
Rekor Sürede Sağlam Bir MongoDB Kopya Kümesi Oluşturun (4 Yöntem)
Yayınlanan: 2023-03-11MongoDB, dinamik şemalara sahip JSON benzeri belgeleri kullanan bir NoSQL veritabanıdır. Veritabanlarıyla çalışırken, veritabanı sunucularınızdan birinin arızalanması durumunda bir acil durum planına sahip olmak her zaman iyidir. Kenar çubuğu, WordPress siteniz için şık bir yönetim aracından yararlanarak bunun olma şansını azaltabilirsiniz.
Bu nedenle, verilerinizin birçok kopyasına sahip olmanız yararlıdır. Ayrıca okuma gecikmelerini de azaltır. Aynı zamanda, veritabanının ölçeklenebilirliğini ve kullanılabilirliğini geliştirebilir. İşte burada replikasyon devreye giriyor. Birden fazla veritabanında verileri senkronize etme uygulaması olarak tanımlanıyor.
Bu makalede, birkaç isim vermek gerekirse, MongoDB replikasyonunun özellikleri ve mekanizması gibi çeşitli göze çarpan yönlerine dalacağız.
MongoDB'de Çoğaltma Nedir?
MongoDB'de replika kümeleri replikasyonu gerçekleştirir. Bu, çoğaltma yoluyla aynı veri kümesini koruyan bir sunucu grubudur. Yük dengelemenin bir parçası olarak MongoDB replikasyonunu bile kullanabilirsiniz. Burada, kullanım durumuna göre yazma ve okuma işlemlerini tüm örneklere dağıtabilirsiniz.
MongoDB Çoğaltma Kümesi Nedir?
Belirli bir çoğaltma kümesinin parçası olan her MongoDB örneği bir üyedir. Her replika setinin bir birincil üyesi ve en az bir ikincil üyesi olması gerekir.
Birincil üye, çoğaltma kümesiyle yapılan işlemler için birincil erişim noktasıdır. Ayrıca yazma işlemlerini kabul edebilen tek üyedir. Çoğaltma önce birincilin işlem günlüğünü (işlem günlüğü) kopyalar. Ardından, ikincillerin ilgili veri kümelerinde günlüğe kaydedilen değişiklikleri tekrarlar. Bu nedenle, her çoğaltma kümesi aynı anda yalnızca bir birincil üyeye sahip olabilir. Yazma işlemlerini alan çeşitli birinciller, veri çakışmalarına neden olabilir.
Genellikle uygulamalar, yazma ve okuma işlemleri için yalnızca birincil üyeyi sorgular. Kurulumunuzu bir veya daha fazla ikincil üyeden okumak üzere tasarlayabilirsiniz. Eşzamansız veri aktarımı, ikincil düğümlerin okumalarının eski verileri sunmasına neden olabilir. Bu nedenle, böyle bir düzenleme her kullanım durumu için ideal değildir.
Çoğaltma Seti Özellikleri
Otomatik yük devretme mekanizması, MongoDB'nin replika setlerini rakiplerinden ayırır. Birincil yokluğunda, ikincil düğümler arasında otomatik bir seçim yeni bir birincil seçer.
MongoDB Çoğaltma Kümesi ve MongoDB Kümesi
Bir MongoDB replika seti, replika seti düğümlerinde aynı veri setinin çeşitli kopyalarını oluşturacaktır. Bir replika setinin birincil amacı:
- Yerleşik bir yedekleme çözümü sunun
- Veri kullanılabilirliğini artırın
Bir MongoDB kümesi tamamen farklı bir top oyunudur. Verileri bir parça anahtarı aracılığıyla birçok düğüme dağıtır. Bu işlem, verileri parça adı verilen birçok parçaya böler. Ardından, her parçayı farklı bir düğüme kopyalar. Bir küme, büyük veri kümelerini ve yüksek verimli işlemleri desteklemeyi amaçlar. İş yükünü yatay olarak ölçeklendirerek bunu başarır.
Meslekten olmayanların terimleriyle, bir çoğaltma kümesi ile bir küme arasındaki fark şudur:
- Bir küme, iş yükünü dağıtır. Ayrıca birçok sunucuda veri parçalarını (parçaları) depolar.
- Bir replika seti, veri setini tamamen kopyalar.
MongoDB, parçalanmış bir küme oluşturarak bu işlevleri birleştirmenize olanak tanır. Burada, her parçayı ikincil bir sunucuya çoğaltabilirsiniz. Bu, bir parçanın yüksek artıklık ve veri kullanılabilirliği sunmasına olanak tanır.
Bir replika setinin bakımını yapmak ve kurmak teknik olarak zahmetli ve zaman alıcı olabilir. Ve doğru barındırma hizmetini mi buluyorsunuz? Bu başka bir baş ağrısı. Dışarıda bu kadar çok seçenek varken, işinizi kurmak yerine araştırma yapmak için saatler harcamak kolaydır.
Size tüm bunları ve çok daha fazlasını yapan bir araç hakkında kısa bir bilgi vereyim, böylece hizmetiniz/ürününüzle onu ezmeye geri dönebilirsiniz.
55.000'den fazla geliştirici tarafından güvenilen Kinsta'nın Uygulama Barındırma çözümü, sadece 3 basit adımda başlayabilir ve çalıştırabilirsiniz. Kulağa gerçek olamayacak kadar iyi geliyorsa, işte Kinsta kullanmanın bazı diğer faydaları:
- Kinsta'nın dahili bağlantılarıyla daha iyi performansın keyfini çıkarın : Paylaşılan veritabanlarıyla mücadelelerinizi unutun. Sorgu sayısı veya satır sayısı sınırı olmayan dahili bağlantılara sahip özel veritabanlarına geçiş yapın. Kinsta daha hızlıdır, daha güvenlidir ve sizi dahili bant genişliği/trafik için faturalandırmaz.
- Geliştiriciler için özel olarak hazırlanmış bir özellik grubu : Uygulamanızı Gmail, YouTube ve Google Arama'yı destekleyen güçlü platformda ölçeklendirin. Emin olun, burada en emin ellerdesiniz.
- Seçtiğiniz bir veri merkeziyle benzersiz hızların keyfini çıkarın : Siz ve müşterileriniz için en uygun bölgeyi seçin. Aralarından seçim yapabileceğiniz 25'in üzerinde veri merkezi ile Kinsta'nın 275+ PoP'si, web siteniz için maksimum hız ve küresel bir varlık sağlar.
