
Репликация PostgreSQL: подробное руководство
Опубликовано: 2022-08-11Как скажет вам любой владелец сайта, потеря данных и простои, даже в минимальных дозах, могут быть катастрофическими. Они могут нанести удар по неподготовленным в любое время, что приведет к снижению производительности, доступности и доверия к продукту.
Для защиты целостности вашего сайта жизненно важно создать средства защиты от возможности простоя или потери данных.
Вот тут и вступает в действие репликация данных.
Репликация данных — это автоматизированный процесс резервного копирования, при котором ваши данные многократно копируются из основной базы данных в другое удаленное место для безопасного хранения. Это неотъемлемая технология для любого сайта или приложения, на котором работает сервер базы данных. Вы также можете использовать реплицированную базу данных для обработки SQL только для чтения, что позволяет запускать больше процессов в системе.
Настройка репликации между двумя базами данных обеспечивает отказоустойчивость при неожиданных сбоях. Это считается лучшей стратегией для достижения высокой доступности во время аварий.
В этой статье мы рассмотрим различные стратегии, которые могут быть реализованы бэкэнд-разработчиками для бесперебойной репликации PostgreSQL.
Что такое репликация PostgreSQL?
Репликация PostgreSQL определяется как процесс копирования данных с сервера базы данных PostgreSQL на другой сервер. Исходный сервер базы данных также известен как «первичный» сервер, тогда как сервер базы данных, получающий скопированные данные, известен как сервер «реплика».
База данных PostgreSQL использует простую модель репликации, в которой все операции записи выполняются на первичном узле. Затем первичный узел может применить эти изменения и передать их вторичным узлам.
Что такое автоматический переход на другой ресурс?
После настройки физической потоковой репликации в PostgreSQL может произойти отказоустойчивость в случае сбоя основного сервера базы данных. Отказоустойчивость используется для определения процесса восстановления, который может занять некоторое время, поскольку он не предоставляет встроенных инструментов для выявления сбоев сервера.
Вам не нужно зависеть от PostgreSQL для аварийного переключения. Существуют специальные инструменты, которые обеспечивают автоматическое отключение при сбое и автоматическое переключение в резервный режим, сокращая время простоя базы данных.
Настраивая отказоустойчивую репликацию, вы практически гарантируете высокую доступность, гарантируя, что резервные серверы будут доступны в случае выхода из строя основного сервера.
Преимущества использования репликации PostgreSQL
Вот несколько ключевых преимуществ использования репликации PostgreSQL:
- Миграция данных . Вы можете использовать репликацию PostgreSQL для миграции данных либо путем замены оборудования сервера базы данных, либо путем развертывания системы.
- Отказоустойчивость : в случае сбоя основного сервера резервный сервер может действовать как сервер, поскольку содержащиеся данные для основного и резервного серверов одинаковы.
- Производительность оперативной обработки транзакций (OLTP) : вы можете улучшить время обработки транзакций и время запросов в системе OLTP, убрав нагрузку запросов отчетов. Время обработки транзакции — это время, необходимое для выполнения данного запроса до завершения транзакции.
- Параллельное тестирование системы . При обновлении новой системы необходимо убедиться, что система хорошо работает с существующими данными, поэтому перед развертыванием необходимо провести тестирование с копией рабочей базы данных.
Как работает репликация PostgreSQL
Как правило, люди считают, что когда вы работаете с первичной и вторичной архитектурой, есть только один способ настроить резервное копирование и репликацию, но развертывание PostgreSQL следует одному из следующих трех подходов:
- Репликация на уровне тома для репликации на уровне хранилища с основного на дополнительный узел с последующим резервным копированием в хранилище BLOB-объектов или S3.
- Потоковая репликация PostgreSQL для репликации данных с основного на дополнительный узел с последующим резервным копированием в хранилище BLOB-объектов или S3.
- Выполнение добавочных резервных копий с основного узла на S3 при восстановлении нового вторичного узла с S3. Когда вторичный узел находится рядом с основным, вы можете начать потоковую передачу с основного узла.
