
PostgreSQL Replikasyonu: Kapsamlı Bir Kılavuz
Yayınlanan: 2022-08-11Herhangi bir site sahibinin size söyleyeceği gibi, veri kaybı ve kesinti süresi, minimum dozlarda bile felaket olabilir. Her an hazırlıksız yakalanabilirler, bu da üretkenliğin, erişilebilirliğin ve ürün güveninin azalmasına yol açar.
Sitenizin bütünlüğünü korumak için, kesinti veya veri kaybı olasılığına karşı önlemler almak hayati önem taşır.
İşte burada veri çoğaltma devreye girer.
Veri çoğaltma, verilerinizin güvenlik amacıyla ana veritabanından başka bir uzak konuma tekrar tekrar kopyalandığı otomatik bir yedekleme işlemidir. Bir veritabanı sunucusu çalıştıran herhangi bir site veya uygulama için entegre bir teknolojidir. Ayrıca, salt okunur SQL'i işlemek için çoğaltılan veritabanından yararlanarak sistem içinde daha fazla işlemin çalıştırılmasına izin verebilirsiniz.
İki veritabanı arasında replikasyon kurmak, beklenmeyen aksiliklere karşı hata toleransı sunar. Afetler sırasında yüksek kullanılabilirlik elde etmek için en iyi strateji olarak kabul edilir.
Bu makalede, sorunsuz PostgreSQL replikasyonu için arka uç geliştiricileri tarafından uygulanabilecek farklı stratejilere dalacağız.
PostgreSQL Çoğaltma Nedir?
PostgreSQL replikasyonu, bir PostgreSQL veritabanı sunucusundan başka bir sunucuya veri kopyalama işlemi olarak tanımlanır. Kaynak veritabanı sunucusu "birincil" sunucu olarak da bilinirken, kopyalanan verileri alan veritabanı sunucusu "replika" sunucusu olarak bilinir.
PostgreSQL veritabanı, tüm yazmaların birincil bir düğüme gittiği basit bir çoğaltma modelini izler. Birincil düğüm daha sonra bu değişiklikleri uygulayabilir ve bunları ikincil düğümlere yayınlayabilir.
Otomatik Yük Devretme Nedir?
PostgreSQL'de fiziksel akış çoğaltması yapılandırıldıktan sonra, veritabanının birincil sunucusu başarısız olursa yük devretme gerçekleşebilir. Yük devretme, sunucu hatalarının kapsamını belirlemek için yerleşik araçlar sağlamadığından biraz zaman alabilen kurtarma sürecini tanımlamak için kullanılır.
Yük devretme için PostgreSQL'e bağımlı olmanız gerekmez. Otomatik yük devretme ve otomatik olarak bekleme moduna geçmeyi sağlayan, veritabanı kesinti süresini azaltan özel araçlar vardır.
Yük devretme çoğaltmasını ayarlayarak, birincil sunucunun çökmesi durumunda beklemelerin kullanılabilir olmasını sağlayarak yüksek kullanılabilirliği neredeyse garanti etmiş olursunuz.
PostgreSQL Replikasyonunu Kullanmanın Faydaları
İşte PostgreSQL replikasyonundan yararlanmanın birkaç önemli avantajı:
- Veri taşıma : Veri taşıma için PostgreSQL çoğaltmasından, veritabanı sunucusu donanımını değiştirerek veya sistem dağıtımı yoluyla yararlanabilirsiniz.
- Hata toleransı : Birincil sunucu arızalanırsa, hem birincil hem de yedek sunucular için içerilen veriler aynı olduğundan yedek sunucu bir sunucu gibi davranabilir.
- Çevrimiçi işlem işleme (OLTP) performansı : Raporlama sorgu yükünü kaldırarak bir OLTP sisteminin işlem işleme süresini ve sorgu süresini iyileştirebilirsiniz. İşlem işleme süresi, bir işlem tamamlanmadan önce belirli bir sorgunun yürütülmesi için geçen süredir.
- Paralel olarak sistem testi : Yeni bir sistemi yükseltirken, sistemin mevcut verilerle iyi çalıştığından emin olmanız gerekir, bu nedenle dağıtımdan önce bir üretim veritabanı kopyasıyla test etmeniz gerekir.
PostgreSQL Replikasyonu Nasıl Çalışır?
Genel olarak, insanlar birincil ve ikincil mimariyle uğraşırken, yedekleme ve replikasyon kurmanın yalnızca bir yolu olduğuna inanırlar, ancak PostgreSQL dağıtımları aşağıdaki üç yaklaşımdan birini izler:
- Birincil düğümden ikincil düğüme depolama katmanında çoğaltmak için birim düzeyinde çoğaltma , ardından bunu blob/S3 depolamaya yedekleme.
- Verileri birincil düğümden ikincil düğüme çoğaltmak ve ardından bunları blob/S3 depolamaya yedeklemek için PostgreSQL akış çoğaltması .
- S3'ten yeni bir ikincil düğümü yeniden oluştururken birincil düğümden S3'e artımlı yedeklemeler alma . İkincil düğüm birincil düğümün yakınında olduğunda, birincil düğümden akışa başlayabilirsiniz.