Kinsta'nın uygulama barındırma çözümünü bugün ücretsiz deneyin!
MongoDB'de Çoğaltma Nasıl Çalışır?
MongoDB'de, yazma işlemlerini birincil sunucuya (düğüme) gönderirsiniz. Birincil, işlemleri ikincil sunucular arasında atayarak verileri çoğaltır.
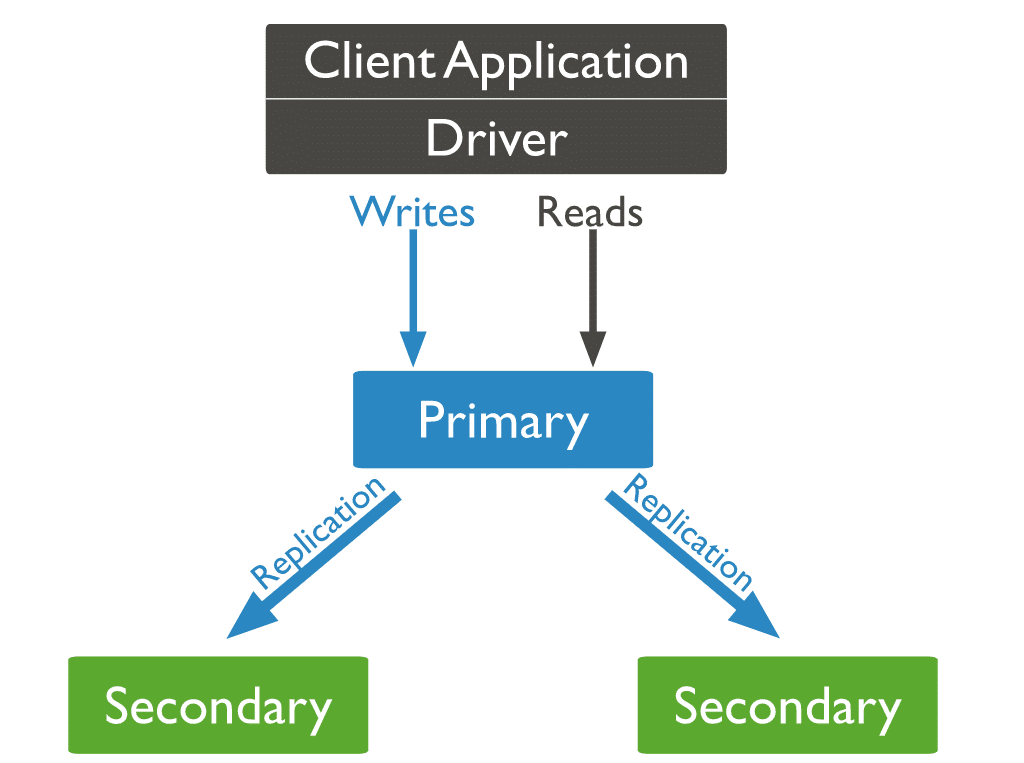
Üç Tür MongoDB Düğümü
Üç tür MongoDB düğümünden ikisi daha önce ortaya çıktı: birincil ve ikincil düğümler. Çoğaltma sırasında kullanışlı olan üçüncü tür MongoDB düğümü, hakemdir. Hakem düğümü, veri kümesinin bir kopyasına sahip değildir ve birincil olamaz. Bunu söyledikten sonra, hakem ön seçimlere katılır.
Daha önce birincil düğüm çöktüğünde ne olduğundan bahsetmiştik, peki ya ikincil düğümler tozu ısırırsa? Bu senaryoda, birincil düğüm ikincil hale gelir ve veritabanına erişilemez hale gelir.
Üye Seçimi
Seçimler aşağıdaki senaryolarda gerçekleşebilir:
- Bir kopya kümesi başlatılıyor
- Birincil düğüme bağlantı kaybı (kalp atışlarıyla tespit edilebilir)
-
rs.reconfigveyastepDownyöntemleri kullanılarak bir çoğaltma kümesinin bakımı - Mevcut bir kopya kümesine yeni bir düğüm ekleme
Bir kopya grubu en fazla 50 üyeye sahip olabilir, ancak herhangi bir seçimde yalnızca 7 veya daha azı oy kullanabilir.
Bir kümenin yeni bir ön seçimi seçmesinden önceki ortalama süre 12 saniyeyi geçmemelidir. Seçim algoritması, mümkün olan en yüksek önceliğe sahip ikincil öğeye sahip olmaya çalışacaktır. Aynı zamanda öncelik değeri 0 olan üyeler ön seçim olamaz ve seçime katılmazlar.
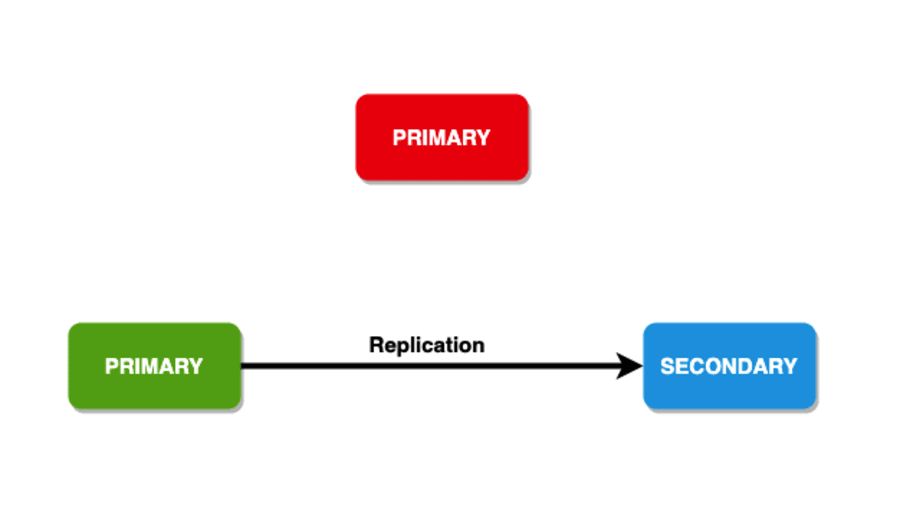
Yazma Endişesi
Dayanıklılık için, yazma işlemlerinin belirli sayıda düğümdeki verileri kopyalamak için bir çerçevesi vardır. Bununla müşteriye geri bildirim bile sunabilirsiniz. Bu çerçeve aynı zamanda "yazma kaygısı" olarak da bilinir. İşlem başarılı olarak dönmeden önce bir yazma endişesini kabul etmesi gereken veri taşıyan üyelere sahiptir. Genel olarak, çoğaltma kümelerinin yazma kaygısı olarak 1 değeri vardır. Bu nedenle, yazma endişesi onayını döndürmeden önce yalnızca birincil yazma işlemini onaylamalıdır.