Подход 1: потоковая передача
Потоковую репликацию PostgreSQL, также известную как репликация WAL, можно легко настроить после установки PostgreSQL на всех серверах. Этот подход к репликации основан на перемещении файлов WAL из первичной базы данных в целевую.
Вы можете реализовать потоковую репликацию PostgreSQL, используя первично-вторичную конфигурацию. Первичный сервер — это основной экземпляр, который обрабатывает первичную базу данных и все ее операции. Вторичный сервер действует как дополнительный экземпляр и выполняет все изменения, внесенные в первичную базу данных, на себе, создавая в процессе идентичную копию. Первичный сервер — это сервер чтения/записи, тогда как вторичный сервер доступен только для чтения.
Для этого подхода необходимо настроить как основной узел, так и резервный узел. В следующих разделах объясняются шаги, связанные с их легкой настройкой.
Настройка основного узла
Вы можете настроить первичный узел для потоковой репликации, выполнив следующие шаги:
Шаг 1: Инициализируйте базу данных
Для инициализации базы данных вы можете использовать initidb utility . Затем вы можете создать нового пользователя с правами репликации, используя следующую команду:
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';Пользователь должен будет указать пароль и имя пользователя для данного запроса. Ключевое слово replication используется для предоставления пользователю необходимых привилегий. Пример запроса будет выглядеть примерно так:
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'Шаг 2. Настройте свойства потоковой передачи
Затем вы можете настроить свойства потоковой передачи с помощью файла конфигурации PostgreSQL ( postgresql.conf ), который можно изменить следующим образом:
wal_level = logical wal_log_hints = on max_wal_senders = 8 max_wal_size = 1GB hot_standby = onВот небольшая предыстория параметров, использованных в предыдущем фрагменте:
-
wal_log_hints: этот параметр требуется для возможностиpg_rewind, которая пригодится, когда резервный сервер не синхронизирован с основным сервером. -
wal_level: этот параметр можно использовать для включения потоковой репликации PostgreSQL с возможными значениями, включаяminimal,replicaилиlogical. -
max_wal_size: можно использовать для указания размера файлов WAL, которые можно сохранить в файлах журналов. -
hot_standby: вы можете использовать этот параметр для чтения соединения с вторичным, когда он установлен на ON. -
max_wal_senders: вы можете использоватьmax_wal_senders, чтобы указать максимальное количество одновременных подключений, которые могут быть установлены с резервными серверами.
Шаг 3: Создайте новую запись
После изменения параметров в файле postgresql.conf новая запись репликации в файле pg_hba.conf может позволить серверам установить соединение друг с другом для репликации.
Обычно этот файл можно найти в каталоге данных PostgreSQL. Вы можете использовать следующий фрагмент кода для того же самого:
host replication rep_user IPaddress md5 После выполнения фрагмента кода основной сервер позволяет пользователю с именем rep_user подключиться и действовать в качестве резервного сервера, используя указанный IP-адрес для репликации. Например:
host replication rep_user 192.168.0.22/32 md5Настройка резервного узла
Чтобы настроить резервный узел для потоковой репликации, выполните следующие действия.
Шаг 1: Резервное копирование основного узла
Чтобы настроить резервный узел, используйте утилиту pg_basebackup для создания резервной копии основного узла. Это послужит отправной точкой для резервного узла. Вы можете использовать эту утилиту со следующим синтаксисом:
pg_basebackp -D -h -X stream -c fast -U rep_user -WПараметры, используемые в упомянутом выше синтаксисе, следующие:
-
-h: вы можете использовать это, чтобы указать основной хост. -
-D: этот параметр указывает каталог, над которым вы сейчас работаете. -
-C: Вы можете использовать это для установки контрольных точек. -
-X: этот параметр можно использовать для включения необходимых файлов журналов транзакций. -
-W: этот параметр можно использовать, чтобы запросить у пользователя пароль перед подключением к базе данных.
Шаг 2: Настройте файл конфигурации репликации
Далее необходимо проверить, существует ли файл конфигурации репликации. Если это не так, вы можете создать файл конфигурации репликации как recovery.conf.