Yaklaşım 1: Akış
WAL replikasyonu olarak da bilinen PostgreSQL akış replikasyonu, PostgreSQL'i tüm sunuculara kurduktan sonra sorunsuz bir şekilde kurulabilir. Bu çoğaltma yaklaşımı, WAL dosyalarının birincil veritabanından hedef veritabanına taşınmasına dayanır.
Birincil-ikincil yapılandırma kullanarak PostgreSQL akış çoğaltmasını uygulayabilirsiniz. Birincil sunucu, birincil veritabanını ve tüm işlemlerini yöneten ana örnektir. İkincil sunucu, tamamlayıcı örnek olarak hareket eder ve birincil veritabanında yapılan tüm değişiklikleri kendi üzerinde yürütür ve süreçte özdeş bir kopya oluşturur. Birincil sunucu okuma/yazma sunucusu iken ikincil sunucu yalnızca salt okunurdur.
Bu yaklaşım için hem birincil düğümü hem de bekleme düğümünü yapılandırmanız gerekir. Aşağıdaki bölümler, bunların kolaylıkla yapılandırılmasıyla ilgili adımları açıklayacaktır.
Birincil Düğümü Yapılandırma
Aşağıdaki adımları uygulayarak birincil düğümü akış çoğaltması için yapılandırabilirsiniz:
Adım 1: Veritabanını Başlatın
Veritabanını başlatmak için initidb utility komutundan yararlanabilirsiniz. Ardından, aşağıdaki komutu kullanarak çoğaltma ayrıcalıklarına sahip yeni bir kullanıcı oluşturabilirsiniz:
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';Kullanıcı, verilen sorgu için bir şifre ve kullanıcı adı sağlamalıdır. Replication anahtar sözcüğü, kullanıcıya gerekli ayrıcalıkları vermek için kullanılır. Örnek bir sorgu şuna benzer:
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'2. Adım: Akış Özelliklerini Yapılandırın
Ardından, aşağıdaki gibi değiştirilebilen PostgreSQL yapılandırma dosyasıyla ( postgresql.conf ) akış özelliklerini yapılandırabilirsiniz:
wal_level = logical wal_log_hints = on max_wal_senders = 8 max_wal_size = 1GB hot_standby = onÖnceki snippet'te kullanılan parametrelerle ilgili küçük bir arka plan:
-
wal_log_hints: Bu parametre, bekleme sunucusunun birincil sunucuyla senkronizasyonu bozulduğunda kullanışlı olanpg_rewindözelliği için gereklidir. -
wal_level:minimal,replicaveyalogicaldahil olası değerlerle PostgreSQL akış çoğaltmasını etkinleştirmek için bu parametreyi kullanabilirsiniz. -
max_wal_size: Bu, günlük dosyalarında tutulabilecek WAL dosyalarının boyutunu belirtmek için kullanılabilir. -
hot_standby: ON olarak ayarlandığında ikincil ile bir okuma bağlantısı için bu parametreden yararlanabilirsiniz. -
max_wal_senders: Yedek sunucularla kurulabilecek maksimum eşzamanlı bağlantı sayısını belirtmek içinmax_wal_senderskullanabilirsiniz.
3. Adım: Yeni Giriş Oluşturun
Postgresql.conf dosyasındaki parametreleri değiştirdikten sonra, pg_hba.conf dosyasındaki yeni bir çoğaltma girişi, sunucuların çoğaltma için birbirleriyle bağlantı kurmasına izin verebilir.
Bu dosyayı genellikle PostgreSQL'in veri dizininde bulabilirsiniz. Bunun için aşağıdaki kod parçasını kullanabilirsiniz:
host replication rep_user IPaddress md5 Kod parçacığı yürütüldüğünde, birincil sunucu rep_user adlı bir kullanıcının, çoğaltma için belirtilen IP'yi kullanarak bağlanmasına ve yedek sunucu olarak hareket etmesine izin verir. Örneğin:
host replication rep_user 192.168.0.22/32 md5Bekleme Düğümünü Yapılandırma
Bekleme düğümünü akış çoğaltması için yapılandırmak için şu adımları izleyin:
1. Adım: Birincil Düğümü Yedekleyin
Bekleme düğümünü yapılandırmak için, birincil düğümün bir yedeğini oluşturmak üzere pg_basebackup yardımcı programından yararlanın. Bu, bekleme düğümü için bir başlangıç noktası görevi görecektir. Bu yardımcı programı aşağıdaki sözdizimi ile kullanabilirsiniz:
pg_basebackp -D -h -X stream -c fast -U rep_user -WYukarıda bahsedilen söz diziminde kullanılan parametreler aşağıdaki gibidir:
-
-h: Bunu birincil ana bilgisayardan bahsetmek için kullanabilirsiniz. -
-D: Bu parametre üzerinde çalışmakta olduğunuz dizini belirtir. -
-C: Kontrol noktalarını ayarlamak için bunu kullanabilirsiniz. -
-X: Bu parametre, gerekli işlem günlük dosyalarını dahil etmek için kullanılabilir. -
-W: Veritabanına bağlanmadan önce kullanıcıdan şifre istemek için bu parametreyi kullanabilirsiniz.
