
Robots.txt: Ce este și cum se creează (Ghid complet)
Publicat: 2023-05-05Dacă dețineți un site web sau gestionați conținutul acestuia, probabil ați auzit de robots.txt. Este un fișier care instruiește roboții motoarelor de căutare cum să acceseze cu crawlere și să indexeze paginile site-ului dvs. În ciuda importanței sale în optimizarea motoarelor de căutare (SEO), mulți proprietari de site-uri web trec cu vederea importanța unui fișier robots.txt bine conceput.
În acest ghid complet, vom explora ce este robots.txt, de ce este important pentru SEO și cum să creați un fișier robots.txt pentru site-ul dvs. web.
Ce este fișierul Robots.txt?
Un robots.txt este un fișier care le spune roboților motoarelor de căutare (cunoscuți și sub numele de crawler sau spider) care pagini sau secțiuni ale unui site ar trebui să fie accesate cu crawlere sau nu. Este un fișier text simplu situat în directorul rădăcină al unui site web și, de obicei, include o listă de directoare, fișiere sau adrese URL pe care webmasterul dorește să le blocheze de la indexarea sau accesarea cu crawlere a motorului de căutare.
Iată cum arată un fișier robots.txt:

De ce este important Robots.txt?
Există trei motive principale pentru care robots.txt este important pentru site-ul dvs. web:
1. Maximizați bugetul de accesare cu crawlere
„Buget de accesare cu crawlere” înseamnă numărul de pagini pe care Google le va accesa cu crawlere pe site-ul dvs. la un moment dat. Numărul depinde de dimensiunea, sănătatea și cantitatea de backlink-uri de pe site-ul dvs.
Bugetul de accesare cu crawlere este important deoarece, dacă numărul de pagini de pe site-ul dvs. depășește bugetul de accesare cu crawlere, veți avea pagini care nu sunt indexate.
În plus, paginile care nu sunt indexate nu se vor clasa pentru nimic.
Folosind robots.txt pentru a bloca pagini inutile, Googlebot (crawler-ul web al Google) poate cheltui mai mult din bugetul dvs. de accesare cu crawlere pe paginile care contează.
2. Blocați paginile non-publice
Aveți multe pagini pe site-ul dvs. pe care nu doriți să le indexați.
De exemplu, este posibil să aveți o pagină internă cu rezultatele căutării sau o pagină de conectare. Aceste pagini trebuie să existe. Cu toate acestea, nu doriți ca oameni aleatori să aterizeze pe ele.
În acest caz, ați folosi robots.txt pentru a împiedica accesarea crawlerilor și a botilor motoarelor de căutare la anumite pagini.
3. Preveniți indexarea resurselor
Uneori, veți dori ca Google să excludă resurse precum PDF-uri, videoclipuri și imagini din rezultatele căutării.
Posibil doriți să păstrați aceste resurse private sau doriți ca Google să se concentreze mai mult pe conținutul important.
În astfel de cazuri, utilizarea robots.txt este cea mai bună abordare pentru a preveni indexarea acestora.
Cum funcționează un fișier Robots.txt?
Fișierele Robots.txt indică roboților motoarelor de căutare ce pagini sau directoare ale site-ului ar trebui sau nu ar trebui să acceseze cu crawlere sau să indexeze.
În timpul accesării cu crawlere, roboții motoarelor de căutare găsesc și urmăresc linkuri. Acest proces îi conduce de la site-ul X la site-ul Y la site-ul Z peste miliarde de link-uri și site-uri web.
Când un bot vizitează un site, primul lucru pe care îl face este să caute un fișier robots.txt.
Dacă detectează unul, va citi fișierul înainte de a face orice altceva.
De exemplu, să presupunem că doriți să permiteți tuturor roboților, cu excepția lui DuckDuckGo, să vă acceseze cu crawlere site-ul:
User-agent: DuckDuckBot Disallow: /
Notă: un fișier robots.txt poate oferi doar instrucțiuni; nu le poate impune. Este similar cu un cod de conduită. Boții buni (cum ar fi roboții motoarelor de căutare) vor urma regulile, în timp ce boții răi (cum ar fi roții spam) le vor ignora.
Cum să găsiți un fișier Robots.txt?