Вы должны создать этот файл в каталоге данных установки PostgreSQL. Вы можете сгенерировать его автоматически, используя параметр -R в утилите pg_basebackup .
Файл recovery.conf должен содержать следующие команды:
режим ожидания = 'вкл'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name=”host_name”'
recovery_target_timeline = 'последний'
Параметры, используемые в вышеупомянутых командах, следующие:
-
primary_conninfo: вы можете использовать это для установления соединения между первичным и вторичным серверами, используя строку подключения. -
standby_mode: этот параметр может привести к тому, что основной сервер будет запускаться как резервный при включении. -
recovery_target_timeline: вы можете использовать это, чтобы установить время восстановления.
Чтобы настроить соединение, вам необходимо указать имя пользователя, IP-адрес и пароль в качестве значений для параметра primary_conninfo. Например:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Шаг 3: перезапустите дополнительный сервер
Наконец, вы можете перезапустить вторичный сервер, чтобы завершить процесс настройки.
Однако потоковая репликация связана с рядом проблем, таких как:
- Различные клиенты PostgreSQL (написанные на разных языках программирования) взаимодействуют с одной конечной точкой. Когда основной узел выходит из строя, эти клиенты будут продолжать повторять попытку с одним и тем же DNS-именем или IP-адресом. Это делает отработку отказа видимой для приложения.
- Репликация PostgreSQL не имеет встроенных средств аварийного переключения и мониторинга. Когда первичный узел выходит из строя, вам необходимо сделать вторичный узел новым первичным. Это продвижение должно выполняться таким образом, чтобы клиенты писали только на один первичный узел и не наблюдали несоответствий данных.
- PostgreSQL реплицирует все свое состояние. Когда вам нужно разработать новый вторичный узел, вторичный должен повторить всю историю изменения состояния основного узла, что является ресурсоемким и делает дорогостоящим устранение узлов в голове и создание новых.
Подход 2: реплицированное блочное устройство
Подход с реплицированными блочными устройствами зависит от зеркального отображения дисков (также известного как репликация томов). В этом подходе изменения записываются на постоянный том, который синхронно зеркально отражается на другом томе.
Дополнительным преимуществом этого подхода является его совместимость и надежность данных в облачных средах со всеми реляционными базами данных, включая PostgreSQL, MySQL и SQL Server, и это лишь некоторые из них.
Однако подход к репликации PostgreSQL с зеркалированием диска требует, чтобы вы реплицировали как журнал WAL, так и данные таблицы. Поскольку каждая запись в базу данных теперь должна выполняться синхронно по сети, вы не можете позволить себе потерять ни одного байта, так как это может оставить вашу базу данных в поврежденном состоянии.
Этот подход обычно используется с помощью Azure PostgreSQL и Amazon RDS.
Подход 3: ВАЛ
WAL состоит из файлов-сегментов (по умолчанию 16 МБ). Каждый сегмент имеет одну или несколько записей. Запись последовательности журнала (LSN) — это указатель на запись в WAL, позволяющий узнать положение/местоположение, в котором запись была сохранена в файле журнала.
Резервный сервер использует сегменты WAL, также известные как XLOGS в терминологии PostgreSQL, для непрерывной репликации изменений с основного сервера. Вы можете использовать ведение журнала с опережающей записью, чтобы обеспечить устойчивость и атомарность в СУБД, сериализуя фрагменты данных массива байтов (каждый с уникальным номером LSN) в стабильном хранилище, прежде чем они будут применены к базе данных.
Применение мутации к базе данных может привести к различным операциям с файловой системой. Возникает уместный вопрос: как база данных может обеспечить атомарность в случае сбоя сервера из-за отключения электроэнергии во время обновления файловой системы. Когда база данных загружается, она начинает процесс запуска или воспроизведения, который может считывать доступные сегменты WAL и сравнивать их с номером LSN, хранящимся на каждой странице данных (каждая страница данных помечается номером LSN последней записи WAL, влияющей на страницу).