2. Adım: Çoğaltma Yapılandırma Dosyasını Kurun
Ardından, çoğaltma yapılandırma dosyasının var olup olmadığını kontrol etmeniz gerekir. Olmazsa, çoğaltma yapılandırma dosyasını recovery.conf olarak oluşturabilirsiniz.
Bu dosyayı PostgreSQL kurulumunun data dizininde oluşturmalısınız. pg_basebackup yardımcı programında -R seçeneğini kullanarak otomatik olarak oluşturabilirsiniz.
recovery.conf dosyası aşağıdaki komutları içermelidir:
standby_mode = 'açık'
birincil_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name=”host_name”'
recovery_target_timeline = 'en son'
Yukarıda belirtilen komutlarda kullanılan parametreler aşağıdaki gibidir:
-
primary_conninfo: Bunu, bir bağlantı dizesinden yararlanarak birincil ve ikincil sunucular arasında bağlantı kurmak için kullanabilirsiniz. -
standby_mode: Bu parametre, AÇIK konuma getirildiğinde birincil sunucunun bekleme olarak başlamasına neden olabilir. -
recovery_target_timeline: Kurtarma süresini ayarlamak için bunu kullanabilirsiniz.
Bir bağlantı kurmak için, birincil_conninfo parametresinin değerleri olarak kullanıcı adını, IP adresini ve parolayı sağlamanız gerekir. Örneğin:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Adım 3: İkincil Sunucuyu Yeniden Başlatın
Son olarak, yapılandırma işlemini tamamlamak için ikincil sunucuyu yeniden başlatabilirsiniz.
Ancak akış çoğaltma, aşağıdakiler gibi çeşitli zorluklarla birlikte gelir:
- Çeşitli PostgreSQL istemcileri (farklı programlama dillerinde yazılmıştır) tek bir uç nokta ile iletişim kurar. Birincil düğüm başarısız olduğunda, bu istemciler aynı DNS veya IP adını yeniden denemeye devam eder. Bu, yük devretmeyi uygulamaya görünür kılar.
- PostgreSQL çoğaltma, yerleşik yük devretme ve izleme ile birlikte gelmez. Birincil düğüm başarısız olduğunda, yeni birincil olmak için bir ikincil düğümü yükseltmeniz gerekir. Bu promosyonun, müşterilerin yalnızca bir birincil düğüme yazacağı ve veri tutarsızlıklarını gözlemlemeyecekleri şekilde yürütülmesi gerekir.
- PostgreSQL tüm durumunu çoğaltır. Yeni bir ikincil düğüm geliştirmeniz gerektiğinde, ikincil düğümün, kaynak yoğun olan ve kafadaki düğümleri ortadan kaldırmayı ve yenilerini oluşturmayı maliyetli hale getiren birincil düğümden tüm durum değişikliği geçmişini özetlemesi gerekir.
Yaklaşım 2: Çoğaltılmış Blok Aygıtı
Çoğaltılan blok aygıtı yaklaşımı, disk yansıtmaya (birim çoğaltma olarak da bilinir) bağlıdır. Bu yaklaşımda, değişiklikler, eşzamanlı olarak başka bir birime yansıtılan kalıcı bir birime yazılır.
Bu yaklaşımın ek yararı, bulut ortamlarında PostgreSQL, MySQL ve SQL Server dahil olmak üzere tüm ilişkisel veritabanlarıyla uyumluluğu ve veri dayanıklılığıdır.
Ancak, PostgreSQL çoğaltmaya yönelik disk yansıtma yaklaşımı, hem WAL günlüğü hem de tablo verilerini çoğaltmanızı gerektirir. Artık veritabanına yapılan her yazma işleminin ağ üzerinden eşzamanlı olarak geçmesi gerektiğinden, tek bir bayt kaybetmeyi göze alamazsınız, çünkü bu, veritabanınızı bozuk bir durumda bırakabilir.
Bu yaklaşım normalde Azure PostgreSQL ve Amazon RDS kullanılarak kullanılır.
Yaklaşım 3: WAL
WAL, segment dosyalarından oluşur (varsayılan olarak 16 MB). Her segmentin bir veya daha fazla kaydı vardır. Günlük sıra kaydı (LSN), WAL'deki bir kaydın işaretçisidir ve kaydın günlük dosyasına kaydedildiği konumu/konumu size bildirir.
Yedek sunucu, değişiklikleri birincil sunucusundan sürekli olarak kopyalamak için WAL segmentlerinden (PostgreSQL terminolojisinde XLOGS olarak da bilinir) yararlanır. Bir veritabanına uygulanmadan önce, bayt dizisi verisi parçalarını (her biri benzersiz bir LSN'ye sahiptir) seri hale getirerek bir DBMS'de dayanıklılık ve atomite sağlamak için önceden yazma günlük kaydını kullanabilirsiniz.