Yazma işlemini onaylamak için gereken üye sayısını bile artırabilirsiniz. Sahip olabileceğiniz üye sayısının tavanı yoktur. Ancak, sayılar yüksekse, yüksek gecikme süresiyle uğraşmanız gerekir. Bunun nedeni, müşterinin tüm üyelerden onay beklemesi gerekmesidir. Ayrıca, "çoğunluğun" yazma endişesini ayarlayabilirsiniz. Bu, onaylarını aldıktan sonra üyelerin yarısından fazlasını hesaplar.
Okuma Tercihi
Okuma işlemleri için, veritabanının replika kümesinin üyelerine sorguyu nasıl yönlendirdiğini açıklayan okuma tercihinden bahsedebilirsiniz. Genel olarak, birincil düğüm okuma işlemini alır ancak istemci, okuma işlemlerini ikincil düğümlere göndermek için bir okuma tercihinden bahsedebilir. Okuma tercihi için seçenekler şunlardır:
- birincilPreferred : Genellikle okuma işlemleri birincil düğümden gelir, ancak bu mevcut değilse veriler ikincil düğümlerden çekilir.
- birincil : Tüm okuma işlemleri birincil düğümden gelir.
- ikincil : Tüm okuma işlemleri ikincil düğümler tarafından yürütülür.
- en yakın : Burada okuma istekleri,
pingkomutu çalıştırılarak tespit edilebilecek en yakın erişilebilir düğüme yönlendirilir. Okuma işlemlerinin sonucu, ister birincil ister ikincil olsun, çoğaltma kümesinin herhangi bir üyesinden gelebilir. - SecondaryPreferred : Burada okuma işlemlerinin çoğu ikincil düğümlerden gelir, ancak bunların hiçbiri mevcut değilse, veriler birincil düğümden alınır.
Replikasyon Seti Veri Senkronizasyonu
Paylaşılan veri setinin güncel kopyalarını korumak için, bir replika setinin ikincil üyeleri, diğer üyelerden gelen verileri çoğaltır veya eşitler.
MongoDB, iki tür veri eşitlemesinden yararlanır. Yeni üyeleri tam veri kümesiyle doldurmak için ilk eşitleme. Tüm veri setinde devam eden değişiklikleri yürütmek için çoğaltma.
İlk Senkronizasyon
İlk eşitleme sırasında, ikincil bir düğüm, tüm verileri birincil düğümden en son verileri içeren başka bir ikincil düğüme eşitlemek için init sync komutunu çalıştırır. Bu nedenle, ikincil düğüm, birincil düğümün local.oplog.rs koleksiyonundaki en son işlem günlüğü girişlerini sorgulamak için sürekli olarak tailable cursor özelliğinden yararlanır ve bu işlemleri bu işlem günlüğü girişleri içinde uygular.
MongoDB 5.2'den itibaren, ilk eşitlemeler dosya kopyalamaya dayalı veya mantıksal olabilir.
Mantıksal Senkronizasyon
Mantıksal bir eşitleme yürüttüğünüzde, MongoDB:
- Her koleksiyon için belgeler kopyalanırken tüm koleksiyon dizinlerini geliştirir.
- Yerel veritabanı dışındaki tüm veritabanlarını çoğaltır.
mongod, tüm kaynak veritabanlarındaki her koleksiyonu tarar ve tüm verileri bu koleksiyonların kopyalarına ekler. - Veri kümesindeki tüm değişiklikleri yürütür.
mongod, kaynaktan oplog'dan yararlanarak veri kümesini çoğaltma kümesinin mevcut durumunu gösterecek şekilde yükseltir. - Veri kopyalama sırasında yeni eklenen oplog kayıtlarını çıkarır. Hedef üyenin, bu veri kopyalama aşaması süresince bu oplog kayıtlarını geçici olarak depolamak için yerel veritabanında yeterli disk alanına sahip olduğundan emin olun.
İlk eşitleme tamamlandığında, üye STARTUP2 SECONDARY geçer.
Dosya Kopyalamaya Dayalı İlk Senkronizasyon
Hemen, bunu yalnızca MongoDB Enterprise kullanıyorsanız çalıştırabilirsiniz. Bu işlem, dosya sistemindeki dosyaları çoğaltarak ve taşıyarak ilk eşitlemeyi çalıştırır. Bu eşitleme yöntemi, bazı durumlarda mantıksal ilk eşitlemeden daha hızlı olabilir. Bir sorgu yüklemi olmadan count() yöntemini çalıştırırsanız, dosya kopyalama tabanlı ilk eşitlemenin yanlış sayımlara yol açabileceğini unutmayın.
Ancak, bu yöntemin de adil bir sınırlama payı vardır:
- Dosya kopyalamaya dayalı ilk eşitleme sırasında, eşitlenen üyenin yerel veritabanına yazamazsınız. Ayrıca, eşitlenmekte olan üyede veya eşitlenmekte olan üyede bir yedekleme çalıştıramazsınız.
- MongoDB, şifrelenmiş depolama motorundan yararlanırken, hedefi şifrelemek için kaynak anahtarını kullanır.
- Aynı anda yalnızca belirli bir üyeden ilk eşitleme çalıştırabilirsiniz.
çoğaltma
İkincil üyeler, ilk senkronizasyondan sonra verileri tutarlı bir şekilde çoğaltır. İkincil üyeler, oplog'u kaynaktan senkronizasyonlarından çoğaltacak ve bu işlemleri eşzamansız bir süreçte yürütecektir.
İkinciller, ping süresindeki değişikliklere ve diğer üyelerin çoğaltma durumuna bağlı olarak, kaynaktan senkronizasyonlarını otomatik olarak değiştirme yeteneğine sahiptir.
Akış Çoğaltma
MongoDB 4.4'ten, kaynaklardan senkronizasyon, senkronizasyon ikincillerine sürekli bir oplog girişi akışı gönderir. Akışlı çoğaltma, yüksek yüklü ve yüksek gecikmeli ağlarda çoğaltma gecikmesini azaltır. Ayrıca:
- Birincil üstlenme nedeniyle yazma işlemlerini kaybetme riskini
w:1ile azaltın. - İkincil dosyalardan gelen okumalar için bayatlığı azaltın.
