
การจำลองแบบ PostgreSQL: คู่มือที่ครอบคลุม
เผยแพร่แล้ว: 2022-08-11ตามที่เจ้าของไซต์จะบอกคุณ การสูญเสียข้อมูลและการหยุดทำงาน แม้จะอยู่ในปริมาณที่น้อยที่สุด อาจเป็นหายนะได้ พวกเขาสามารถโจมตีโดยไม่ได้เตรียมตัวไว้ได้ตลอดเวลา ส่งผลให้ประสิทธิภาพการทำงานลดลง ความสามารถในการเข้าถึง และความมั่นใจในผลิตภัณฑ์ลดลง
เพื่อปกป้องความสมบูรณ์ของไซต์ของคุณ จำเป็นต้องสร้างการป้องกันจากความเป็นไปได้ของการหยุดทำงานหรือการสูญหายของข้อมูล
นั่นคือที่มาของการจำลองข้อมูล
การจำลองข้อมูลเป็นกระบวนการสำรองข้อมูลอัตโนมัติ โดยข้อมูลของคุณจะถูกคัดลอกซ้ำๆ จากฐานข้อมูลหลักไปยังตำแหน่งอื่นที่อยู่ห่างไกลเพื่อความปลอดภัย เป็นเทคโนโลยีที่สำคัญสำหรับไซต์หรือแอปใดๆ ที่รันเซิร์ฟเวอร์ฐานข้อมูล คุณยังสามารถใช้ประโยชน์จากฐานข้อมูลที่จำลองแบบเพื่อประมวลผล SQL แบบอ่านอย่างเดียว ซึ่งช่วยให้สามารถเรียกใช้กระบวนการเพิ่มเติมภายในระบบได้
การตั้งค่าการจำลองแบบระหว่างสองฐานข้อมูลมีความทนทานต่อข้อผิดพลาดต่ออุบัติเหตุที่ไม่คาดคิด ถือเป็นกลยุทธ์ที่ดีที่สุดในการบรรลุความพร้อมใช้งานสูงในช่วงที่เกิดภัยพิบัติ
ในบทความนี้ เราจะเจาะลึกถึงกลยุทธ์ต่างๆ ที่นักพัฒนาแบ็กเอนด์สามารถนำไปใช้เพื่อการจำลองแบบ PostgreSQL ได้อย่างราบรื่น
การจำลองแบบ PostgreSQL คืออะไร?
การจำลองแบบ PostgreSQL ถูกกำหนดให้เป็นกระบวนการคัดลอกข้อมูลจากเซิร์ฟเวอร์ฐานข้อมูล PostgreSQL ไปยังเซิร์ฟเวอร์อื่น เซิร์ฟเวอร์ฐานข้อมูลต้นทางเรียกอีกอย่างว่าเซิร์ฟเวอร์ "หลัก" ในขณะที่เซิร์ฟเวอร์ฐานข้อมูลที่ได้รับข้อมูลที่คัดลอกจะเรียกว่าเซิร์ฟเวอร์ "แบบจำลอง"
ฐานข้อมูล PostgreSQL ใช้โมเดลการจำลองแบบตรงไปตรงมา โดยที่การเขียนทั้งหมดไปที่โหนดหลัก โหนดหลักสามารถใช้การเปลี่ยนแปลงเหล่านี้และเผยแพร่ไปยังโหนดรองได้
ความล้มเหลวอัตโนมัติคืออะไร?
เมื่อการจำลองแบบการสตรีมทางกายภาพได้รับการกำหนดค่าใน PostgreSQL แล้ว การเฟลโอเวอร์อาจเกิดขึ้นได้หากเซิร์ฟเวอร์หลักของฐานข้อมูลล้มเหลว เฟลโอเวอร์ใช้เพื่อกำหนดกระบวนการกู้คืน ซึ่งอาจใช้เวลาสักครู่ เนื่องจากไม่มีเครื่องมือในตัวเพื่อกำหนดขอบเขตความล้มเหลวของเซิร์ฟเวอร์
คุณไม่จำเป็นต้องพึ่งพา PostgreSQL สำหรับเฟลโอเวอร์ มีเครื่องมือเฉพาะที่อนุญาตให้เฟลโอเวอร์อัตโนมัติและสลับไปยังโหมดสแตนด์บายโดยอัตโนมัติ ซึ่งช่วยลดเวลาหยุดทำงานของฐานข้อมูล
ด้วยการตั้งค่าการจำลองแบบเฟลโอเวอร์ คุณทั้งหมดแต่รับประกันความพร้อมใช้งานสูงโดยทำให้แน่ใจว่าสแตนด์บายจะพร้อมใช้งานหากเซิร์ฟเวอร์หลักเคยยุบ
ประโยชน์ของการใช้การจำลองแบบ PostgreSQL
ต่อไปนี้คือประโยชน์หลักบางประการของการใช้ประโยชน์จากการจำลองแบบ PostgreSQL:
- การย้ายข้อมูล : คุณสามารถใช้การจำลองแบบ PostgreSQL สำหรับการย้ายข้อมูลผ่านการเปลี่ยนแปลงฮาร์ดแวร์เซิร์ฟเวอร์ฐานข้อมูลหรือผ่านการปรับใช้ระบบ
- ความทนทานต่อข้อผิดพลาด : หากเซิร์ฟเวอร์หลักล้มเหลว เซิร์ฟเวอร์สำรองสามารถทำหน้าที่เป็นเซิร์ฟเวอร์ได้ เนื่องจากข้อมูลที่มีอยู่สำหรับทั้งเซิร์ฟเวอร์หลักและเซิร์ฟเวอร์สำรองจะเหมือนกัน
- ประสิทธิภาพการประมวลผลธุรกรรมออนไลน์ (OLTP) : คุณสามารถปรับปรุงเวลาในการประมวลผลธุรกรรมและเวลาการสืบค้นของระบบ OLTP ได้โดยการลบการรายงานการโหลดการสืบค้น เวลาประมวลผลธุรกรรมคือระยะเวลาที่ใช้ในการดำเนินการค้นหาที่กำหนดก่อนที่ธุรกรรมจะเสร็จสิ้น
- การทดสอบระบบแบบขนาน : ขณะอัปเกรดระบบใหม่ คุณต้องตรวจสอบให้แน่ใจว่าระบบใช้งานได้ดีกับข้อมูลที่มีอยู่ ดังนั้นจึงจำเป็นต้องทดสอบกับสำเนาฐานข้อมูลที่ใช้งานจริงก่อนปรับใช้
วิธีการทำงานของการจำลองแบบ PostgreSQL
โดยทั่วไป ผู้คนเชื่อว่าเมื่อคุณกำลังใช้งานสถาปัตยกรรมหลักและรอง มีเพียงวิธีเดียวในการตั้งค่าการสำรองข้อมูลและการจำลอง แต่การปรับใช้ PostgreSQL ปฏิบัติตามหนึ่งในสามวิธีต่อไปนี้:
- การจำลองระดับวอลุ่ม เพื่อทำซ้ำที่ชั้นการจัดเก็บจากโหนดหลักไปยังโหนดรอง ตามด้วยการสำรองข้อมูลไปยังที่เก็บข้อมูล blob/S3
- การจำลองแบบสตรีม PostgreSQL เพื่อจำลองข้อมูลจากโหนดหลักไปยังโหนดรอง ตามด้วยการสำรองข้อมูลไปยังที่เก็บข้อมูล blob/S3
- การสำรองข้อมูลส่วนเพิ่ม จากโหนดหลักไปยัง S3 ในขณะที่สร้างโหนดรองใหม่จาก S3 เมื่อโหนดรองอยู่ในบริเวณใกล้เคียงกับโหนดหลัก คุณสามารถเริ่มสตรีมจากโหนดหลักได้
วิธีที่ 1: สตรีมมิ่ง
การจำลองแบบสตรีม PostgreSQL หรือที่เรียกว่าการจำลองแบบ WAL สามารถตั้งค่าได้อย่างราบรื่นหลังจากติดตั้ง PostgreSQL บนเซิร์ฟเวอร์ทั้งหมด วิธีการจำลองแบบนี้ขึ้นอยู่กับการย้ายไฟล์ WAL จากฐานข้อมูลหลักไปยังฐานข้อมูลเป้าหมาย
คุณสามารถใช้การจำลองการสตรีม PostgreSQL ได้โดยใช้การกำหนดค่าหลักรอง เซิร์ฟเวอร์หลักคืออินสแตนซ์หลักที่จัดการฐานข้อมูลหลักและการดำเนินการทั้งหมด เซิร์ฟเวอร์รองทำหน้าที่เป็นอินสแตนซ์เสริมและดำเนินการเปลี่ยนแปลงทั้งหมดที่ทำกับฐานข้อมูลหลักด้วยตัวมันเอง สร้างสำเนาที่เหมือนกันในกระบวนการ เซิร์ฟเวอร์หลักคือเซิร์ฟเวอร์อ่าน/เขียน ในขณะที่เซิร์ฟเวอร์รองเป็นแบบอ่านอย่างเดียว
สำหรับวิธีนี้ คุณต้องกำหนดค่าทั้งโหนดหลักและโหนดสแตนด์บาย ส่วนต่อไปนี้จะอธิบายขั้นตอนที่เกี่ยวข้องในการกำหนดค่าได้อย่างง่ายดาย
การกำหนดค่าโหนดหลัก
คุณสามารถกำหนดค่าโหนดหลักสำหรับการจำลองแบบสตรีมมิงได้โดยทำตามขั้นตอนต่อไปนี้:
ขั้นตอนที่ 1: เริ่มต้นฐานข้อมูล
ในการเริ่มต้นฐานข้อมูล คุณสามารถใช้คำสั่ง initidb utility ถัดไป คุณสามารถสร้างผู้ใช้ใหม่ที่มีสิทธิ์ในการจำลองแบบโดยใช้คำสั่งต่อไปนี้:
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';ผู้ใช้จะต้องระบุรหัสผ่านและชื่อผู้ใช้สำหรับข้อความค้นหาที่กำหนด คีย์เวิร์ดการจำลองแบบใช้เพื่อให้สิทธิ์ที่จำเป็นแก่ผู้ใช้ แบบสอบถามตัวอย่างจะมีลักษณะดังนี้:
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'ขั้นตอนที่ 2: กำหนดค่าคุณสมบัติการสตรีม
ถัดไป คุณสามารถกำหนดค่าคุณสมบัติการสตรีมด้วยไฟล์การกำหนดค่า PostgreSQL ( postgresql.conf ) ที่สามารถแก้ไขได้ดังนี้:
wal_level = logical wal_log_hints = on max_wal_senders = 8 max_wal_size = 1GB hot_standby = onต่อไปนี้เป็นพื้นหลังเล็กน้อยเกี่ยวกับพารามิเตอร์ที่ใช้ในตัวอย่างก่อนหน้า:
-
wal_log_hints: พารามิเตอร์นี้จำเป็นสำหรับความสามารถpg_rewindที่มีประโยชน์เมื่อเซิร์ฟเวอร์สแตนด์บายไม่ซิงค์กับเซิร์ฟเวอร์หลัก -
wal_level: คุณสามารถใช้พารามิเตอร์นี้เพื่อเปิดใช้งานการจำลองการสตรีม PostgreSQL ด้วยค่าที่เป็นไปได้รวมถึงminimal,replicaหรือlogical -
max_wal_size: สามารถใช้เพื่อระบุขนาดของไฟล์ WAL ที่สามารถเก็บไว้ในไฟล์บันทึก -
hot_standby: คุณสามารถใช้พารามิเตอร์นี้สำหรับการเชื่อมต่อแบบ read-on กับส่วนรองเมื่อตั้งค่าเป็น ON -
max_wal_senders: คุณสามารถใช้max_wal_sendersเพื่อระบุจำนวนสูงสุดของการเชื่อมต่อพร้อมกันที่สามารถสร้างได้ด้วยเซิร์ฟเวอร์สแตนด์บาย
ขั้นตอนที่ 3: สร้างรายการใหม่
หลังจากที่คุณแก้ไขพารามิเตอร์ในไฟล์ postgresql.conf แล้ว รายการการจำลองแบบใหม่ในไฟล์ pg_hba.conf สามารถอนุญาตให้เซิร์ฟเวอร์สร้างการเชื่อมต่อระหว่างกันเพื่อการจำลองแบบ
โดยปกติแล้ว คุณจะพบไฟล์นี้ในไดเร็กทอรีข้อมูลของ PostgreSQL คุณสามารถใช้ข้อมูลโค้ดต่อไปนี้เพื่อสิ่งเดียวกัน:
host replication rep_user IPaddress md5 เมื่อข้อมูลโค้ดถูกดำเนินการ เซิร์ฟเวอร์หลักจะอนุญาตให้ผู้ใช้ที่ชื่อ rep_user เชื่อมต่อและทำหน้าที่เป็นเซิร์ฟเวอร์สำรองโดยใช้ IP ที่ระบุสำหรับการจำลองแบบ ตัวอย่างเช่น:
host replication rep_user 192.168.0.22/32 md5การกำหนดค่าโหนดสแตนด์บาย
ในการกำหนดค่าโหนดสแตนด์บายสำหรับการจำลองแบบสตรีมมิง ให้ทำตามขั้นตอนเหล่านี้:
ขั้นตอนที่ 1: สำรองข้อมูลโหนดหลัก
ในการกำหนดค่าโหนดสแตนด์บาย ให้ใช้ประโยชน์จากยูทิลิตี pg_basebackup เพื่อสร้างการสำรองข้อมูลของโหนดหลัก ซึ่งจะทำหน้าที่เป็นจุดเริ่มต้นสำหรับโหนดสแตนด์บาย คุณสามารถใช้ยูทิลิตี้นี้กับไวยากรณ์ต่อไปนี้:
pg_basebackp -D -h -X stream -c fast -U rep_user -Wพารามิเตอร์ที่ใช้ในไวยากรณ์ที่กล่าวถึงข้างต้นมีดังนี้:
-
-h: คุณสามารถใช้สิ่งนี้เพื่อพูดถึงโฮสต์หลัก -
-D: พารามิเตอร์นี้ระบุไดเร็กทอรีที่คุณกำลังใช้งานอยู่ -
-C: คุณสามารถใช้สิ่งนี้เพื่อกำหนดจุดตรวจ -
-X: พารามิเตอร์นี้สามารถใช้เพื่อรวมไฟล์บันทึกธุรกรรมที่จำเป็น -
-W: คุณสามารถใช้พารามิเตอร์นี้เพื่อขอรหัสผ่านจากผู้ใช้ก่อนที่จะเชื่อมโยงไปยังฐานข้อมูล
ขั้นตอนที่ 2: ตั้งค่าไฟล์การกำหนดค่าการจำลองแบบ
ถัดไป คุณต้องตรวจสอบว่ามีไฟล์การกำหนดค่าการจำลองแบบอยู่หรือไม่ หากไม่เป็นเช่นนั้น คุณสามารถสร้างไฟล์การกำหนดค่าการจำลองแบบเป็น recovery.conf
คุณควรสร้างไฟล์นี้ในไดเร็กทอรีข้อมูลของการติดตั้ง PostgreSQL คุณสามารถสร้างได้โดยอัตโนมัติโดยใช้ตัวเลือก -R ภายในยูทิลิตี pg_basebackup
ไฟล์ recovery.conf ควรมีคำสั่งต่อไปนี้:
standby_mode = 'เปิด'
Primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<รหัสผ่าน> application_name=”host_name”'
recovery_target_timeline = 'ล่าสุด'
พารามิเตอร์ที่ใช้ในคำสั่งดังกล่าวมีดังนี้:
-
primary_conninfo: คุณสามารถใช้สิ่งนี้เพื่อสร้างการเชื่อมต่อระหว่างเซิร์ฟเวอร์หลักและเซิร์ฟเวอร์รองโดยใช้ประโยชน์จากสตริงการเชื่อมต่อ -
standby_mode: พารามิเตอร์นี้อาจทำให้เซิร์ฟเวอร์หลักเริ่มทำงานเป็นสแตนด์บายเมื่อเปิดเครื่อง -
recovery_target_timeline: คุณสามารถใช้สิ่งนี้เพื่อตั้งเวลาการกู้คืน
ในการตั้งค่าการเชื่อมต่อ คุณต้องระบุชื่อผู้ใช้ ที่อยู่ IP และรหัสผ่านเป็นค่าสำหรับพารามิเตอร์ primary_conninfo ตัวอย่างเช่น:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'ขั้นตอนที่ 3: รีสตาร์ทเซิร์ฟเวอร์รอง
สุดท้าย คุณสามารถรีสตาร์ทเซิร์ฟเวอร์สำรองเพื่อดำเนินการตั้งค่าคอนฟิกให้เสร็จสิ้น
อย่างไรก็ตาม การจำลองแบบสตรีมมิงมีความท้าทายหลายประการ เช่น:
- ไคลเอนต์ PostgreSQL ต่างๆ (เขียนด้วยภาษาการเขียนโปรแกรมต่างกัน) สนทนาด้วยปลายทางเดียว เมื่อโหนดหลักล้มเหลว ไคลเอ็นต์เหล่านี้จะลองใช้ชื่อ DNS หรือ IP เดิมซ้ำอีกครั้ง ซึ่งจะทำให้แอปพลิเคชันมองเห็นการเฟลโอเวอร์ได้
- การจำลองแบบ PostgreSQL ไม่ได้มาพร้อมกับการเฟลโอเวอร์และการตรวจสอบในตัว เมื่อโหนดหลักล้มเหลว คุณต้องเลื่อนระดับโหนดรองเป็นโหนดหลักใหม่ โปรโมชั่นนี้ต้องดำเนินการในลักษณะที่ลูกค้าเขียนไปยังโหนดหลักเพียงโหนดเดียว และพวกเขาไม่สังเกตเห็นความไม่สอดคล้องของข้อมูล
- PostgreSQL จำลองสถานะทั้งหมด เมื่อคุณต้องการพัฒนาโหนดรองใหม่ โหนดรองจำเป็นต้องสรุปประวัติการเปลี่ยนแปลงสถานะทั้งหมดจากโหนดหลัก ซึ่งใช้ทรัพยากรมาก และทำให้ค่าใช้จ่ายในการกำจัดโหนดในส่วนหัวออกและสร้างโหนดใหม่มีค่าใช้จ่ายสูง
วิธีที่ 2: อุปกรณ์บล็อกจำลอง
วิธีการของอุปกรณ์บล็อกที่จำลองแบบขึ้นอยู่กับการมิเรอร์ดิสก์ (หรือที่เรียกว่าการจำลองแบบโวลุ่ม) ในแนวทางนี้ การเปลี่ยนแปลงจะถูกเขียนไปยังวอลุ่มแบบถาวรซึ่งได้รับการมิเรอร์แบบซิงโครนัสไปยังโวลุ่มอื่น
ประโยชน์เพิ่มเติมของแนวทางนี้คือความเข้ากันได้และความทนทานของข้อมูลในสภาพแวดล้อมคลาวด์ที่มีฐานข้อมูลเชิงสัมพันธ์ทั้งหมด รวมถึง PostgreSQL, MySQL และ SQL Server เป็นต้น
อย่างไรก็ตาม วิธีการมิเรอร์ดิสก์สำหรับการจำลองแบบ PostgreSQL ต้องการให้คุณทำซ้ำทั้งบันทึก WAL และข้อมูลตาราง เนื่องจากตอนนี้การเขียนแต่ละครั้งไปยังฐานข้อมูลต้องผ่านเครือข่ายแบบซิงโครนัส คุณจึงไม่อาจสูญเสียไบต์เดียวได้ เนื่องจากอาจทำให้ฐานข้อมูลของคุณอยู่ในสถานะเสียหายได้