Bir veritabanına mutasyon uygulamak, çeşitli dosya sistemi işlemlerine yol açabilir. Ortaya çıkan ilgili bir soru, bir dosya sistemi güncellemesinin ortasındayken bir elektrik kesintisi nedeniyle bir sunucu arızası durumunda bir veritabanının atomikliği nasıl garanti edebileceğidir. Bir veritabanı önyüklendiğinde, mevcut WAL bölümlerini okuyabilen ve bunları her veri sayfasında depolanan LSN ile karşılaştırabilen bir başlatma veya yeniden yürütme işlemi başlatır (her veri sayfası, sayfayı etkileyen en son WAL kaydının LSN'si ile işaretlenir).
Günlük Gönderi Tabanlı Çoğaltma (Blok Düzeyi)
Akış çoğaltması, günlük gönderim sürecini iyileştirir. WAL anahtarını beklemek yerine, kayıtlar oluşturuldukları anda gönderilir, böylece çoğaltma gecikmesi azalır.
Yedek sunucu, bir çoğaltma protokolünden yararlanarak ağ üzerinden birincil sunucuyla bağlantı kurduğundan, akışlı çoğaltma günlük gönderimini de geride bırakır. Birincil sunucu daha sonra WAL kayıtlarını son kullanıcı tarafından sağlanan komut dosyalarına bağlı kalmadan doğrudan bu bağlantı üzerinden gönderebilir.
Günlük Gönderi Tabanlı Çoğaltma (Dosya Düzeyi)
Günlük gönderimi, WAL dosyalarını yeniden oynatarak başka bir bekleme sunucusu oluşturmak için günlük dosyalarını başka bir PostgreSQL sunucusuna kopyalamak olarak tanımlanır. Bu sunucu, kurtarma modunda çalışacak şekilde yapılandırılmıştır ve tek amacı, yeni WAL dosyalarını göründükleri gibi uygulamaktır.
Bu ikincil sunucu daha sonra birincil PostgreSQL sunucusunun sıcak bir yedeği olur. Ayrıca, etkin bekleme olarak da adlandırılan salt okunur sorgular sunabileceği bir okuma kopyası olacak şekilde yapılandırılabilir.
Sürekli WAL Arşivleme
WAL dosyalarını arşivlemek için pg_wal alt dizini dışındaki herhangi bir konumda oluşturuldukları gibi çoğaltmak, WAL arşivleme olarak bilinir. PostgreSQL, bir WAL dosyası her oluşturulduğunda, arşivleme için kullanıcı tarafından verilen bir komut dosyasını çağırır.
Komut dosyası, dosyayı NFS bağlaması gibi bir veya daha fazla konuma çoğaltmak için scp komutundan yararlanabilir. Arşivlendikten sonra, WAL segment dosyaları herhangi bir zamanda veri tabanını kurtarmak için kullanılabilir.
Diğer günlük tabanlı yapılandırmalar şunları içerir:
- Senkron replikasyon : Her senkronize replikasyon işlemi gerçekleştirilmeden önce, birincil sunucu yedeklerin verileri aldıklarını onaylayana kadar bekler. Bu yapılandırmanın avantajı, paralel yazma işlemlerinden kaynaklanan herhangi bir çakışma olmamasıdır.
- Eşzamanlı çok yöneticili çoğaltma : Burada, her sunucu yazma isteklerini kabul edebilir ve değiştirilen veriler, her işlem gerçekleştirilmeden önce orijinal sunucudan diğer tüm sunuculara iletilir. 2PC protokolünü kullanır ve ya hep ya hiç kuralına uyar.