-
w:“majority”vew:>1ile yazma işlemlerinde gecikmeyi azaltın. Kısacası, çoğaltma için beklemeyi gerektiren herhangi bir yazma endişesi.
Çok İş parçacıklı Çoğaltma
MongoDB, eşzamanlılığı iyileştirmek için işlemleri birden çok iş parçacığı aracılığıyla toplu olarak yazardı. MongoDB, her işlem grubunu farklı bir iş parçacığı ile uygularken partileri belge kimliğine göre gruplandırır.
MongoDB, belirli bir belge üzerinde yazma işlemlerini her zaman orijinal yazma sırasına göre yürütür. Bu, MongoDB 4.0'da değişti.
MongoDB 4.0'dan, ikincilleri hedefleyen ve “majority” veya “local” okuma endişe düzeyiyle yapılandırılan okuma işlemleri, okuma, çoğaltma gruplarının uygulandığı bir ikincilde gerçekleşirse, artık verilerin bir WiredTiger anlık görüntüsünden okunacaktır. Anlık görüntüden okuma, verilerin tutarlı bir şekilde görüntülenmesini garanti eder ve okumanın, bir kilide ihtiyaç duymadan devam eden çoğaltmayla aynı anda gerçekleşmesini sağlar.
Bu nedenle, bu okuma endişe seviyelerine ihtiyaç duyan ikincil okumaların artık çoğaltma toplu işlerinin uygulanmasını beklemesine gerek yoktur ve alındıklarında işlenebilirler.
MongoDB Çoğaltma Kümesi Nasıl Oluşturulur
Daha önce bahsedildiği gibi, MongoDB replikasyonu replika kümeleri aracılığıyla işler. Sonraki birkaç bölümde, kendi kullanım durumunuz için kopya kümeleri oluşturmak için kullanabileceğiniz birkaç yöntemi vurgulayacağız.
Yöntem 1: Ubuntu'da Yeni Bir MongoDB Kopya Kümesi Oluşturma
Başlamadan önce, her sunucuda MongoDB kurulu Ubuntu 20.04 çalıştıran en az üç sunucunuz olduğundan emin olmanız gerekir.
Bir eşleme kümesi ayarlamak için, kümedeki diğer üyelerin her bir eşleme kümesi üyesine ulaşabileceği bir adres sağlamak önemlidir. Bu durumda sette üç üye tutuyoruz. IP adreslerini kullanabiliyor olsak da, adresler beklenmedik şekilde değişebileceği için bu önerilmez. Kopya kümelerini yapılandırırken mantıksal DNS ana bilgisayar adlarını kullanmak daha iyi bir alternatif olabilir.
Bunu, her çoğaltma üyesi için alt etki alanını yapılandırarak yapabiliriz. Bu, bir üretim ortamı için ideal olsa da, bu bölüm, her sunucunun ilgili ana bilgisayar dosyalarını düzenleyerek DNS çözünürlüğünün nasıl yapılandırılacağını özetleyecektir. Bu dosya, sayısal IP adreslerine okunabilir ana bilgisayar adları atamamızı sağlar. Bu nedenle, herhangi bir durumda IP adresiniz değişirse, tek yapmanız gereken kopya setini sıfırdan yeniden yapılandırmak yerine ana bilgisayarların dosyalarını üç sunucuda güncellemektir!
hosts çoğunlukla /etc/ dizininde saklanır. Üç sunucunuzun her biri için aşağıdaki komutları tekrarlayın:
sudo nano /etc/hostsYukarıdaki komutta, metin düzenleyicimiz olarak nano kullanıyoruz, ancak tercih ettiğiniz herhangi bir metin düzenleyiciyi kullanabilirsiniz. Yerel ana bilgisayarı yapılandıran ilk birkaç satırdan sonra, kopya kümesinin her üyesi için bir giriş ekleyin. Bu girişler, seçtiğiniz bir insan tarafından okunabilen ad tarafından takip edilen bir IP adresi biçimini alır. Onları istediğiniz gibi adlandırabilirsiniz, ancak açıklayıcı olduğunuzdan emin olun, böylece her üye arasında ayrım yapmayı bilirsiniz. Bu eğitim için aşağıdaki ana bilgisayar adlarını kullanacağız:
- mongo0.replset.member
- mongo1.replset.member
- mongo2.replset.member
Bu ana bilgisayar adlarını kullandığınızda, /etc/hosts dosyalarınız aşağıdaki vurgulanmış satırlara benzer:

Dosyayı kaydedip kapatın.
Replika set için DNS çözümlemesini yapılandırdıktan sonra, firewall kurallarını birbirleriyle haberleşebilecekleri şekilde güncellememiz gerekiyor. Mongo0 üzerinde 27017 numaralı bağlantı noktasına mongo1 erişimi sağlamak için mongo0 üzerinde aşağıdaki ufw komutunu çalıştırın:
sudo ufw allow from mongo1_server_ip to any port 27017 mongo1_server_ip parametresinin yerine mongo1 sunucunuzun gerçek IP adresini girin. Ayrıca, bu sunucudaki Mongo örneğini varsayılan olmayan bir bağlantı noktası kullanacak şekilde güncellediyseniz, 27017'yi MongoDB örneğinizin kullandığı bağlantı noktasını yansıtacak şekilde değiştirdiğinizden emin olun.
Şimdi aynı bağlantı noktasına mongo2 erişimi vermek için başka bir güvenlik duvarı kuralı ekleyin:
sudo ufw allow from mongo2_server_ip to any port 27017 mongo2_server_ip parametresi yerine mongo2 sunucunuzun gerçek IP adresini girin. Ardından, diğer iki sunucunuz için güvenlik duvarı kurallarını güncelleyin. Mongo1 sunucusunda aşağıdaki komutları çalıştırın ve sırasıyla mongo0 ve mongo2'ninkileri yansıtmak için server_ip parametresi yerine IP adreslerini değiştirdiğinizden emin olun:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo2_server_ip to any port 27017Son olarak, bu iki komutu mongo2'de çalıştırın. Yine, her sunucu için doğru IP adreslerini girdiğinizden emin olun:
sudo ufw allow from mongo0_server_ip to any port 27017 sudo ufw allow from mongo1_server_ip to any port 27017Bir sonraki adımınız, harici bağlantılara izin vermek için her bir MongoDB bulut sunucusunun yapılandırma dosyasını güncellemektir. Buna izin vermek için, her sunucudaki yapılandırma dosyasını IP adresini yansıtacak ve kopya kümesini gösterecek şekilde değiştirmeniz gerekir. Siz tercih ettiğiniz herhangi bir metin editörünü kullanabilirsiniz, ancak biz yine nano metin editörünü kullanıyoruz. Her mongod.conf dosyasında aşağıdaki değişiklikleri yapalım.
mongo0'ta:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo0.replset.member# replica set replication: replSetName: "rs0"mongo1'de:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo1.replset.member replication: replSetName: "rs0"mongo2'de:
# network interfaces net: port: 27017 bindIp: 127.0.0.1,mongo2.replset.member replication: replSetName: "rs0" sudo systemctl restart mongodBununla, her sunucunun MongoDB örneği için çoğaltmayı etkinleştirdiniz.