Репликация на основе доставки журналов (уровень блоков)
Потоковая репликация улучшает процесс доставки журналов. В отличие от ожидания переключения WAL, записи отправляются по мере их создания, что снижает задержку репликации.
Потоковая репликация также превосходит доставку журналов, поскольку резервный сервер связывается с основным сервером по сети, используя протокол репликации. Затем первичный сервер может отправлять записи WAL непосредственно через это соединение, не завися от сценариев, предоставленных конечным пользователем.
Репликация на основе доставки журналов (на уровне файлов)
Доставка журналов определяется как копирование файлов журналов на другой сервер PostgreSQL для создания другого резервного сервера путем воспроизведения файлов WAL. Этот сервер настроен на работу в режиме восстановления, и его единственная цель — применять любые новые файлы WAL по мере их появления.
Затем этот вторичный сервер становится горячей резервной копией основного сервера PostgreSQL. Его также можно настроить как реплику чтения, где он может предлагать запросы только для чтения, также называемые горячим резервированием.
Непрерывное архивирование WAL
Дублирование файлов WAL по мере их создания в любом месте, кроме подкаталога pg_wal , для их архивирования называется архивированием WAL. PostgreSQL будет вызывать сценарий, предоставленный пользователем для архивирования, каждый раз, когда создается файл WAL.
Сценарий может использовать команду scp для дублирования файла в одно или несколько мест, например на монтирование NFS. После архивации файлы сегментов WAL можно использовать для восстановления базы данных в любой момент времени.
Другие конфигурации на основе журнала включают:
- Синхронная репликация . Прежде чем будет зафиксирована каждая транзакция синхронной репликации, основной сервер ждет, пока резервные серверы не подтвердят, что они получили данные. Преимущество этой конфигурации в том, что не будет конфликтов, вызванных параллельными процессами записи.
- Синхронная репликация с несколькими мастерами : здесь каждый сервер может принимать запросы на запись, а измененные данные передаются с исходного сервера на каждый другой сервер до того, как каждая транзакция будет зафиксирована. Он использует протокол 2PC и придерживается правила «все или ничего».
Детали протокола потоковой передачи WAL
Процесс, известный как приемник WAL, запущенный на резервном сервере, использует сведения о соединении, указанные в параметре primary_conninfo в файле recovery.conf, и подключается к основному серверу, используя соединение TCP/IP.
Чтобы запустить потоковую репликацию, внешний интерфейс может отправить параметр репликации в стартовом сообщении. Логическое значение true, yes, 1 или ON сообщает серверной части, что ему необходимо перейти в режим физической репликации walsender.
Отправитель WAL — это еще один процесс, который выполняется на основном сервере и отвечает за отправку записей WAL на резервный сервер по мере их создания. Приемник WAL сохраняет записи WAL в WAL, как если бы они были созданы клиентской активностью локально подключенных клиентов.

Как только записи WAL достигают файлов сегментов WAL, резервный сервер постоянно воспроизводит WAL, чтобы первичный и резервный серверы были актуальными.