WAL Akış Protokolü Ayrıntıları
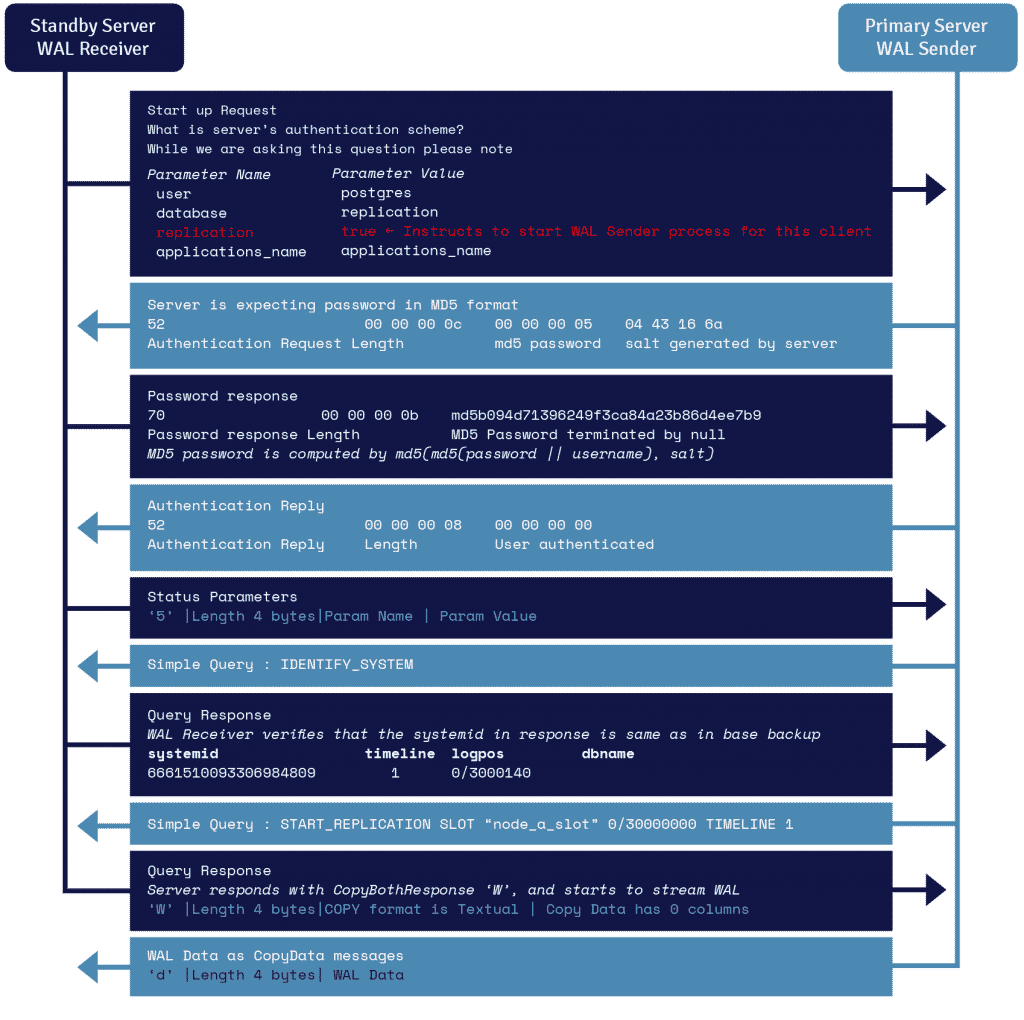
Bekleme sunucusunda çalışan WAL alıcısı olarak bilinen bir işlem, primary_conninfo birincil_conninfo parametresinde sağlanan bağlantı ayrıntılarını kullanır ve bir TCP/IP bağlantısını kullanarak birincil sunucuya bağlanır.
Akış çoğaltmasını başlatmak için ön uç, başlangıç mesajı içinde çoğaltma parametresini gönderebilir. true, yes, 1 veya ON Boole değeri, arka ucun fiziksel çoğaltma walsender moduna geçmesi gerektiğini bilmesini sağlar.
WAL gönderici, birincil sunucuda çalışan ve WAL kayıtlarını oluşturuldukça bekleme sunucusuna göndermekten sorumlu olan başka bir işlemdir. WAL alıcısı, WAL kayıtlarını, yerel olarak bağlı istemcilerin istemci etkinliği tarafından oluşturulmuşlar gibi WAL'a kaydeder.

WAL kayıtları, WAL segment dosyalarına ulaştığında, yedek sunucu, birincil ve yedeklerin güncel olması için sürekli olarak WAL'ı yeniden oynatmaya devam eder.
PostgreSQL Replikasyonunun Unsurları
Bu bölümde, PostgreSQL çoğaltmanın yaygın olarak kullanılan modelleri (tek ana ve çok ana çoğaltma), türleri (fiziksel ve mantıksal çoğaltma) ve modları (eşzamanlı ve eşzamansız) hakkında daha derin bir anlayış kazanacaksınız.
PostgreSQL Veritabanı Çoğaltma Modelleri
Ölçeklenebilirlik, veritabanının yatay ve dikey olarak elde edilebilecek daha fazla veri depolama ve işleme yeteneğini geliştirmek için mevcut düğümlere daha fazla kaynak/donanım eklemek anlamına gelir. PostgreSQL replikasyonu, uygulanması dikey ölçeklenebilirlikten çok daha zor olan yatay ölçeklenebilirliğe bir örnektir. Yatay ölçeklenebilirliği esas olarak tek ana kopya (SMR) ve çok ana kopya (MMR) ile elde edebiliriz.
Tek yöneticili çoğaltma, verilerin yalnızca tek bir düğümde değiştirilmesine olanak tanır ve bu değişiklikler bir veya daha fazla düğüme çoğaltılır. Çoğaltma veritabanındaki çoğaltılan tabloların, birincil sunucudan alınanlar dışında herhangi bir değişikliği kabul etmesine izin verilmez. Yapsalar bile, değişiklikler birincil sunucuya çoğaltılmaz.
Çoğu zaman, SMR uygulama için yeterlidir çünkü yapılandırması ve yönetimi daha az karmaşıktır ve çakışma olasılığı yoktur. Tek yöneticili çoğaltma da tek yönlüdür, çünkü çoğaltma verileri esas olarak birincilden çoğaltma veritabanına tek bir yönde akar.
Bazı durumlarda, tek başına SMR yeterli olmayabilir ve MMR'yi uygulamanız gerekebilir. MMR, birden fazla düğümün birincil düğüm olarak hareket etmesine izin verir. Birden fazla belirlenmiş birincil veritabanındaki tablo satırlarında yapılan değişiklikler, diğer her birincil veritabanındaki karşılık tablolarına çoğaltılır. Bu modelde, yinelenen birincil anahtarlar gibi sorunlardan kaçınmak için genellikle çakışma çözüm şemaları kullanılır.