Şimdi rs.initiate() yöntemini kullanarak kopya kümesini başlatabilirsiniz. Bu yöntemin yalnızca çoğaltma kümesindeki tek bir MongoDB eşgörünümünde yürütülmesi gerekir. Çoğaltma kümesi adının ve üyenin, daha önce her yapılandırma dosyasında yaptığınız yapılandırmalarla eşleştiğinden emin olun.
rs.initiate( { _id: "rs0", members: [ { _id: 0, host: "mongo0.replset.member" }, { _id: 1, host: "mongo1.replset.member" }, { _id: 2, host: "mongo2.replset.member" } ] })Yöntem çıktıda “ok”: 1 döndürürse, replika setinin doğru başlatıldığı anlamına gelir. Aşağıda, çıktının nasıl görünmesi gerektiğine dair bir örnek verilmiştir:
{ "ok": 1, "$clusterTime": { "clusterTime": Timestamp(1612389071, 1), "signature": { "hash": BinData(0, "AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId": NumberLong(0) } }, "operationTime": Timestamp(1612389071, 1) }MongoDB Sunucusunu Kapatın
db.shutdownServer() yöntemini kullanarak bir MongoDB sunucusunu kapatabilirsiniz. Aşağıda bunun sözdizimi verilmiştir. force ve timeoutsecs ikisi de isteğe bağlı parametrelerdir.
db.shutdownServer({ force: <boolean>, timeoutSecs: <int> }) Dizin oluştururken mongod çoğaltma kümesi üyesi belirli işlemleri çalıştırırsa bu yöntem başarısız olabilir. İşlemleri kesmek ve üyeyi kapanmaya zorlamak için force boolean parametresini true olarak girebilirsiniz.
–replSet ile MongoDB'yi Yeniden Başlatın
Yapılandırmayı sıfırlamak için çoğaltma kümenizdeki her düğümün durdurulmuş olduğundan emin olun. Ardından, her düğüm için yerel veritabanını silin. –replSet işaretini kullanarak yeniden başlatın ve çoğaltma kümesi için yalnızca bir mongod örneğinde rs.initiate() öğesini çalıştırın.
mongod --replSet "rs0" rs.initiate() isteğe bağlı bir kopya kümesi yapılandırma belgesi alabilir, yani:
-
_idalanında çoğaltma kümesi adını belirtmek içinReplication.replSetNameveya—replSetseçeneği. - Her çoğaltma kümesi üyesi için bir belge içeren üyelerin dizisi.
rs.initiate() yöntemi bir seçimi tetikler ve üyelerden birini birincil olarak seçer.

Çoğaltma Kümesine Üye Ekleme
Kümeye üye eklemek için çeşitli makinelerde mongod örneklerini başlatın. Ardından, bir mongo istemcisi başlatın ve rs.add() komutunu kullanın.
rs.add() komutu aşağıdaki temel sözdizimine sahiptir:
rs.add(HOST_NAME:PORT)Örneğin,
Mongo1'in sizin mongod örneğiniz olduğunu ve 27017 numaralı bağlantı noktasını dinlediğini varsayalım. Bu örneği çoğaltma kümesine eklemek için Mongo istemci komutu rs.add() yi kullanın.
rs.add("mongo1:27017") Yalnızca birincil düğüme bağlandıktan sonra çoğaltma kümesine bir mongod örneği ekleyebilirsiniz. Birincile bağlı olup olmadığınızı doğrulamak için db.isMaster() komutunu kullanın.
Kullanıcıları Kaldır
Bir üyeyi kaldırmak için rs.remove() işlevini kullanabiliriz.
Bunun için öncelikle kaldırmak istediğiniz mongod örneğini yukarıda bahsettiğimiz db.shutdownServer() yöntemini kullanarak kapatın.
Ardından, çoğaltma kümesinin geçerli birincil birimine bağlanın. Geçerli birincil öğeyi belirlemek için, çoğaltma kümesinin herhangi bir üyesine bağlıyken db.hello() öğesini kullanın. Birincili belirledikten sonra, aşağıdaki komutlardan birini çalıştırın:
rs.remove("mongodb-node-04:27017") rs.remove("mongodb-node-04") 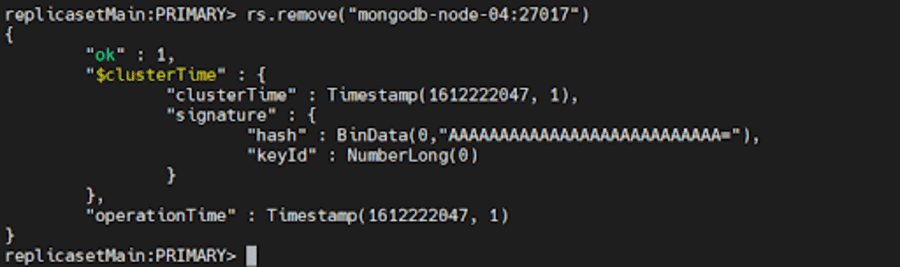
Çoğaltma setinin yeni bir birincil seçmesi gerekirse, MongoDB kabuğun bağlantısını kısa süreliğine kesebilir. Bu senaryoda, bir kez daha otomatik olarak yeniden bağlanacaktır. Ayrıca, komut başarılı olsa bile DBClientCursor::init call() başarısız hatası görüntüleyebilir.