วิธีนี้มักจะใช้ประโยชน์ได้โดยใช้ Azure PostgreSQL และ Amazon RDS
วิธีที่ 3: WAL
WAL ประกอบด้วยไฟล์เซ็กเมนต์ (16 MB โดยค่าเริ่มต้น) แต่ละส่วนมีหนึ่งระเบียนขึ้นไป บันทึกลำดับบันทึก (LSN) เป็นตัวชี้ไปยังระเบียนใน WAL เพื่อให้คุณทราบตำแหน่ง/ตำแหน่งที่บันทึกระเบียนในไฟล์บันทึก
เซิร์ฟเวอร์สแตนด์บายใช้ประโยชน์จากเซ็กเมนต์ WAL — หรือที่เรียกว่า XLOGS ในคำศัพท์เฉพาะของ PostgreSQL — เพื่อทำซ้ำการเปลี่ยนแปลงอย่างต่อเนื่องจากเซิร์ฟเวอร์หลัก คุณสามารถใช้การบันทึกแบบเขียนล่วงหน้าเพื่อให้มีความทนทานและอะตอมมิกใน DBMS โดยการจัดลำดับกลุ่มข้อมูลแบบไบต์-อาเรย์ (แต่ละรายการมี LSN ที่ไม่ซ้ำกัน) ไปยังที่จัดเก็บข้อมูลที่เสถียรก่อนที่จะนำไปใช้กับฐานข้อมูล
การใช้การกลายพันธุ์กับฐานข้อมูลอาจนำไปสู่การดำเนินการต่างๆ ของระบบไฟล์ คำถามที่เกี่ยวข้องที่เกิดขึ้นคือฐานข้อมูลสามารถรับรอง atomicity ได้อย่างไรในกรณีที่เซิร์ฟเวอร์ล้มเหลวเนื่องจากไฟฟ้าดับในขณะที่อยู่ระหว่างการอัปเดตระบบไฟล์ เมื่อเริ่มระบบฐานข้อมูล จะเริ่มกระบวนการเริ่มต้นหรือเล่นซ้ำซึ่งสามารถอ่านเซ็กเมนต์ WAL ที่มีอยู่และเปรียบเทียบกับ LSN ที่จัดเก็บไว้ในหน้าข้อมูลทุกหน้า (ทุกหน้าข้อมูลจะถูกทำเครื่องหมายด้วย LSN ของเร็กคอร์ด WAL ล่าสุดที่ส่งผลต่อเพจ)
บันทึกการจำลองตามการจัดส่ง (ระดับบล็อก)
การจำลองแบบสตรีมมิงจะปรับปรุงกระบวนการจัดส่งบันทึก ในทางตรงกันข้ามกับการรอสวิตช์ WAL เร็กคอร์ดจะถูกส่งเมื่อสร้าง ซึ่งจะช่วยลดความล่าช้าในการจำลองแบบ
การจำลองแบบสตรีมมิงยังสำคัญกว่าการบันทึกการจัดส่งเนื่องจากเซิร์ฟเวอร์สแตนด์บายเชื่อมโยงกับเซิร์ฟเวอร์หลักผ่านเครือข่ายโดยใช้โปรโตคอลการจำลองแบบ เซิร์ฟเวอร์หลักสามารถส่งบันทึก WAL ได้โดยตรงผ่านการเชื่อมต่อนี้โดยไม่ต้องพึ่งพาสคริปต์ที่ผู้ใช้ปลายทางให้มา
บันทึกการจำลองแบบตามการจัดส่ง (ระดับไฟล์)
การจัดส่งบันทึกถูกกำหนดให้เป็นการคัดลอกไฟล์บันทึกไปยังเซิร์ฟเวอร์ PostgreSQL อื่นเพื่อสร้างเซิร์ฟเวอร์สำรองอื่นโดยการเล่นไฟล์ WAL ซ้ำ เซิร์ฟเวอร์นี้ได้รับการกำหนดค่าให้ทำงานในโหมดการกู้คืน และมีวัตถุประสงค์เพียงเพื่อใช้ไฟล์ WAL ใหม่เมื่อปรากฏขึ้น
เซิร์ฟเวอร์รองนี้จะกลายเป็นข้อมูลสำรองที่อบอุ่นของเซิร์ฟเวอร์ PostgreSQL หลัก นอกจากนี้ยังสามารถกำหนดค่าให้เป็น Read Replica ซึ่งสามารถเสนอการสืบค้นแบบอ่านอย่างเดียว หรือที่เรียกว่า Hot Standby
การเก็บถาวร WAL อย่างต่อเนื่อง
การทำสำเนาไฟล์ WAL ที่ถูกสร้างขึ้นในตำแหน่งอื่นที่ไม่ใช่ไดเร็กทอรีย่อย pg_wal เพื่อเก็บถาวรนั้นเรียกว่า WAL archive PostgreSQL จะเรียกสคริปต์ที่ผู้ใช้มอบให้เพื่อเก็บถาวร ทุกครั้งที่มีการสร้างไฟล์ WAL
สคริปต์สามารถใช้คำสั่ง scp เพื่อทำซ้ำไฟล์ไปยังตำแหน่งอย่างน้อยหนึ่งตำแหน่ง เช่น การเมาต์ NFS เมื่อเก็บถาวรแล้ว ไฟล์เซ็กเมนต์ WAL สามารถใช้ประโยชน์เพื่อกู้คืนฐานข้อมูล ณ เวลาที่กำหนด
การกำหนดค่าตามบันทึกอื่นๆ ได้แก่:
- การจำลองแบบซิงโครนัส : ก่อนที่ทุกธุรกรรมการจำลองแบบซิงโครนัสจะถูกสร้างขึ้น เซิร์ฟเวอร์หลักจะรอจนกว่าสแตนด์บายจะยืนยันว่าได้รับข้อมูล ประโยชน์ของการกำหนดค่านี้คือไม่มีข้อขัดแย้งใดๆ ที่เกิดจากกระบวนการเขียนแบบคู่ขนาน
- การจำลองแบบหลายมาสเตอร์แบบซิงโครนัส : ที่นี่ ทุกเซิร์ฟเวอร์สามารถยอมรับคำขอเขียน และข้อมูลที่แก้ไขจะถูกส่งจากเซิร์ฟเวอร์เดิมไปยังเซิร์ฟเวอร์อื่นทุกเครื่องก่อนทำธุรกรรมแต่ละรายการ มันใช้ประโยชน์จากโปรโตคอล 2PC และปฏิบัติตามกฎทั้งหมดหรือไม่มีเลย
รายละเอียดโปรโตคอลสตรีมมิ่ง WAL
กระบวนการที่เรียกว่าตัวรับ WAL ซึ่งทำงานบนเซิร์ฟเวอร์สแตนด์บาย ใช้ประโยชน์จากรายละเอียดการเชื่อมต่อที่ให้ไว้ในพารามิเตอร์ primary_conninfo ของ recovery.conf และเชื่อมต่อกับเซิร์ฟเวอร์หลักโดยใช้การเชื่อมต่อ TCP/IP