MMR kullanmanın birkaç avantajı vardır, yani:
- Ana bilgisayar arızası durumunda, diğer ana bilgisayarlar yine de güncelleme ve ekleme hizmetleri verebilir.
- Birincil düğümler birkaç farklı yere yayılmıştır, bu nedenle tüm birincil düğümlerin başarısız olma şansı çok küçüktür.
- Müşteri gruplarına coğrafi olarak yakın olabilen, ancak ağ genelinde veri tutarlılığını koruyan birincil veritabanlarından oluşan geniş bir alan ağı (WAN) kullanma yeteneği.
Bununla birlikte, MMR'yi uygulamanın dezavantajı, çatışmaları çözmenin karmaşıklığı ve zorluğudur.
PostgreSQL yerel olarak desteklemediği için birçok dal ve uygulama MMR çözümleri sağlar. Bu çözümler açık kaynaklı, ücretsiz veya ücretli olabilir. Böyle bir uzantı, asenkron olan ve PostgreSQL mantıksal kod çözme işlevine dayanan çift yönlü çoğaltmadır (BDR).
BDR uygulaması diğer düğümlerdeki işlemleri yeniden yürüttüğünden, uygulanan işlem ile alıcı düğümde yapılan işlem arasında bir çakışma varsa yeniden yürütme işlemi başarısız olabilir.
PostgreSQL Çoğaltma Türleri
İki tür PostgreSQL çoğaltması vardır: mantıksal ve fiziksel çoğaltma.
Basit bir mantıksal işlem "initdb", bir küme için bir temel dizin oluşturma fiziksel işlemini gerçekleştirir. Benzer şekilde, basit bir mantıksal "CREATE DATABASE" işlemi, temel dizinde bir alt dizin oluşturma fiziksel işlemini gerçekleştirir.
Fiziksel çoğaltma genellikle dosya ve dizinlerle ilgilenir. Bu dosya ve dizinlerin neyi temsil ettiğini bilmiyor. Bu yöntemler, tipik olarak başka bir makinede tek bir kümenin tüm verilerinin tam bir kopyasını tutmak için kullanılır ve dosya sistemi düzeyinde veya disk düzeyinde yapılır ve tam blok adresleri kullanır.
Mantıksal çoğaltma, çoğaltma kimliklerine (genellikle birincil anahtar) dayalı olarak veri varlıklarını ve bunların değişikliklerini yeniden üretmenin bir yoludur. Fiziksel çoğaltmadan farklı olarak veritabanları, tablolar ve DML işlemleriyle ilgilenir ve veritabanı kümesi düzeyinde yapılır. Bir veya daha fazla abonenin bir yayıncı düğümünde bir veya daha fazla yayına abone olduğu bir yayınlama ve abone olma modelini kullanır.
Çoğaltma işlemi, yayıncı veritabanındaki verilerin anlık görüntüsünü alarak ve ardından aboneye kopyalayarak başlar. Aboneler, abone oldukları yayınlardan veri alır ve daha sonra basamaklı çoğaltmaya veya daha karmaşık yapılandırmalara izin vermek için verileri yeniden yayınlayabilir. Abone, verileri yayıncıyla aynı sırada uygular, böylece işlemsel çoğaltma olarak da bilinen tek bir abonelik içindeki yayınlar için işlem tutarlılığı garanti edilir.
Mantıksal çoğaltma için tipik kullanım durumları şunlardır:
- Tek bir veritabanındaki (veya bir veritabanının alt kümesindeki) artımlı değişiklikleri abonelere gerçekleştikçe gönderme.
- Veritabanının bir alt kümesini birden çok veritabanı arasında paylaşma.
- Aboneye ulaştıkça bireysel değişikliklerin tetiklenmesi.
- Birden çok veritabanını tek bir veritabanında birleştirme.
- Farklı kullanıcı gruplarına çoğaltılan verilere erişim sağlama.
Abone veritabanı, diğer PostgreSQL örnekleriyle aynı şekilde davranır ve yayınlarını tanımlayarak diğer veritabanları için yayıncı olarak kullanılabilir.
Abone, uygulama tarafından salt okunur olarak kabul edildiğinde, tek bir abonelikten kaynaklanan hiçbir çakışma olmayacaktır. Öte yandan, bir uygulama tarafından veya aynı tablo kümesine diğer aboneler tarafından yapılan başka yazmalar varsa, çakışmalar ortaya çıkabilir.
PostgreSQL her iki mekanizmayı da aynı anda destekler. Mantıksal çoğaltma, hem veri çoğaltma hem de güvenlik üzerinde ayrıntılı kontrol sağlar.
Çoğaltma Modları
Esas olarak iki PostgreSQL replikasyonu modu vardır: senkron ve asenkron. Eşzamanlı çoğaltma, verilerin hem birincil hem de ikincil sunucuya aynı anda yazılmasına izin verirken, eşzamansız çoğaltma, verilerin önce ana bilgisayara yazılmasını ve ardından ikincil sunucuya kopyalanmasını sağlar.