Yöntem 2: Dağıtım ve Test için MongoDB Çoğaltma Kümesi Yapılandırma
Genel olarak, RBAC etkinleştirilmiş veya devre dışı bırakılmış olarak test için kopya kümeleri ayarlayabilirsiniz. Bu yöntemde, bir test ortamında konuşlandırmak için erişim kontrolü devre dışı bırakılmış kopya kümeleri kuracağız.
Öncelikle, aşağıdaki komutu kullanarak çoğaltma kümesinin bir parçası olan tüm örnekler için dizinler oluşturun:
mkdir -p /srv/mongodb/replicaset0-0 /srv/mongodb/replicaset0-1 /srv/mongodb/replicaset0-2Bu komut, üç MongoDB örneği için replikaset0-0, replikaset0-1 ve replikaset0-2 için dizinler yaratacaktır. Şimdi, aşağıdaki komut dizisini kullanarak her biri için MongoDB bulut sunucularını başlatın:
Sunucu 1 için:
mongod --replSet replicaset --port 27017 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Sunucu 2 için:
mongod --replSet replicaset --port 27018 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128Sunucu 3 için:
mongod --replSet replicaset --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> --dbpath /srv/mongodb/replicaset0-0 --oplogSize 128 –oplogSize parametresi, test aşamasında makinenin aşırı yüklenmesini önlemek için kullanılır. Her diskin tükettiği disk alanı miktarını azaltmaya yardımcı olur.
Şimdi, aşağıdaki bağlantı noktası numarasını kullanarak bağlanarak Mongo kabuğunu kullanan örneklerden birine bağlanın.
mongo --port 27017 Çoğaltma işlemini başlatmak için rs.initiate() komutunu kullanabiliriz. hostname parametresini sisteminizin adıyla değiştirmeniz gerekecek.
rs conf = { _id: "replicaset0", members: [ { _id: 0, host: "<hostname>:27017}, { _id: 1, host: "<hostname>:27018"}, { _id: 2, host: "<hostname>:27019"} ] }Artık yapılandırma nesne dosyasını, başlatma komutu için parametre olarak iletebilir ve aşağıdaki gibi kullanabilirsiniz:
rs.initiate(rsconf)İşte buyur! Geliştirme ve test etme amaçları için başarılı bir şekilde bir MongoDB replika seti oluşturdunuz.
Yöntem 3: Tek Başına Bir Örneği MongoDB Çoğaltma Kümesine Dönüştürme
MongoDB, kullanıcılarının bağımsız örneklerini kopya kümelerine dönüştürmesine olanak tanır. Bağımsız bulut sunucuları çoğunlukla test ve geliştirme aşaması için kullanılırken, kopya kümeleri üretim ortamının bir parçasıdır.
Başlamak için, aşağıdaki komutu kullanarak mongod örneğimizi kapatalım:
db.adminCommand({"shutdown":"1"}) Kullanacağınız çoğaltma kümesini belirtmek için komutunuzdaki –repelSet parametresini kullanarak örneğinizi yeniden başlatın:
mongod --port 27017 – dbpath /var/lib/mongodb --replSet replicaSet1 --bind_ip localhost,<hostname(s)|ip address(es)>Komutta benzersiz adresle birlikte sunucunuzun adını belirtmeniz gerekir.
Kabuğu MongoDB bulut sunucunuza bağlayın ve çoğaltma işlemini başlatmak ve örneği başarıyla bir kopya kümesine dönüştürmek için başlatma komutunu kullanın. Örnek ekleme veya kaldırma gibi tüm temel işlemleri aşağıdaki komutları kullanarak gerçekleştirebilirsiniz:
rs.add(“<host_name:port>”) rs.remove(“host-name”) Ek olarak, rs.status() ve rs.conf() komutlarını kullanarak MongoDB replika setinizin durumunu kontrol edebilirsiniz.
Yöntem 4: MongoDB Atlası — Daha Basit Bir Alternatif
Çoğaltma ve parçalama, parçalı küme adı verilen bir şey oluşturmak için birlikte çalışabilir. Kurulum ve konfigürasyon, basit olmasına rağmen oldukça zaman alabilirken, MongoDB Atlas, daha önce bahsedilen yöntemlerden daha iyi bir alternatiftir.
Kopya kümelerinizi otomatikleştirerek işlemin uygulanmasını kolaylaştırır. Birkaç tıklama ile küresel olarak parçalanmış çoğaltma kümelerini devreye alarak olağanüstü durum kurtarma, daha kolay yönetim, veri konumu ve çok bölgeli dağıtımlar sağlayabilir.
MongoDB Atlas'ta kümeler oluşturmamız gerekiyor - bunlar bir kopya kümesi veya parçalanmış bir küme olabilir. Belirli bir proje için, diğer bölgelerdeki bir kümedeki düğüm sayısı toplam 40 ile sınırlıdır.
Ücretsiz veya paylaşılan kümeler ve birbiriyle iletişim kuran Google bulut bölgeleri buna dahil değildir. Herhangi iki bölge arasındaki toplam düğüm sayısı bu kısıtlamayı karşılamalıdır. Örneğin, aşağıdakileri içeren bir proje varsa:
- A bölgesinde 15 düğüm vardır.
- B bölgesinde 25 düğüm var
- Bölge C'de 10 düğüm var
C bölgesine sadece 5 düğüm daha tahsis edebiliriz:
- Bölge A+ Bölge B = 40; izin verilen maksimum düğüm sayısı olan 40 kısıtlamasını karşılar.
- Bölge B+ Bölge C = 25+10+5 (C'ye tahsis edilen ek düğümler) = 40; izin verilen maksimum düğüm sayısı olan 40 kısıtlamasını karşılar.
- Bölge A+ Bölge C =15+10+5 (C'ye tahsis edilen ek düğümler) = 30; izin verilen maksimum düğüm sayısı olan 40 kısıtlamasını karşılar.
C bölgesine 10 düğüm daha ayırırsak, C bölgesinde 20 düğüm olur, o zaman Bölge B + Bölge C = 45 düğüm olur. Bu, verilen kısıtlamayı aşacaktır, dolayısıyla çok bölgeli bir küme oluşturamayabilirsiniz.
Bir küme oluşturduğunuzda, Atlas, projede bulut sağlayıcı için daha önce yoksa bir ağ kapsayıcısı oluşturur. MongoDB Atlas'ta bir çoğaltma kümesi kümesi oluşturmak için Atlas CLI'de aşağıdaki komutu çalıştırın:
atlas clusters create [name] [options]Küme oluşturulduktan sonra değiştirilemeyeceği için açıklayıcı bir küme adı verdiğinizden emin olun. Argüman ASCII harfleri, sayıları ve kısa çizgileri içerebilir.