Fișierul robots.txt, ca orice alt fișier de pe site-ul dvs. web, este găzduit pe serverul dvs.
Puteți accesa fișierul robots.txt al oricărui site web introducând adresa URL completă a paginii de pornire și apoi adăugând /robots.txt la sfârșit, cum ar fi https://pickupwp.com/robots.txt.
Cu toate acestea, dacă site-ul web nu are un fișier robots.txt, veți primi un mesaj de eroare „404 Not Found”.
Cum se creează un fișier Robots.txt?
Înainte de a arăta cum să creați un fișier robots.txt, să ne uităm mai întâi la sintaxa robots.txt.
Sintaxa unui fișier robots.txt poate fi împărțită în următoarele componente:
- User-agent: Acesta specifică robotul sau crawler-ul căruia i se aplică înregistrarea. De exemplu, „User-agent: Googlebot” s-ar aplica numai pentru crawler-ul de căutare Google, în timp ce „User-agent: *” s-ar aplica tuturor crawler-urilor.
- Disallow: Aceasta specifică paginile sau directoarele pe care robotul nu trebuie să le acceseze cu crawlere. De exemplu, „Disallow: /private/” ar împiedica roboții să acceseze cu crawlere orice pagină din directorul „privat”.
- Permite: Aceasta specifică paginile sau directoarele pe care robotul ar trebui să aibă voie să le acceseze cu crawlere, chiar dacă directorul părinte este interzis. De exemplu, „Permite: /public/” le-ar permite roboților să acceseze cu crawlere orice pagină din directorul „public”, chiar dacă directorul părinte este interzis.
- Întârziere cu crawlere: aceasta specifică perioada de timp în secunde pe care robotul ar trebui să aștepte înainte de a accesa cu crawlere site-ul web. De exemplu, „Crawl-delay: 10” va indica robotului să aștepte 10 secunde înainte de a accesa cu crawlere site-ul.
- Harta site-ului: aceasta specifică locația sitemap-ului site-ului. De exemplu, „Sitemap: https://www.example.com/sitemap.xml” ar informa robotul despre locația sitemap-ului site-ului.
Iată un exemplu de fișier robots.txt:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
Notă: este important să rețineți că fișierele robots.txt țin cont de majuscule și minuscule, așa că este important să folosiți majusculele corecte când specificați adresele URL.
De exemplu, /public/ nu este același lucru cu /Public/.
Pe de altă parte, directive precum „Permiteți” și „Renunțați” nu țin cont de majuscule și minuscule, așa că depinde de dvs. să le scrieți cu majuscule sau nu.
După ce ați aflat despre sintaxa robots.txt, puteți crea un fișier robots.txt folosind un instrument generator robots.txt sau puteți crea unul singur.
Iată cum să creați un fișier robots.txt în doar patru pași:
1. Creați un fișier nou și denumiți-l Robots.txt
Pur și simplu deschideți un document .txt cu orice editor de text sau browser web.
Apoi, dați documentului numele robots.txt. Pentru a funcționa, trebuie să fie numit robots.txt.
Odată terminat, acum puteți începe să tastați directive.
2. Adăugați directive în fișierul Robots.txt
Un fișier robots.txt conține unul sau mai multe grupuri de directive, fiecare cu mai multe rânduri de instrucțiuni.
Fiecare grup începe cu un „User-agent” și conține următoarele date:
- Cui se aplică grupul (agentul utilizator)
- Ce directoare (pagini) sau fișiere poate accesa agentul?
- Ce directoare (pagini) sau fișiere nu poate accesa agentul?
- O hartă a site-ului (opțional) pentru a informa motoarele de căutare despre site-urile și fișierele pe care le considerați importante.
Liniile care nu se potrivesc cu niciuna dintre aceste directive sunt ignorate de crawler-uri.

De exemplu, doriți să împiedicați Google să acceseze cu crawlere directorul dvs. /privat/.
Ar arata asa:
User-agent: Googlebot Disallow: /private/
Dacă ați avea mai multe instrucțiuni de acest fel pentru Google, le-ați pune într-o linie separată direct dedesubt, astfel:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
În plus, dacă ați terminat cu instrucțiunile specifice Google și doriți să creați un nou grup de directive.