ในการเริ่มการจำลองแบบสตรีมมิง ส่วนหน้าสามารถส่งพารามิเตอร์การจำลองแบบภายในข้อความเริ่มต้นได้ ค่าบูลีนเป็น true, yes, 1 หรือ ON ช่วยให้แบ็กเอนด์รู้ว่าจำเป็นต้องเข้าสู่โหมด walsender การจำลองแบบกายภาพ
ผู้ส่ง WAL เป็นอีกกระบวนการหนึ่งที่ทำงานบนเซิร์ฟเวอร์หลักและมีหน้าที่ส่งบันทึก WAL ไปยังเซิร์ฟเวอร์สำรองเมื่อถูกสร้างขึ้น ตัวรับ WAL จะบันทึกเร็กคอร์ด WAL ใน WAL ราวกับว่าถูกสร้างขึ้นโดยกิจกรรมไคลเอนต์ของไคลเอนต์ที่เชื่อมต่อในเครื่อง
เมื่อเร็กคอร์ด WAL ไปถึงไฟล์เซ็กเมนต์ WAL เซิร์ฟเวอร์สแตนด์บายจะเล่น WAL ซ้ำอย่างต่อเนื่องเพื่อให้ไฟล์หลักและสแตนด์บายเป็นข้อมูลล่าสุด

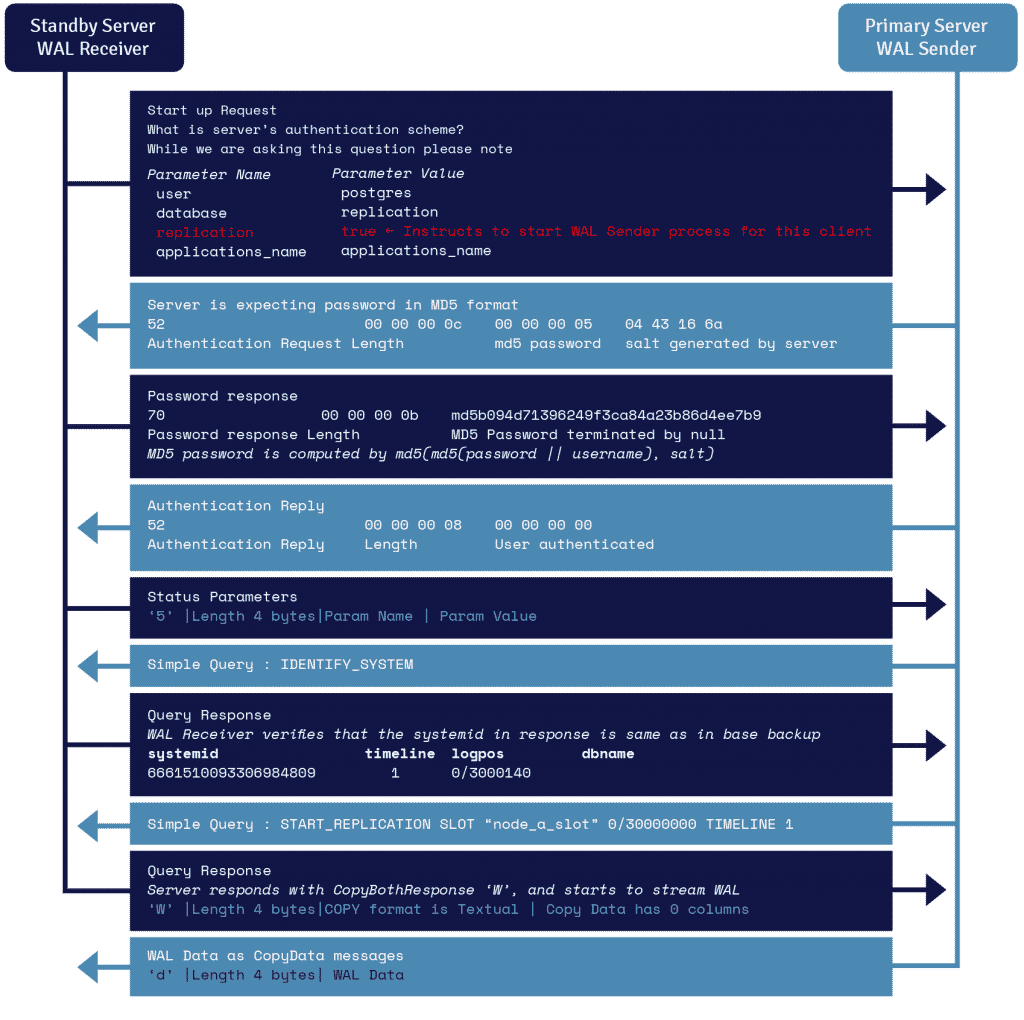
องค์ประกอบของการจำลองแบบ PostgreSQL
ในส่วนนี้ คุณจะเข้าใจลึกซึ้งยิ่งขึ้นเกี่ยวกับแบบจำลองที่ใช้กันทั่วไป (การจำลองแบบต้นแบบเดียวและหลายต้นแบบ) ประเภท (การจำลองแบบทางกายภาพและเชิงตรรกะ) และโหมด (แบบซิงโครนัสและแบบอะซิงโครนัส) ของการจำลองแบบ PostgreSQL
แบบจำลองของการจำลองฐานข้อมูล PostgreSQL
ความสามารถในการปรับขนาดหมายถึงการเพิ่มทรัพยากร/ฮาร์ดแวร์ให้กับโหนดที่มีอยู่เพื่อเพิ่มความสามารถของฐานข้อมูลในการจัดเก็บและประมวลผลข้อมูลมากขึ้น ซึ่งสามารถทำได้ทั้งแนวนอนและแนวตั้ง การจำลองแบบ PostgreSQL เป็นตัวอย่างของความสามารถในการปรับขนาดในแนวนอนซึ่งยากต่อการติดตั้งมากกว่าความสามารถในการปรับขยายในแนวตั้ง เราสามารถบรรลุความสามารถในการปรับขยายในแนวนอนโดยส่วนใหญ่โดยการจำลองแบบต้นแบบเดียว (SMR) และการจำลองแบบหลายต้นแบบ (MMR)
การจำลองแบบ Single-master ช่วยให้ข้อมูลสามารถแก้ไขได้บนโหนดเดียวเท่านั้น และการปรับเปลี่ยนเหล่านี้จะถูกจำลองแบบไปยังโหนดอย่างน้อยหนึ่งโหนด ตารางที่จำลองแบบในฐานข้อมูลแบบจำลองไม่ได้รับอนุญาตให้ยอมรับการเปลี่ยนแปลงใดๆ ยกเว้นการเปลี่ยนแปลงจากเซิร์ฟเวอร์หลัก แม้ว่าจะเป็นเช่นนั้น การเปลี่ยนแปลงจะไม่ถูกจำลองกลับไปยังเซิร์ฟเวอร์หลัก
โดยส่วนใหญ่แล้ว SMR ก็เพียงพอแล้วสำหรับแอปพลิเคชัน เนื่องจากการกำหนดค่าและจัดการนั้นไม่ซับซ้อน และไม่มีโอกาสเกิดข้อขัดแย้ง การจำลองแบบต้นแบบเดียวยังเป็นแบบทิศทางเดียว เนื่องจากข้อมูลการจำลองแบบไหลในทิศทางเดียวเป็นหลัก จากฐานข้อมูลหลักไปยังฐานข้อมูลแบบจำลอง
ในบางกรณี SMR เพียงอย่างเดียวอาจไม่เพียงพอ และคุณอาจต้องใช้ MMR MMR อนุญาตให้โหนดมากกว่าหนึ่งโหนดทำหน้าที่เป็นโหนดหลัก การเปลี่ยนแปลงแถวตารางในฐานข้อมูลหลักที่กำหนดมากกว่าหนึ่งรายการจะถูกจำลองแบบไปยังตารางคู่กันในฐานข้อมูลหลักอื่นๆ ทุกฐานข้อมูล ในรูปแบบนี้ มักใช้แผนการแก้ไขข้อขัดแย้งเพื่อหลีกเลี่ยงปัญหา เช่น คีย์หลักที่ซ้ำกัน
มีข้อดีบางประการในการใช้ MMR กล่าวคือ:
- ในกรณีที่โฮสต์ล้มเหลว โฮสต์อื่นยังสามารถให้บริการอัปเดตและแทรกได้
- โหนดหลักถูกกระจายออกไปในหลายตำแหน่ง ดังนั้นโอกาสของความล้มเหลวของโหนดหลักทั้งหมดจึงมีน้อยมาก
- ความสามารถในการใช้เครือข่ายบริเวณกว้าง (WAN) ของฐานข้อมูลหลักที่สามารถอยู่ใกล้กับกลุ่มลูกค้าตามภูมิศาสตร์ แต่ยังรักษาความสอดคล้องของข้อมูลทั่วทั้งเครือข่าย
อย่างไรก็ตาม ข้อเสียของการนำ MMR ไปใช้คือความซับซ้อนและความยากในการแก้ไขข้อขัดแย้ง
หลายสาขาและแอปพลิเคชันมีโซลูชัน MMR เนื่องจาก PostgreSQL ไม่รองรับโดยกำเนิด โซลูชันเหล่านี้อาจเป็นโอเพ่นซอร์ส ฟรี หรือจ่ายเงิน หนึ่งในส่วนขยายดังกล่าวคือการจำลองแบบสองทิศทาง (BDR) ซึ่งเป็นแบบอะซิงโครนัสและอิงตามฟังก์ชันการถอดรหัสเชิงตรรกะของ PostgreSQL
เนื่องจากแอปพลิเคชัน BDR เล่นธุรกรรมซ้ำบนโหนดอื่น การดำเนินการเล่นซ้ำอาจล้มเหลวหากมีข้อขัดแย้งระหว่างธุรกรรมที่กำลังใช้และธุรกรรมที่ตกลงบนโหนดที่รับ
ประเภทของการจำลองแบบ PostgreSQL
การจำลองแบบ PostgreSQL มีสองประเภท: การจำลองแบบลอจิคัลและฟิสิคัล
