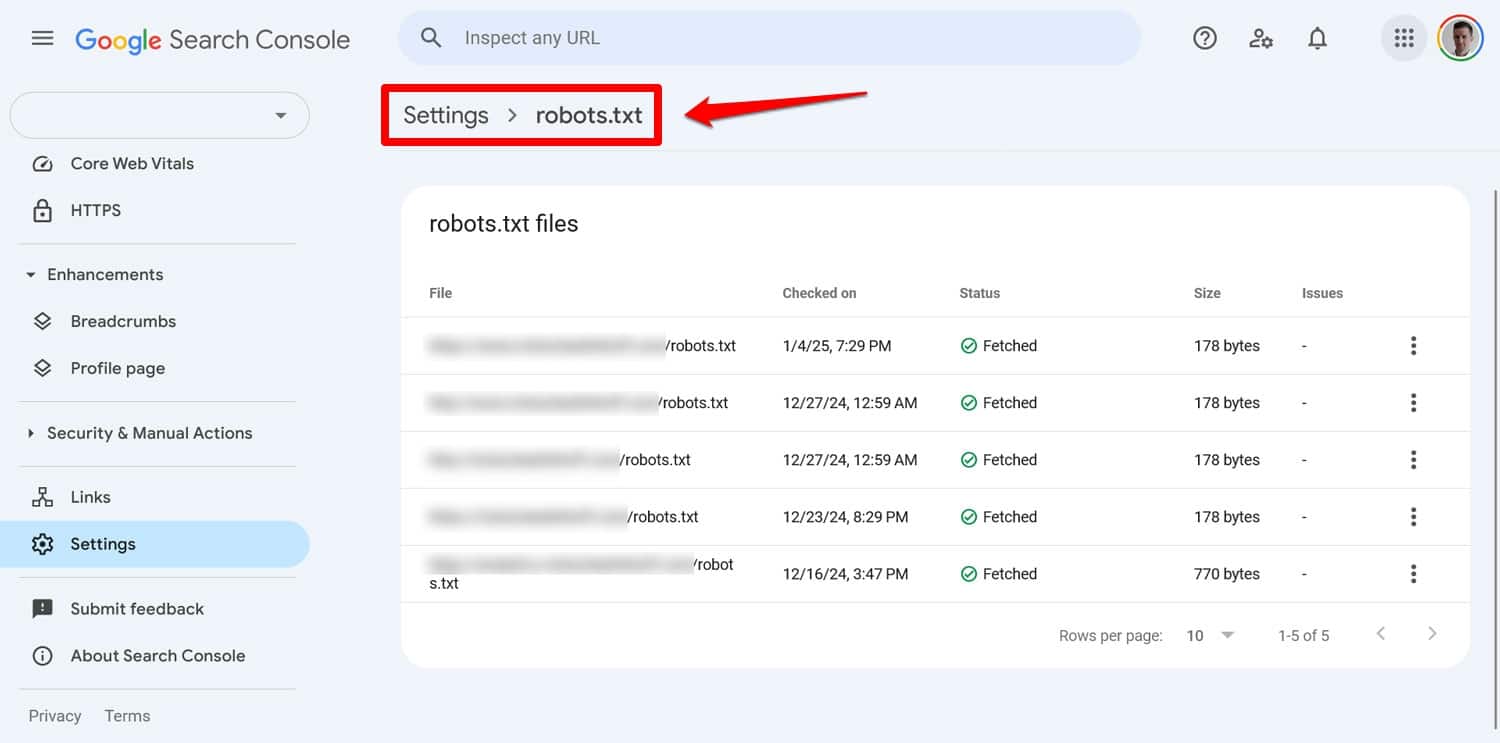
您可以在 Google Search Console 中的「設定」> robots.txt下查看文件的任何問題。
另一種方法是使用 Screaming Frog 等工具來模擬爬行行為。此外,在將新規則套用到實際網站之前,請使用暫存環境來驗證新規則的影響。
如何從 robots.txt 錯誤中恢復
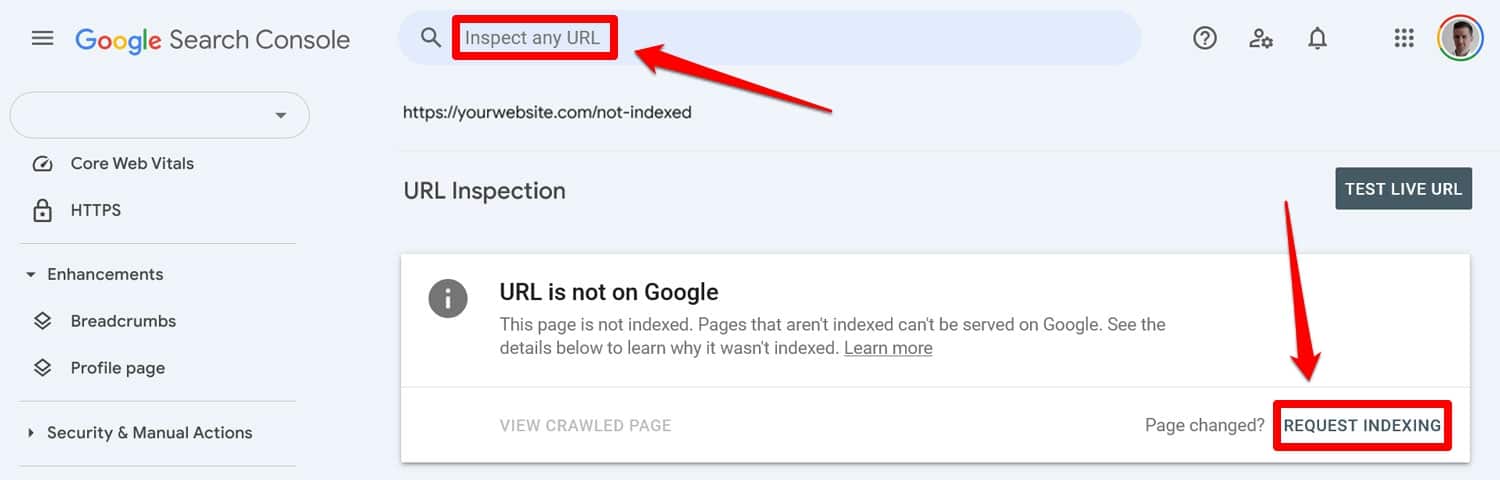
robots.txt 檔案中的錯誤很容易犯,但幸運的是,一旦發現它們通常也很容易修復。
首先透過測試工具運行更新的 robots.txt 檔案。然後,如果頁面之前被 robots.txt 指令阻止,請將其手動輸入 Google Search Console 或 Bing 網站管理員工具以請求索引。
此外,重新提交最新版本的網站地圖。
之後,就只剩下一場等待的遊戲了。搜尋引擎將重新訪問您的網站,並希望盡快恢復您在排名中的位置。
掌控您的 WordPress robots.txt
對於 robots.txt 文件,預防勝於治療。特別是在大型網站上,錯誤的文件可能會對排名、流量和收入造成嚴重破壞。
因此,對網站 robots.txt 的任何更改都應謹慎進行並進行廣泛的測試。意識到自己可能犯的錯誤是預防錯誤的第一步。
當你確實犯了錯誤時,盡量不要驚慌。診斷問題所在,修正所有錯誤,然後重新提交網站地圖以重新抓取您的網站。
最後,確保效能不是搜尋引擎無法正確抓取您網站的原因。立即嘗試 WP Rocket,讓您的網站立即變得更快!