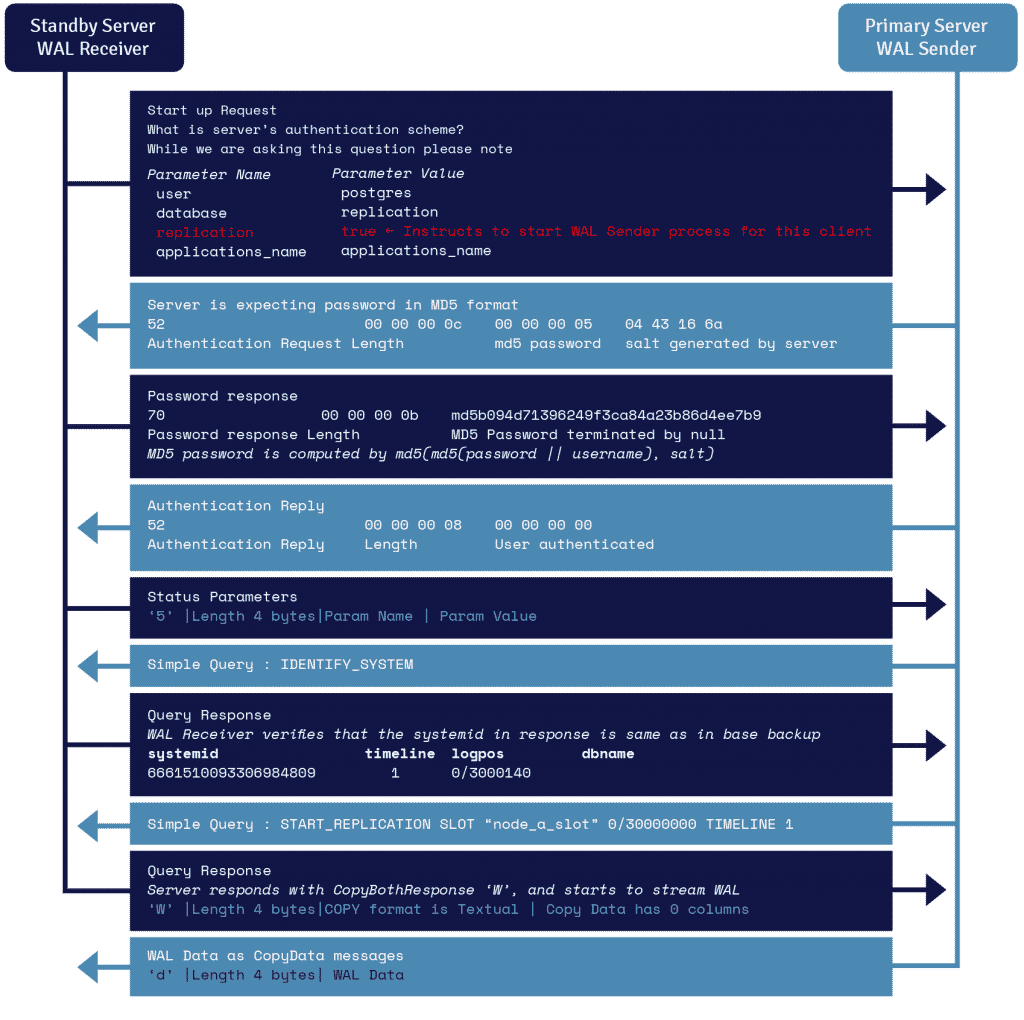
Элементы репликации PostgreSQL
В этом разделе вы получите более глубокое представление о часто используемых моделях (репликация с одним и несколькими мастерами), типах (физическая и логическая репликация) и режимах (синхронный и асинхронный) репликации PostgreSQL.
Модели репликации базы данных PostgreSQL
Масштабируемость означает добавление дополнительных ресурсов/оборудования к существующим узлам для повышения способности базы данных хранить и обрабатывать больше данных, что может быть достигнуто как по горизонтали, так и по вертикали. Репликация PostgreSQL — это пример горизонтальной масштабируемости, реализовать которую гораздо сложнее, чем вертикальную. Мы можем добиться горизонтальной масштабируемости в основном за счет репликации с одним мастером (SMR) и репликации с несколькими мастерами (MMR).
Репликация с одним мастером позволяет изменять данные только на одном узле, и эти изменения реплицируются на один или несколько узлов. Реплицированные таблицы в базе данных-реплике не могут принимать какие-либо изменения, кроме изменений с основного сервера. Даже если они это сделают, изменения не реплицируются обратно на первичный сервер.
В большинстве случаев SMR достаточно для приложения, потому что его проще настроить и управлять, а также нет вероятности конфликтов. Репликация с одним мастером также является однонаправленной, поскольку данные репликации передаются в основном в одном направлении, от первичной базы данных к реплике.