การดำเนินการ เชิงตรรกะ อย่างง่าย "initdb" จะดำเนินการทางกายภาพของการสร้างไดเร็กทอรีฐานสำหรับคลัสเตอร์ ในทำนองเดียวกัน การดำเนินการ เชิงตรรกะ อย่างง่าย “CREATE DATABASE” จะดำเนินการ ทางกายภาพ ของการสร้างไดเร็กทอรีย่อยในไดเร็กทอรีฐาน
การจำลองแบบทางกายภาพมักจะเกี่ยวข้องกับไฟล์และไดเร็กทอรี ไม่ทราบว่าไฟล์และไดเร็กทอรีเหล่านี้แสดงถึงอะไร วิธีการเหล่านี้ใช้เพื่อรักษาสำเนาทั้งหมดของข้อมูลทั้งหมดของคลัสเตอร์เดียว โดยทั่วไปแล้วจะอยู่บนเครื่องอื่น และทำที่ระดับระบบไฟล์หรือระดับดิสก์ และใช้ที่อยู่บล็อกที่แน่นอน
การจำลองแบบลอจิคัลเป็นวิธีการทำซ้ำเอนทิตีข้อมูลและการแก้ไขตามข้อมูลประจำตัวของการจำลองแบบ (โดยปกติคือคีย์หลัก) ไม่เหมือนกับการจำลองแบบทางกายภาพ โดยเกี่ยวข้องกับฐานข้อมูล ตาราง และการดำเนินการ DML และดำเนินการในระดับคลัสเตอร์ฐานข้อมูล ใช้รูปแบบการ เผยแพร่ และ สมัครรับข้อมูล โดยที่สมาชิกอย่างน้อยหนึ่งราย สมัคร รับข้อมูล สิ่งพิมพ์ อย่างน้อยหนึ่งรายการบนโหนด ผู้เผยแพร่
กระบวนการจำลองแบบเริ่มต้นโดยการถ่ายภาพสแน็ปช็อตของข้อมูลในฐานข้อมูลของผู้เผยแพร่ แล้วคัดลอกไปยังผู้สมัครสมาชิก ผู้สมัครสมาชิกดึงข้อมูลจากสิ่งพิมพ์ที่พวกเขาสมัครและอาจเผยแพร่ข้อมูลอีกครั้งในภายหลังเพื่ออนุญาตการจำลองแบบเรียงซ้อนหรือการกำหนดค่าที่ซับซ้อนมากขึ้น สมาชิกใช้ข้อมูลในลำดับเดียวกันกับผู้เผยแพร่เพื่อให้รับประกันความสอดคล้องของธุรกรรมสำหรับสิ่งพิมพ์ภายในการสมัครรับข้อมูลเดียวหรือที่เรียกว่าการจำลองแบบธุรกรรม
กรณีการใช้งานทั่วไปสำหรับการจำลองแบบลอจิคัลคือ:
- การส่งการเปลี่ยนแปลงที่เพิ่มขึ้นในฐานข้อมูลเดียว (หรือชุดย่อยของฐานข้อมูล) ไปยังสมาชิกตามที่เกิดขึ้น
- การแบ่งปันชุดย่อยของฐานข้อมูลระหว่างหลายฐานข้อมูล
- ทริกเกอร์การเปลี่ยนแปลงแต่ละรายการเมื่อมาถึงสมาชิก
- การรวมหลายฐานข้อมูลเป็นหนึ่งเดียว
- ให้การเข้าถึงข้อมูลที่จำลองแบบไปยังกลุ่มผู้ใช้ต่างๆ
ฐานข้อมูลสมาชิกทำงานในลักษณะเดียวกับอินสแตนซ์ PostgreSQL อื่น ๆ และสามารถใช้เป็นผู้เผยแพร่สำหรับฐานข้อมูลอื่น ๆ ได้โดยการกำหนดสิ่งพิมพ์
เมื่อการสมัครรับข้อมูลถือว่าเป็นแบบอ่านอย่างเดียว จะไม่มีข้อขัดแย้งใดๆ จากการสมัครรับข้อมูลเพียงครั้งเดียว ในทางกลับกัน หากมีการเขียนอื่นๆ โดยแอปพลิเคชันหรือโดยสมาชิกรายอื่นในชุดตารางเดียวกัน ความขัดแย้งอาจเกิดขึ้นได้
PostgreSQL รองรับกลไกทั้งสองพร้อมกัน การจำลองแบบลอจิกช่วยให้สามารถควบคุมทั้งการจำลองข้อมูลและการรักษาความปลอดภัยอย่างละเอียด
โหมดการจำลองแบบ
การจำลองแบบ PostgreSQL มีสองโหมดหลัก: แบบซิงโครนัสและอะซิงโครนัส การจำลองแบบซิงโครนัสช่วยให้สามารถเขียนข้อมูลไปยังทั้งเซิร์ฟเวอร์หลักและเซิร์ฟเวอร์รองได้ในเวลาเดียวกัน ในขณะที่การจำลองแบบอะซิงโครนัสช่วยให้มั่นใจได้ว่าข้อมูลจะถูกเขียนไปยังโฮสต์ก่อนแล้วจึงคัดลอกไปยังเซิร์ฟเวอร์รอง
ในการจำลองแบบโหมดซิงโครนัส ธุรกรรมบนฐานข้อมูลหลักจะถือว่าสมบูรณ์ก็ต่อเมื่อการเปลี่ยนแปลงเหล่านั้นถูกจำลองแบบไปยังแบบจำลองทั้งหมด เซิร์ฟเวอร์เรพพลิกาต้องพร้อมใช้งานตลอดเวลาเพื่อให้ธุรกรรมเสร็จสมบูรณ์บนเซิร์ฟเวอร์หลัก โหมดการจำลองแบบซิงโครนัสถูกใช้ในสภาพแวดล้อมของทรานแซคชันระดับไฮเอนด์ที่มีความต้องการเฟลโอเวอร์ทันที
ในโหมดอะซิงโครนัส ธุรกรรมบนเซิร์ฟเวอร์หลักสามารถประกาศให้เสร็จสมบูรณ์เมื่อทำการเปลี่ยนแปลงบนเซิร์ฟเวอร์หลักเท่านั้น การเปลี่ยนแปลงเหล่านี้จะถูกจำลองแบบในภายหลังในเวลาต่อมา เซิร์ฟเวอร์จำลองอาจไม่ซิงค์กันในช่วงระยะเวลาหนึ่ง ซึ่งเรียกว่าความล่าช้าในการจำลอง ในกรณีที่เกิดการขัดข้อง ข้อมูลอาจสูญหายได้ แต่โอเวอร์เฮดที่ได้จากการจำลองแบบอะซิงโครนัสมีน้อย ดังนั้นจึงยอมรับได้ในกรณีส่วนใหญ่ (ไม่สร้างภาระให้กับโฮสต์มากเกินไป) เฟลโอเวอร์จากฐานข้อมูลหลักไปยังฐานข้อมูลรองใช้เวลานานกว่าการจำลองแบบซิงโครนัส
วิธีการตั้งค่าการจำลองแบบ PostgreSQL