Gereksinimlerinize göre MongoDB'de küme oluşturmak için çeşitli seçenekler mevcuttur. Örneğin, kümeniz için sürekli bulut yedeklemesi istiyorsanız --backup true olarak ayarlayın.
Çoğaltma Gecikmesiyle Başa Çıkma
Çoğaltma gecikmesi oldukça rahatsız edici olabilir. Birincil üzerindeki bir işlem ile bu işlemin oplog'dan ikincil olana uygulanması arasındaki bir gecikmedir. İşletmeniz büyük veri kümeleriyle ilgileniyorsa, belirli bir eşik içinde bir gecikme beklenir. Ancak bazen dış etkenler de gecikmeye katkıda bulunabilir ve artabilir. Güncel bir çoğaltmadan yararlanmak için şunlardan emin olun:
- Ağ trafiğinizi kararlı ve yeterli bir bant genişliğinde yönlendirirsiniz. Ağ gecikmesi, çoğaltma işleminizi etkilemede büyük bir rol oynar ve ağ, çoğaltma işleminin gereksinimlerini karşılamak için yetersizse, çoğaltma kümesi genelinde verilerin çoğaltılmasında gecikmeler olacaktır.
- Yeterli disk veriminiz var. İkincildeki dosya sistemi ve disk aygıtı verileri diske birincil kadar hızlı akıtamıyorsa, ikincil sistem ayak uydurmakta güçlük çekecektir. Bu nedenle, ikincil düğümler, yazma sorgularını birincil düğümden daha yavaş işler. Bu, sanallaştırılmış örnekler ve büyük ölçekli dağıtımlar dahil olmak üzere çoğu çok kiracılı sistemde yaygın bir sorundur.
- Özellikle birincil öğeye çok sayıda yazma gerektiren bir toplu yükleme işlemi veya veri alımı gerçekleştirmek istediğinizde, ikincillerin birincil öğeyi yakalamasına fırsat sağlamak için bir aradan sonra bir yazma onayı yazma endişesi istersiniz. Yardımcılar, değişikliklere ayak uydurmak için oplog'u yeterince hızlı okuyamaz; özellikle kabul edilmemiş yazma endişeleri söz konusu olduğunda.
- Çalışan arka plan görevlerini tanımlarsınız. Cron işleri, sunucu güncellemeleri ve güvenlik kontrolleri gibi belirli görevler, ağ veya disk kullanımı üzerinde beklenmeyen etkilere sahip olabilir ve çoğaltma işleminde gecikmelere neden olabilir.
Uygulamanızda bir çoğaltma gecikmesi olup olmadığından emin değilseniz, üzülmeyin - sonraki bölümde sorun giderme stratejileri ele alınmaktadır!
MongoDB Çoğaltma Setlerinde Sorun Giderme
Kopya kümelerinizi başarıyla kurdunuz, ancak verilerinizin sunucular arasında tutarsız olduğunu fark ettiniz. Bu, büyük ölçekli işletmeler için oldukça endişe vericidir, ancak hızlı sorun giderme yöntemleriyle sorunun nedenini bulabilir ve hatta düzeltebilirsiniz! Aşağıda verilenler, kullanışlı olabilecek çoğaltma seti dağıtımlarında sorun gidermeye yönelik bazı yaygın stratejilerdir:
Kopya Durumunu Kontrol Edin
Bir replika setinin birinciline bağlı bir mongosh oturumunda aşağıdaki komutu çalıştırarak, replika setinin mevcut durumunu ve her üyenin durumunu kontrol edebiliriz.
rs.status()Çoğaltma Gecikmesini Kontrol Edin
Daha önce tartışıldığı gibi, "gecikmeli" üyeleri hızla birincil olmaya uygun hale getirmediği ve dağıtılmış okuma işlemlerinin tutarsız olma olasılığını artırdığı için çoğaltma gecikmesi ciddi bir sorun olabilir. Aşağıdaki komutu kullanarak çoğaltma günlüğünün geçerli uzunluğunu kontrol edebiliriz:
rs.printSecondaryReplicationInfo() Bu, son oplog girişinin her üye için ikincil olarak yazıldığı zaman olan syncedTo değerini döndürür. İşte aynı şeyi göstermek için bir örnek:
source: m1.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary source: m2.example.net:27017 syncedTo: Mon Oct 10 2022 10:19:35 GMT-0400 (EDT) 0 secs (0 hrs) behind the primary Geciken üye, birincil öğedeki hareketsizlik süresi members[n].secondaryDelaySecs değerinden büyük olduğunda, birincil üyenin 0 saniye gerisinde görünebilir.
Tüm Üyeler Arasındaki Bağlantıları Test Edin
Bir çoğaltma kümesinin her üyesi, diğer tüm üyelerle bağlantı kurabilmelidir. Her zaman bağlantıları her iki yönde de doğruladığınızdan emin olun. Çoğunlukla, güvenlik duvarı yapılandırmaları veya ağ topolojileri, çoğaltmayı engelleyebilecek normal ve gerekli bağlantıyı engeller.
Örneğin, mongod örneğinin hem localhost'a hem de IP Adresi 198.41.110.1 ile ilişkili 'ExampleHostname' ana bilgisayar adına bağlandığını varsayalım:
mongod --bind_ip localhost, ExampleHostnameBu örneğe bağlanmak için uzak istemcilerin ana bilgisayar adını veya IP Adresini belirtmesi gerekir:
mongosh --host ExampleHostname mongosh --host 198.41.110.1Bir çoğaltma seti, varsayılan bağlantı noktası 27017'yi kullanan m1, m2 ve m3 olmak üzere üç üyeden oluşuyorsa, bağlantıyı aşağıdaki gibi test etmelisiniz:
m1'de:
mongosh --host m2 --port 27017 mongosh --host m3 --port 27017m2'de:
mongosh --host m1 --port 27017 mongosh --host m3 --port 27017m3'te:
mongosh --host m1 --port 27017 mongosh --host m2 --port 27017 Herhangi bir yöndeki herhangi bir bağlantı başarısız olursa, güvenlik duvarı yapılandırmanızı kontrol etmeniz ve bağlantılara izin verecek şekilde yeniden yapılandırmanız gerekir.