В некоторых случаях одного SMR может быть недостаточно, и вам может потребоваться внедрить MMR. MMR позволяет более чем одному узлу выступать в качестве основного узла. Изменения в строках таблицы более чем в одной назначенной первичной базе данных реплицируются в соответствующие таблицы во всех других первичных базах данных. В этой модели часто используются схемы разрешения конфликтов, чтобы избежать таких проблем, как дублирование первичных ключей.
Есть несколько преимуществ использования MMR, а именно:
- В случае сбоя хоста другие хосты могут по-прежнему предоставлять услуги по обновлению и вставке.
- Первичные узлы разбросаны по нескольким разным местам, поэтому вероятность выхода из строя всех первичных узлов очень мала.
- Возможность использовать глобальную сеть (WAN) первичных баз данных, которые могут быть географически близки к группам клиентов, но при этом поддерживать согласованность данных в сети.
Однако недостатком внедрения MMR является сложность и сложность разрешения конфликтов.
Несколько ответвлений и приложений предоставляют решения MMR, поскольку PostgreSQL изначально не поддерживает их. Эти решения могут быть открытыми, бесплатными или платными. Одним из таких расширений является двунаправленная репликация (BDR), которая является асинхронной и основана на функции логического декодирования PostgreSQL.
Поскольку приложение BDR воспроизводит транзакции на других узлах, операция воспроизведения может завершиться ошибкой, если возникнет конфликт между применяемой транзакцией и транзакцией, зафиксированной на принимающем узле.
Типы репликации PostgreSQL
Существует два типа репликации PostgreSQL: логическая и физическая репликация.
Простая логическая операция «initdb» будет выполнять физическую операцию по созданию базового каталога для кластера. Точно так же простая логическая операция «СОЗДАТЬ БАЗУ ДАННЫХ» будет выполнять физическую операцию по созданию подкаталога в базовом каталоге.
Физическая репликация обычно имеет дело с файлами и каталогами. Он не знает, что представляют собой эти файлы и каталоги. Эти методы используются для сохранения полной копии всех данных одного кластера, как правило, на другом компьютере, и выполняются на уровне файловой системы или на уровне диска и используют точные адреса блоков.
Логическая репликация — это способ воспроизведения объектов данных и их модификаций на основе их идентификатора репликации (обычно первичного ключа). В отличие от физической репликации, она имеет дело с базами данных, таблицами и операциями DML и выполняется на уровне кластера базы данных. Он использует модель публикации и подписки , в которой один или несколько подписчиков подписаны на одну или несколько публикаций на узле издателя .
Процесс репликации начинается с создания моментального снимка данных в базе данных издателя, а затем их копирования на подписчик. Подписчики извлекают данные из публикаций, на которые они подписаны, и могут повторно опубликовать данные позже, чтобы разрешить каскадную репликацию или более сложные конфигурации. Подписчик применяет данные в том же порядке, что и издатель, чтобы гарантировать согласованность транзакций для публикаций в рамках одной подписки, также известную как репликация транзакций.
Типичные варианты использования логической репликации:
- Отправка добавочных изменений в одной базе данных (или подмножестве базы данных) подписчикам по мере их возникновения.
- Совместное использование подмножества базы данных между несколькими базами данных.
- Запуск отдельных изменений по мере их поступления на подписчика.
- Объединение нескольких баз данных в одну.
- Предоставление доступа к реплицированным данным различным группам пользователей.
База данных подписчиков ведет себя так же, как и любой другой экземпляр PostgreSQL, и может использоваться в качестве издателя для других баз данных путем определения своих публикаций.
Когда подписчик рассматривается приложением как доступный только для чтения, конфликтов из-за одной подписки не будет. С другой стороны, если есть другие операции записи, выполняемые приложением или другими подписчиками в тот же набор таблиц, могут возникнуть конфликты.
PostgreSQL поддерживает оба механизма одновременно. Логическая репликация позволяет точно контролировать как репликацию данных, так и безопасность.
Режимы репликации
В основном существует два режима репликации PostgreSQL: синхронный и асинхронный. Синхронная репликация позволяет записывать данные как на первичный, так и на вторичный сервер одновременно, тогда как асинхронная репликация гарантирует, что данные сначала записываются на хост, а затем копируются на вторичный сервер.