Eşzamanlı mod çoğaltmasında, birincil veritabanındaki işlemler, yalnızca bu değişiklikler tüm çoğaltmalara çoğaltıldığında tamamlanmış olarak kabul edilir. İşlemlerin birincil sunucuda tamamlanması için çoğaltma sunucularının tümü her zaman kullanılabilir olmalıdır. Eşzamanlı çoğaltma modu, anında yük devretme gereksinimleri olan üst düzey işlem ortamlarında kullanılır.
Eşzamansız modda, değişiklikler yalnızca birincil sunucuda yapıldığında, birincil sunucudaki işlemler tamamlandı olarak bildirilebilir. Bu değişiklikler daha sonra kopyalarda daha sonra çoğaltılır. Çoğaltma sunucuları, çoğaltma gecikmesi adı verilen belirli bir süre boyunca senkronizasyon dışı kalabilir. Bir kilitlenme durumunda, veri kaybı meydana gelebilir, ancak eşzamansız çoğaltmanın sağladığı ek yük küçüktür, bu nedenle çoğu durumda kabul edilebilir (ana bilgisayarı aşırı yüklemez). Birincil veritabanından ikincil veritabanına yük devretme, eşzamanlı çoğaltmadan daha uzun sürer.
PostgreSQL Çoğaltma Nasıl Kurulur
Bu bölümde, bir Linux işletim sisteminde PostgreSQL çoğaltma işleminin nasıl kurulacağını göstereceğiz. Bu örnek için Ubuntu 18.04 LTS ve PostgreSQL 10 kullanacağız.
Hadi kazalım!
Kurulum
Aşağıdaki adımlarla PostgreSQL'i Linux'a kurarak başlayacaksınız:
- Öncelikle, terminalde aşağıdaki komutu yazarak PostgreSQL imzalama anahtarını içe aktarmanız gerekir:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Ardından, terminalde aşağıdaki komutu yazarak PostgreSQL deposunu ekleyin:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Terminalde aşağıdaki komutu yazarak Depo Dizini'ni güncelleyin:
sudo apt-get update - apt komutunu kullanarak PostgreSQL paketini kurun:
sudo apt-get install -y postgresql-10 - Son olarak, aşağıdaki komutu kullanarak PostgreSQL kullanıcısının parolasını ayarlayın:
sudo passwd postgres
PostgreSQL çoğaltma işlemine başlamadan önce hem birincil hem de ikincil sunucu için PostgreSQL kurulumu zorunludur.
Her iki sunucu için de PostgreSQL'i kurduktan sonra, birincil ve ikincil sunucunun replikasyon kurulumuna geçebilirsiniz.
Birincil Sunucuda Çoğaltmayı Ayarlama
PostgreSQL'i hem birincil hem de ikincil sunuculara yükledikten sonra bu adımları gerçekleştirin.
- Öncelikle aşağıdaki komutla PostgreSQL veritabanına giriş yapın:
su - postgres - Aşağıdaki komutla bir çoğaltma kullanıcısı oluşturun:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - pg_hba.cnf'yi Ubuntu'daki herhangi bir nano uygulama ile düzenleyin ve aşağıdaki konfigürasyonu ekleyin: file edit komutu
nano /etc/postgresql/10/main/pg_hba.confDosyayı yapılandırmak için aşağıdaki komutu kullanın:
host replication replication MasterIP/24 md5 - postgresql.conf dosyasını açın ve düzenleyin ve aşağıdaki yapılandırmayı birincil sunucuya yerleştirin:
nano /etc/postgresql/10/main/postgresql.confAşağıdaki yapılandırma ayarlarını kullanın:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - Son olarak, birincil ana sunucuda PostgreSQL'i yeniden başlatın:
systemctl restart postgresqlArtık birincil sunucuda kurulumu tamamladınız.
İkincil Sunucuda Çoğaltmayı Ayarlama
İkincil sunucuda çoğaltmayı ayarlamak için şu adımları izleyin:
- Aşağıdaki komutla PostgreSQL RDMS'ye giriş yapın:
su - postgres - Aşağıdaki komutla üzerinde çalışmamızı sağlamak için PostgreSQL hizmetinin çalışmasını durdurun:
systemctl stop postgresql - Bu komutla pg_hba.conf dosyasını düzenleyin ve aşağıdaki yapılandırmayı ekleyin:
Komutu Düzenlenano /etc/postgresql/10/main/pg_hba.confYapılandırma
host replication replication MasterIP/24 md5 - İkincil sunucuda postgresql.conf dosyasını açın ve düzenleyin ve yorum yapıldıysa aşağıdaki yapılandırmayı veya açıklamayı kaldırın: Komutu Düzenle
Yapılandırmanano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP, ikincil sunucunun adresidir.