Anahtar Dosyası Kimlik Doğrulaması ile Güvenli İletişim Sağlama
Varsayılan olarak, MongoDB'deki anahtar dosyası kimlik doğrulaması, salted sınama yanıtı kimlik doğrulama mekanizmasına (SCRAM) dayanır. Bunu yapmak için MongoDB, belirli MongoDB örneğinin bildiği kullanıcı adı, parola ve kimlik doğrulama veritabanının bir kombinasyonunu içeren, kullanıcının sağladığı kimlik bilgilerini okumalı ve doğrulamalıdır. Bu, veritabanına bağlanırken bir parola sağlayan kullanıcıların kimliğini doğrulamak için kullanılan tam mekanizmadır.
MongoDB'de kimlik doğrulamayı etkinleştirdiğinizde, çoğaltma kümesi için Rol Tabanlı Erişim Kontrolü (RBAC) otomatik olarak etkinleştirilir ve kullanıcıya, veritabanı kaynaklarına erişimini belirleyen bir veya daha fazla rol verilir. RBAC etkinleştirildiğinde, yalnızca uygun ayrıcalıklara sahip kimliği doğrulanmış geçerli Mongo kullanıcısının sistemdeki kaynaklara erişebileceği anlamına gelir.
Anahtar dosyası, kümedeki her üye için paylaşılan bir parola görevi görür. Bu, çoğaltma kümesindeki her mongod örneğinin, dağıtımdaki diğer üyelerin kimliğini doğrulamak için anahtar dosyasının içeriğini paylaşılan parola olarak kullanmasını sağlar.
Yalnızca doğru anahtar dosyasına sahip mongod örnekleri çoğaltma kümesine katılabilir. Bir anahtarın uzunluğu 6 ile 1024 karakter arasında olmalıdır ve yalnızca base64 kümesindeki karakterleri içerebilir. Lütfen MongoDB'nin anahtarları okurken boşluk karakterlerini çıkardığını unutmayın.
Çeşitli yöntemler kullanarak bir anahtar dosyası oluşturabilirsiniz . Bu öğreticide, paylaşılan bir parola olarak kullanmak üzere karmaşık bir 1024-rastgele karakter dizisi oluşturmak için openssl kullanıyoruz. It then uses chmod to change file permissions to provide read permissions for the file owner only. Avoid storing the keyfile on storage mediums that can be easily disconnected from the hardware hosting the mongod instances, such as a USB drive or a network-attached storage device. Below is the command to generate a keyfile:
openssl rand -base64 756 > <path-to-keyfile> chmod 400 <path-to-keyfile>Next, copy the keyfile to each replica set member . Make sure that the user running the mongod instances is the owner of the file and can access the keyfile. After you've done the above, shut down all members of the replica set starting with the secondaries. Once all the secondaries are offline, you may go ahead and shut down the primary. It's essential to follow this order so as to prevent potential rollbacks. Now shut down the mongod instance by running the following command:
use admin db.shutdownServer()After the command is run, all members of the replica set will be offline. Now, restart each member of the replica set with access control enabled .
For each member of the replica set, start the mongod instance with either the security.keyFile configuration file setting or the --keyFile command-line option.
If you're using a configuration file, set
- security.keyFile to the keyfile's path, and
- replication.replSetName to the replica set name.
security: keyFile: <path-to-keyfile> replication: replSetName: <replicaSetName> net: bindIp: localhost,<hostname(s)|ip address(es)>Start the mongod instance using the configuration file:
mongod --config <path-to-config-file>If you're using the command line options, start the mongod instance with the following options:
- –keyFile set to the keyfile's path, and
- –replSet set to the replica set name.
mongod --keyFile <path-to-keyfile> --replSet <replicaSetName> --bind_ip localhost,<hostname(s)|ip address(es)>You can include additional options as required for your configuration. For instance, if you wish remote clients to connect to your deployment or your deployment members are run on different hosts, specify the –bind_ip. For more information, see Localhost Binding Compatibility Changes.
Next, connect to a member of the replica set over the localhost interface . You must run mongosh on the same physical machine as the mongod instance. This interface is only available when no users have been created for the deployment and automatically closes after the creation of the first user.
We then initiate the replica set. From mongosh, run the rs.initiate() method:
rs.initiate( { _id: "myReplSet", members: [ { _id: 0, host: "mongo1:27017" }, { _id: 1, host: "mongo2:27017" }, { _id: 2, host: "mongo3:27017" } ] } ) As discussed before, this method elects one of the members to be the primary member of the replica set. To locate the primary member, use rs.status() . Connect to the primary before continuing.
Now, create the user administrator . You can add a user using the db.createUser() method. Make sure that the user should have at least the userAdminAnyDatabase role on the admin database.
The following example creates the user 'batman' with the userAdminAnyDatabase role on the admin database:
admin = db.getSiblingDB("admin") admin.createUser( { user: "batman", pwd: passwordPrompt(), // or cleartext password roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] } )Enter the password that was created earlier when prompted.
Next, you must authenticate as the user administrator . To do so, use db.auth() to authenticate. For example:
db.getSiblingDB(“admin”).auth(“batman”, passwordPrompt()) // or cleartext password
Alternatively, you can connect a new mongosh instance to the primary replica set member using the -u <username> , -p <password> , and the --authenticationDatabase parameters.
mongosh -u "batman" -p --authenticationDatabase "admin" Even if you do not specify the password in the -p command-line field, mongosh prompts for the password.
Lastly, create the cluster administrator . The clusterAdmin role grants access to replication operations, such as configuring the replica set.
Let's create a cluster administrator user and assign the clusterAdmin role in the admin database:
db.getSiblingDB("admin").createUser( { "user": "robin", "pwd": passwordPrompt(), // or cleartext password roles: [ { "role" : "clusterAdmin", "db" : "admin" } ] } )Enter the password when prompted.
If you wish to, you may create additional users to allow clients and interact with the replica set.
And voila! You have successfully enabled keyfile authentication!
Özet
Replication has been an essential requirement when it comes to databases, especially as more businesses scale up. It widely improves the performance, data security, and availability of the system. Speaking of performance, it is pivotal for your WordPress database to monitor performance issues and rectify them in the nick of time, for instance, with Kinsta APM, Jetpack, and Freshping to name a few.
Replication helps ensure data protection across multiple servers and prevents your servers from suffering from heavy downtime(or even worse – losing your data entirely). In this article, we covered the creation of a replica set and some troubleshooting tips along with the importance of replication. Do you use MongoDB replication for your business and has it proven to be useful to you? Let us know in the comment section below!