При репликации в синхронном режиме транзакции в базе данных-источнике считаются завершенными, только если эти изменения были реплицированы на все реплики. Все серверы-реплики должны быть постоянно доступны для выполнения транзакций на первичном сервере. Синхронный режим репликации используется в высокопроизводительных транзакционных средах с немедленным отказоустойчивостью.
В асинхронном режиме транзакции на первичном сервере могут быть объявлены завершенными, когда изменения были сделаны только на первичном сервере. Эти изменения затем реплицируются в репликах позже во времени. Серверы-реплики могут оставаться несинхронизированными в течение определенного времени, называемого задержкой репликации. В случае сбоя может произойти потеря данных, но накладные расходы, обеспечиваемые асинхронной репликацией, невелики, поэтому в большинстве случаев это приемлемо (не перегружает хост). Переход от первичной базы данных к вторичной базе данных занимает больше времени, чем синхронная репликация.
Как настроить репликацию PostgreSQL
В этом разделе мы покажем, как настроить процесс репликации PostgreSQL в операционной системе Linux. В данном случае мы будем использовать Ubuntu 18.04 LTS и PostgreSQL 10.
Давайте копать!
Монтаж
Вы начнете с установки PostgreSQL в Linux, выполнив следующие действия:
- Во-первых, вам нужно будет импортировать ключ подписи PostgreSQL, введя в терминале следующую команду:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Затем добавьте репозиторий PostgreSQL, введя в терминале следующую команду:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Обновите индекс репозитория, введя в терминале следующую команду:
sudo apt-get update - Установите пакет PostgreSQL с помощью команды apt:
sudo apt-get install -y postgresql-10 - Наконец, установите пароль для пользователя PostgreSQL с помощью следующей команды:
sudo passwd postgres
Установка PostgreSQL обязательна как для основного, так и для дополнительного сервера перед запуском процесса репликации PostgreSQL.
После того, как вы настроили PostgreSQL для обоих серверов, вы можете перейти к настройке репликации основного и дополнительного серверов.
Настройка репликации на основном сервере
Выполните эти шаги после того, как вы установили PostgreSQL на первичный и вторичный серверы.
- Во-первых, войдите в базу данных PostgreSQL с помощью следующей команды:
su - postgres - Создайте пользователя репликации с помощью следующей команды:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Отредактируйте pg_hba.cnf с помощью любого приложения nano в Ubuntu и добавьте следующую конфигурацию: команда редактирования файла
nano /etc/postgresql/10/main/pg_hba.confЧтобы настроить файл, используйте следующую команду:
host replication replication MasterIP/24 md5 - Откройте и отредактируйте postgresql.conf и поместите следующую конфигурацию на основной сервер:
nano /etc/postgresql/10/main/postgresql.confИспользуйте следующие параметры конфигурации:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - Наконец, перезапустите PostgreSQL на первичном главном сервере:
systemctl restart postgresqlВы завершили настройку основного сервера.
Настройка репликации на вторичном сервере
Выполните следующие действия, чтобы настроить репликацию на вторичном сервере:
- Войдите в PostgreSQL RDMS с помощью следующей команды:
su - postgres - Остановите работу службы PostgreSQL, чтобы мы могли работать над ней, с помощью следующей команды:
systemctl stop postgresql - Отредактируйте файл pg_hba.conf с помощью этой команды и добавьте следующую конфигурацию:
Редактировать командуnano /etc/postgresql/10/main/pg_hba.confКонфигурация
host replication replication MasterIP/24 md5 - Откройте и отредактируйте postgresql.conf на вторичном сервере и поместите следующую конфигурацию или раскомментируйте, если она закомментирована: Edit Command
Конфигурацияnano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP — это адрес вторичного сервера.