De exemplu, dacă doriți să împiedicați toate motoarele de căutare să acceseze cu crawlere directoarele dvs. /archive/ și /support/.
Ar arata asa:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
Când ați terminat, puteți adăuga harta site-ului.
Fișierul dvs. robots.txt completat ar trebui să arate astfel:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
Apoi, salvați fișierul robots.txt. Rețineți, trebuie să fie numit robots.txt.
Pentru reguli robots.txt mai utile, consultați acest ghid util de la Google.
3. Încărcați fișierul Robots.txt
După ce salvați fișierul robots.txt pe computer, încărcați-l pe site-ul dvs. web și faceți-l disponibil pentru ca motoarele de căutare să poată fi accesat cu crawlere.
Din păcate, nu există niciun instrument care să poată ajuta cu acest pas.
Încărcarea fișierului robots.txt depinde de structura fișierelor site-ului dvs. și de găzduirea web.
Pentru instrucțiuni despre cum să încărcați fișierul robots.txt, căutați online sau contactați furnizorul dvs. de găzduire.
4. Testați-vă Robots.txt
După ce ați încărcat fișierul robots.txt, apoi puteți verifica dacă cineva îl poate vedea și dacă Google îl poate citi.
Pur și simplu deschideți o filă nouă în browser și căutați fișierul robots.txt.
De exemplu, https://pickupwp.com/robots.txt.
Dacă vedeți fișierul robots.txt, sunteți gata să testați marcajul (cod HTML).
Pentru aceasta, puteți folosi un tester Google robots.txt.
Notă: aveți un cont Search Console configurat pentru a vă testa fișierul robots.txt utilizând robots.txt Tester.
Testerul robots.txt va găsi orice avertismente de sintaxă sau erori de logică și le va evidenția.
În plus, vă arată și avertismentele și erorile de sub editor.
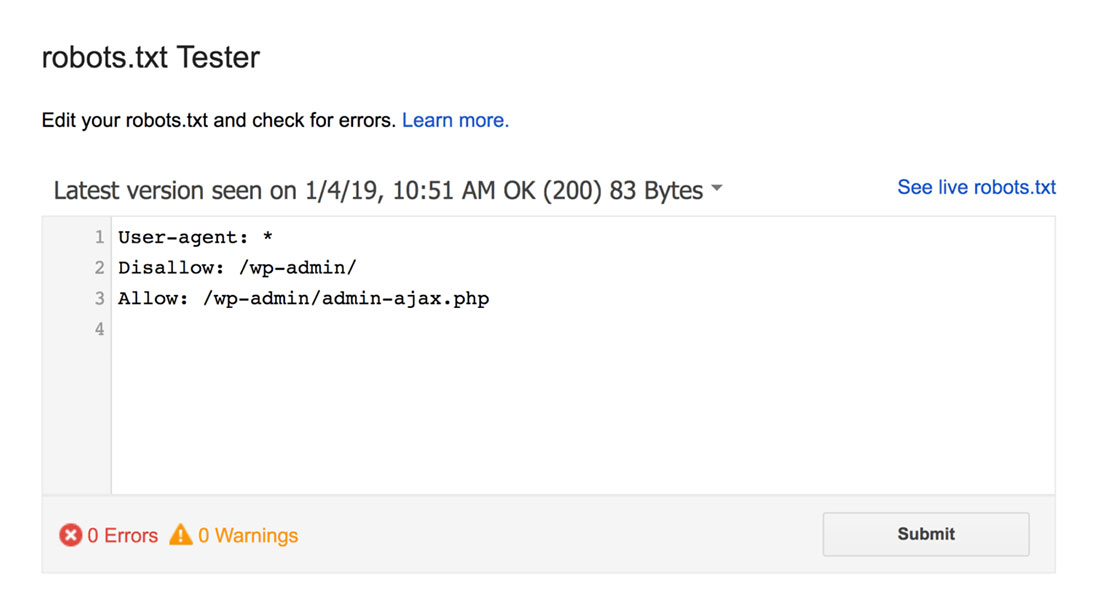
Puteți edita erorile sau avertismentele de pe pagină și puteți testa din nou ori de câte ori este necesar.
Rețineți că modificările făcute pe pagină nu sunt salvate pe site-ul dvs.