- İkincil sunucudaki PostgreSQL veri dizinine erişin ve her şeyi kaldırın:
cd /var/lib/postgresql/10/mainrm -rfv * - PostgreSQL birincil sunucu veri dizini dosyalarını PostgreSQL ikincil sunucu veri dizinine kopyalayın ve ikincil sunucuya şu komutu yazın:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - Birincil sunucu PostgreSQL şifresini girin ve enter tuşuna basın. Ardından, kurtarma yapılandırması için aşağıdaki komutu ekleyin: Komutu Düzenle
nano /var/lib/postgresql/10/main/recovery.confYapılandırma
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Burada YOUR_PASSWORD, PostgreSQL'in oluşturduğu birincil sunucudaki replikasyon kullanıcısının şifresidir.
- Parola ayarlandıktan sonra, durdurulduğu için ikincil PostgreSQL veritabanını yeniden başlatmanız gerekir:
systemctl start postgresqlKurulumunuzu Test Etme
Adımları tamamladığımıza göre şimdi replikasyon işlemini test edelim ve ikincil sunucu veritabanını gözlemleyelim. Bunun için birincil sunucuda bir tablo oluşturuyoruz ve ikincil sunucuya da yansıyıp yansımadığını gözlemliyoruz.
Hadi hadi bakalım.
- Tabloyu birincil sunucuda oluşturduğumuz için birincil sunucuda oturum açmanız gerekir:
su - postgres psql - Şimdi 'testtable' adında basit bir tablo oluşturuyoruz ve terminalde aşağıdaki PostgreSQL sorgularını çalıştırarak tabloya veri ekliyoruz:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - İkincil sunucuda oturum açarak ikincil sunucu PostgreSQL veritabanını gözlemleyin:
su - postgres psql - Şimdi, 'testtable' tablosunun olup olmadığını kontrol ediyoruz ve terminalde aşağıdaki PostgreSQL sorgularını çalıştırarak verileri döndürebiliriz. Bu komut aslında tüm tabloyu görüntüler.
select * from testtable;
Bu, test tablosunun çıktısıdır:
| websites | ------------------- | section.com | | google.com | | github.com | --------------------Birincil sunucudakiyle aynı verileri gözlemleyebilmelisiniz.
Yukarıdakileri görüyorsanız, çoğaltma işlemini başarıyla gerçekleştirdiniz!
PostgreSQL Manuel Yük Devretme Adımları Nelerdir?
PostgreSQL manuel yük devretme adımlarını gözden geçirelim:
- Birincil sunucuyu çökert.
- Bekleme sunucusunda aşağıdaki komutu çalıştırarak bekleme sunucusunu yükseltin:
./pg_ctl promote -D ../sb_data/ server promoting - Yükseltilen bekleme sunucusuna bağlanın ve bir satır ekleyin:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values (4,'Four');
Ek düzgün çalışıyorsa, daha önce salt okunur bir sunucu olan bekleme, yeni birincil sunucu olarak yükseltilir.
PostgreSQL'de Yük Devretme Nasıl Otomatikleştirilir
Otomatik yük devretmeyi ayarlamak kolaydır.
EDB PostgreSQL yük devretme yöneticisine (EFM) ihtiyacınız olacak. EFM'yi her birincil ve yedek düğüme indirip yükledikten sonra, bir birincil düğüm, bir veya daha fazla Bekleme düğümü ve arıza durumunda iddiaları onaylayan isteğe bağlı bir Tanık düğümünden oluşan bir EFM Kümesi oluşturabilirsiniz.
EFM, sistem durumunu sürekli olarak izler ve sistem olaylarına dayalı olarak e-posta uyarıları gönderir. Bir arıza meydana geldiğinde, otomatik olarak en güncel bekleme moduna geçer ve diğer tüm bekleme sunucularını yeni birincil düğümü tanıyacak şekilde yeniden yapılandırır.
Ayrıca yük dengeleyicileri (pgPool gibi) yeniden yapılandırır ve "bölünmüş beyin" (iki düğümün her biri birincil olduğunu düşündüğü zaman) oluşmasını engeller.
Özet
Yüksek miktarda veri nedeniyle, ölçeklenebilirlik ve güvenlik, özellikle bir işlem ortamında veritabanı yönetiminde en önemli kriterlerden ikisi haline gelmiştir. Mevcut düğümlere daha fazla kaynak/donanım ekleyerek ölçeklenebilirliği dikey olarak iyileştirebilsek de, genellikle yeni donanım eklemenin maliyeti veya sınırlamaları nedeniyle bu her zaman mümkün değildir.
Bu nedenle, mevcut düğümlerin işlevselliğini geliştirmek yerine mevcut ağ düğümlerine daha fazla düğüm eklemek anlamına gelen yatay ölçeklenebilirlik gereklidir. PostgreSQL replikasyonu burada devreye giriyor.
Bu makalede, PostgreSQL çoğaltma türlerini, faydalarını, çoğaltma modlarını, yüklemeyi ve SMR ile MMR Arasında PostgreSQL yük devretmesini tartıştık. Şimdi sizden haber alalım.
Genelde hangisini uyguluyorsunuz? Hangi veritabanı özelliği sizin için en önemli ve neden? Düşüncelerinizi okumayı çok isteriz! Bunları aşağıdaki yorumlar bölümünde paylaşın.