- Получите доступ к каталогу данных PostgreSQL на вторичном сервере и удалите все:
cd /var/lib/postgresql/10/mainrm -rfv * - Скопируйте файлы каталога данных первичного сервера PostgreSQL в каталог данных вторичного сервера PostgreSQL и напишите эту команду на вторичном сервере:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - Введите пароль основного сервера PostgreSQL и нажмите Enter. Затем добавьте следующую команду для конфигурации восстановления: Edit Command
nano /var/lib/postgresql/10/main/recovery.confКонфигурация
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Здесь YOUR_PASSWORD — это пароль пользователя репликации на первичном сервере, созданном PostgreSQL.
- После установки пароля вам придется перезапустить дополнительную базу данных PostgreSQL, так как она была остановлена:
systemctl start postgresqlТестирование вашей установки
Теперь, когда мы выполнили шаги, давайте протестируем процесс репликации и посмотрим на базу данных вторичного сервера. Для этого мы создаем таблицу на первичном сервере и наблюдаем, отражается ли то же самое на вторичном сервере.
Давайте приступим к делу.
- Поскольку мы создаем таблицу на основном сервере, вам необходимо войти на основной сервер:
su - postgres psql - Теперь создадим простую таблицу с именем testtable и вставим в нее данные, выполнив следующие запросы PostgreSQL в терминале:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Наблюдайте за базой данных PostgreSQL вторичного сервера, войдя на вторичный сервер:
su - postgres psql - Теперь мы проверяем, существует ли таблица testtable и можем ли вернуть данные, выполнив следующие запросы PostgreSQL в терминале. Эта команда по существу отображает всю таблицу.
select * from testtable;
Это вывод тестовой таблицы:
| websites | ------------------- | section.com | | google.com | | github.com | --------------------Вы должны иметь возможность наблюдать те же данные, что и на основном сервере.
Если вы видите вышеперечисленное, значит, вы успешно провели процесс репликации!
Каковы шаги аварийного переключения PostgreSQL вручную?
Давайте рассмотрим шаги для ручной отработки отказа PostgreSQL:
- Сбой основного сервера.
- Повысьте уровень резервного сервера, выполнив следующую команду на резервном сервере:
./pg_ctl promote -D ../sb_data/ server promoting - Подключитесь к повышенному резервному серверу и вставьте строку:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values (4,'Four');
Если вставка работает нормально, то резервный сервер, ранее доступный только для чтения, был назначен новым первичным сервером.
Как автоматизировать аварийное переключение в PostgreSQL
Настроить автоматический переход на другой ресурс очень просто.
Вам понадобится аварийный менеджер EDB PostgreSQL (EFM). После загрузки и установки EFM на каждом основном и резервном узле можно создать кластер EFM, состоящий из основного узла, одного или нескольких резервных узлов и необязательного узла-свидетеля, подтверждающего утверждения в случае сбоя.
EFM постоянно отслеживает состояние системы и отправляет оповещения по электронной почте на основе системных событий. В случае сбоя он автоматически переключается на самый последний резервный сервер и переконфигурирует все остальные резервные серверы, чтобы они распознавали новый первичный узел.
Он также перенастраивает балансировщики нагрузки (такие как pgPool) и предотвращает «расщепленный мозг» (когда каждый из двух узлов считает себя первичным).
Резюме
Из-за больших объемов данных масштабируемость и безопасность стали двумя наиболее важными критериями в управлении базами данных, особенно в среде транзакций. Хотя мы можем улучшить масштабируемость по вертикали, добавив больше ресурсов/оборудования к существующим узлам, это не всегда возможно, часто из-за стоимости или ограничений добавления нового оборудования.
Следовательно, требуется горизонтальная масштабируемость, что означает добавление дополнительных узлов к существующим сетевым узлам, а не расширение функциональных возможностей существующих узлов. Именно здесь на сцену выходит репликация PostgreSQL.
В этой статье мы обсудили типы репликаций PostgreSQL, преимущества, режимы репликации, установку и аварийное переключение PostgreSQL между SMR и MMR. Теперь давайте послушаем вас.
Какой из них вы обычно реализуете? Какая функция базы данных для вас наиболее важна и почему? Мы будем рады прочитать ваши мысли! Поделитесь ими в разделе комментариев ниже.