สำหรับส่วนนี้ เราจะสาธิตวิธีตั้งค่ากระบวนการจำลองแบบ PostgreSQL บนระบบปฏิบัติการ Linux สำหรับตัวอย่างนี้ เราจะใช้ Ubuntu 18.04 LTS และ PostgreSQL 10
มาขุดกันเถอะ!
การติดตั้ง
คุณจะเริ่มต้นด้วยการติดตั้ง PostgreSQL บน Linux ด้วยขั้นตอนเหล่านี้:
- ก่อนอื่น คุณต้องนำเข้าคีย์การลงนาม PostgreSQL โดยพิมพ์คำสั่งด้านล่างในเทอร์มินัล:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - จากนั้น เพิ่มที่เก็บ PostgreSQL โดยพิมพ์คำสั่งด้านล่างในเทอร์มินัล:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - อัพเดต Repository Index โดยพิมพ์คำสั่งต่อไปนี้ในเทอร์มินัล:
sudo apt-get update - ติดตั้งแพ็คเกจ PostgreSQL โดยใช้คำสั่ง apt:
sudo apt-get install -y postgresql-10 - สุดท้าย ตั้งรหัสผ่านสำหรับผู้ใช้ PostgreSQL โดยใช้คำสั่งต่อไปนี้:
sudo passwd postgres
การติดตั้ง PostgreSQL เป็นสิ่งจำเป็นสำหรับทั้งเซิร์ฟเวอร์หลักและเซิร์ฟเวอร์รองก่อนเริ่มกระบวนการจำลองแบบ PostgreSQL
เมื่อคุณได้ตั้งค่า PostgreSQL สำหรับทั้งสองเซิร์ฟเวอร์แล้ว คุณสามารถไปยังการตั้งค่าการจำลองแบบของเซิร์ฟเวอร์หลักและเซิร์ฟเวอร์รองได้
การตั้งค่าการจำลองแบบในเซิร์ฟเวอร์หลัก
ทำตามขั้นตอนเหล่านี้เมื่อคุณได้ติดตั้ง PostgreSQL บนเซิร์ฟเวอร์หลักและเซิร์ฟเวอร์รองแล้ว
- ขั้นแรก ล็อกอินเข้าสู่ฐานข้อมูล PostgreSQL ด้วยคำสั่งต่อไปนี้:
su - postgres - สร้างผู้ใช้การจำลองด้วยคำสั่งต่อไปนี้:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - แก้ไข pg_hba.cnf ด้วยแอปพลิเคชั่น nano ใน Ubuntu และเพิ่มการกำหนดค่าต่อไปนี้: file edit command
nano /etc/postgresql/10/main/pg_hba.confในการกำหนดค่าไฟล์ ให้ใช้คำสั่งต่อไปนี้:
host replication replication MasterIP/24 md5 - เปิดและแก้ไข postgresql.conf และใส่การกำหนดค่าต่อไปนี้ในเซิร์ฟเวอร์หลัก:
nano /etc/postgresql/10/main/postgresql.confใช้การตั้งค่าการกำหนดค่าต่อไปนี้:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - สุดท้าย ให้รีสตาร์ท PostgreSQL ในเซิร์ฟเวอร์หลักหลัก:
systemctl restart postgresqlคุณได้เสร็จสิ้นการตั้งค่าในเซิร์ฟเวอร์หลักแล้ว
การตั้งค่าการจำลองแบบในเซิร์ฟเวอร์รอง
ทำตามขั้นตอนเหล่านี้เพื่อตั้งค่าการจำลองแบบในเซิร์ฟเวอร์รอง:
- เข้าสู่ระบบ PostgreSQL RDMS ด้วยคำสั่งด้านล่าง:
su - postgres - หยุดบริการ PostgreSQL ไม่ให้ทำงานเพื่อให้เราดำเนินการได้ด้วยคำสั่งด้านล่าง:
systemctl stop postgresql - แก้ไขไฟล์ pg_hba.conf ด้วยคำสั่งนี้และเพิ่มการกำหนดค่าต่อไปนี้:
แก้ไขคำสั่งnano /etc/postgresql/10/main/pg_hba.confการกำหนดค่า
host replication replication MasterIP/24 md5 - เปิดและแก้ไข postgresql.conf ในเซิร์ฟเวอร์รองและใส่การกำหนดค่าต่อไปนี้หรือ uncomment หากมีความคิดเห็น: แก้ไขคำสั่ง
การกำหนดค่าnano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP คือที่อยู่ของเซิร์ฟเวอร์รอง
- เข้าถึงไดเร็กทอรีข้อมูล PostgreSQL ในเซิร์ฟเวอร์สำรองและลบทุกอย่าง:
cd /var/lib/postgresql/10/mainrm -rfv * - คัดลอกไฟล์ไดเร็กทอรีข้อมูลเซิร์ฟเวอร์หลัก PostgreSQL ไปยังไดเร็กทอรีข้อมูลเซิร์ฟเวอร์รอง PostgreSQL และเขียนคำสั่งนี้ในเซิร์ฟเวอร์รอง:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - ป้อนรหัสผ่านเซิร์ฟเวอร์หลัก PostgreSQL แล้วกด Enter ถัดไป เพิ่มคำสั่งต่อไปนี้สำหรับการกำหนดค่าการกู้คืน: Edit Command
nano /var/lib/postgresql/10/main/recovery.confการกำหนดค่า
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'YOUR_PASSWORD เป็นรหัสผ่านสำหรับผู้ใช้การจำลองแบบในเซิร์ฟเวอร์หลัก PostgreSQL ที่สร้างขึ้น
- เมื่อตั้งรหัสผ่านแล้ว คุณจะต้องรีสตาร์ทฐานข้อมูล PostgreSQL สำรองเนื่องจากถูกหยุด:
systemctl start postgresqlการทดสอบการตั้งค่าของคุณ
ตอนนี้เราได้ดำเนินการตามขั้นตอนแล้ว มาทดสอบกระบวนการจำลองแบบและสังเกตฐานข้อมูลเซิร์ฟเวอร์รองกัน สำหรับสิ่งนี้ เราสร้างตารางในเซิร์ฟเวอร์หลักและสังเกตว่าสิ่งเดียวกันนั้นสะท้อนให้เห็นบนเซิร์ฟเวอร์รองหรือไม่
ไปกันเถอะ
- เนื่องจากเรากำลังสร้างตารางในเซิร์ฟเวอร์หลัก คุณจะต้องลงชื่อเข้าใช้เซิร์ฟเวอร์หลัก:
su - postgres psql - ตอนนี้เราสร้างตารางอย่างง่ายที่ชื่อว่า 'testtable' และแทรกข้อมูลลงในตารางโดยเรียกใช้การสืบค้น PostgreSQL ต่อไปนี้ในเทอร์มินัล:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - สังเกตฐานข้อมูล PostgreSQL ของเซิร์ฟเวอร์รองโดยลงชื่อเข้าใช้เซิร์ฟเวอร์รอง:
su - postgres psql - ตอนนี้ เราตรวจสอบว่ามีตาราง 'testtable' อยู่หรือไม่ และสามารถส่งคืนข้อมูลได้โดยเรียกใช้การสืบค้น PostgreSQL ต่อไปนี้ในเทอร์มินัล คำสั่งนี้จะแสดงทั้งตารางเป็นหลัก
select * from testtable;
นี่คือผลลัพธ์ของตารางทดสอบ:
| websites | ------------------- | section.com | | google.com | | github.com | --------------------คุณควรจะสามารถสังเกตข้อมูลเดียวกับที่อยู่ในเซิร์ฟเวอร์หลักได้
หากคุณเห็นข้างต้น แสดงว่าคุณได้ดำเนินการตามขั้นตอนการจำลองแบบสำเร็จแล้ว!
ขั้นตอน Failover ด้วยตนเองของ PostgreSQL คืออะไร
มาดูขั้นตอนสำหรับการเฟลโอเวอร์ด้วยตนเองของ PostgreSQL:
- ขัดข้องเซิร์ฟเวอร์หลัก
- เลื่อนระดับเซิร์ฟเวอร์สแตนด์บายโดยรันคำสั่งต่อไปนี้บนเซิร์ฟเวอร์สแตนด์บาย:
./pg_ctl promote -D ../sb_data/ server promoting - เชื่อมต่อกับเซิร์ฟเวอร์สแตนด์บายที่เลื่อนระดับและแทรกแถว:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values (4,'Four');
หากการแทรกทำงานได้ดี แสดงว่าสแตนด์บายซึ่งก่อนหน้านี้เป็นเซิร์ฟเวอร์แบบอ่านอย่างเดียวได้รับการเลื่อนตำแหน่งเป็นเซิร์ฟเวอร์หลักใหม่
วิธีทำให้ Failover เป็นอัตโนมัติใน PostgreSQL
การตั้งค่าเฟลโอเวอร์อัตโนมัติเป็นเรื่องง่าย
คุณจะต้องมี EDB PostgreSQL failover manager (EFM) หลังจากดาวน์โหลดและติดตั้ง EFM ในแต่ละโหนดหลักและโหนดสแตนด์บาย คุณสามารถสร้างคลัสเตอร์ EFM ซึ่งประกอบด้วยโหนดหลัก โหนดสแตนด์บายอย่างน้อยหนึ่งโหนด และโหนดยืนยันเสริมที่ยืนยันการยืนยันในกรณีที่เกิดความล้มเหลว
EFM ตรวจสอบความสมบูรณ์ของระบบอย่างต่อเนื่องและส่งการแจ้งเตือนทางอีเมลตามเหตุการณ์ของระบบ เมื่อเกิดความล้มเหลวขึ้น ระบบจะสลับไปยังโหมดสแตนด์บายที่อัปเดตล่าสุดโดยอัตโนมัติ และกำหนดค่าเซิร์ฟเวอร์สแตนด์บายอื่นทั้งหมดใหม่เพื่อให้รู้จักโหนดหลักใหม่
นอกจากนี้ยังกำหนดค่าตัวจัดสรรภาระงานใหม่ (เช่น pgPool) และป้องกันไม่ให้เกิด "split-brain" (เมื่อโหนดสองโหนดแต่ละโหนดคิดว่าโหนดหลัก) เกิดขึ้น
สรุป
เนื่องจากมีข้อมูลจำนวนมาก ความสามารถในการปรับขนาดและความปลอดภัยจึงกลายเป็นสองเกณฑ์ที่สำคัญที่สุดในการจัดการฐานข้อมูล โดยเฉพาะอย่างยิ่งในสภาพแวดล้อมของธุรกรรม แม้ว่าเราจะสามารถปรับปรุงความสามารถในการปรับขนาดในแนวตั้งได้โดยการเพิ่มทรัพยากร/ฮาร์ดแวร์เพิ่มเติมให้กับโหนดที่มีอยู่ แต่ก็ไม่สามารถทำได้เสมอไป บ่อยครั้งเนื่องจากต้นทุนหรือข้อจำกัดในการเพิ่มฮาร์ดแวร์ใหม่
ดังนั้นจึงจำเป็นต้องมีการปรับขนาดในแนวนอน ซึ่งหมายถึงการเพิ่มโหนดเพิ่มเติมให้กับโหนดเครือข่ายที่มีอยู่ แทนที่จะเพิ่มฟังก์ชันการทำงานของโหนดที่มีอยู่ นี่คือที่มาของการจำลองแบบ PostgreSQL ในภาพ
ในบทความนี้ เราได้พูดถึงประเภทของการจำลองแบบ PostgreSQL ประโยชน์ โหมดการจำลอง การติดตั้ง และความล้มเหลวของ PostgreSQL ระหว่าง SMR และ MMR ตอนนี้ขอได้ยินจากคุณ
คุณมักจะใช้อันไหน คุณลักษณะฐานข้อมูลใดที่สำคัญที่สุดสำหรับคุณและเพราะเหตุใด เราชอบที่จะอ่านความคิดของคุณ! แบ่งปันในส่วนความคิดเห็นด้านล่าง