Pentru a face modificări, copiați și inserați acest lucru în fișierul robots.txt al site-ului dvs.
Cele mai bune practici Robots.txt
Țineți cont de aceste bune practici atunci când creați fișierul robots.txt pentru a evita unele greșeli obișnuite.
1. Utilizați linii noi pentru fiecare directivă
Pentru a preveni confuzia pentru crawlerele motoarelor de căutare, adăugați fiecare directivă într-o nouă linie din fișierul robots.txt. Acest lucru se aplică atât regulilor de permis, cât și de respingere.
De exemplu, dacă nu doriți ca un crawler web să vă acceseze cu crawlere blogul sau pagina de contact, adăugați următoarele reguli:
Disallow: /blog/ Disallow: /contact/
2. Utilizați fiecare agent utilizator o singură dată
Boții nu au nicio problemă dacă folosiți același user agent din nou și din nou.
Cu toate acestea, folosirea lui o singură dată menține lucrurile organizate și reduce șansa de eroare umană.
3. Folosiți wildcards pentru a simplifica instrucțiunile
Dacă aveți un număr mare de pagini de blocat, adăugarea unei reguli pentru fiecare ar putea fi consumatoare de timp. Din fericire, puteți folosi metacaracterele pentru a vă simplifica instrucțiunile.
Un wildcard este un caracter care poate reprezenta unul sau mai multe caractere. Cel mai frecvent utilizat wildcard este asteriscul (*).
De exemplu, dacă doriți să blocați toate fișierele care se termină în .jpg, ați adăuga următoarea regulă:
Disallow: /*.jpg
4. Folosiți „$” pentru a specifica sfârșitul unei adrese URL
Semnul dolar ($) este un alt caracter joker care poate fi folosit pentru a identifica sfârșitul unei adrese URL. Acest lucru este util dacă doriți să restricționați o anumită pagină, dar nu și pe cele de după ea.
Să presupunem că doriți să blocați pagina de contact, dar nu pagina de contact-succes, ați adăuga următoarea regulă:
Disallow: /contact$
5. Folosiți hash (#) pentru a adăuga comentarii
Tot ceea ce începe cu un hash (#) este ignorat de crawler-uri.
Drept urmare, dezvoltatorii folosesc adesea hash-ul pentru a adăuga comentarii la fișierul robots.txt. Păstrează documentul organizat și lizibil.
De exemplu, dacă doriți să împiedicați toate fișierele care se termină cu .jpg, puteți adăuga următorul comentariu:
# Block all files that end in .jpg Disallow: /*.jpg
Acest lucru ajută pe oricine să înțeleagă pentru ce este regula și de ce există.
6. Utilizați fișiere Robots.txt separate pentru fiecare subdomeniu
Dacă aveți un site web care are mai multe subdomenii, este recomandat să creați un fișier robots.txt individual pentru fiecare. Acest lucru menține lucrurile organizate și îi ajută pe crawlerele motoarelor de căutare să înțeleagă regulile dvs. mai ușor.
Încheierea!
Fișierul robots.txt este un instrument SEO util, deoarece îi instruiește pe motoarele de căutare ce să indexeze și ce să nu.
Cu toate acestea, este important să-l utilizați cu prudență. Deoarece o configurare greșită poate duce la deindexarea completă a site-ului dvs. (de exemplu, folosind Disallow: /).
În general, modalitatea bună este să permiteți motoarele de căutare să scaneze cât mai mult site-ul dvs., păstrând în același timp informațiile sensibile și evitând conținutul duplicat. De exemplu, puteți utiliza directiva Disallow pentru a preveni anumite pagini sau directoare sau directiva Allow pentru a înlocui o regulă Disallow pentru o anumită pagină.
De asemenea, merită menționat faptul că nu toți roboții respectă regulile furnizate în fișierul robots.txt, deci nu este o metodă perfectă pentru a controla ceea ce este indexat. Dar este totuși un instrument valoros pe care trebuie să-l ai în strategia ta SEO.
Sperăm că acest ghid vă va ajuta să aflați ce este un fișier robots.txt și cum să creați unul.
Pentru mai multe, puteți consulta aceste alte resurse utile:
- 15 sfaturi utile pentru blogging pentru bloggeri noi
- Deblocarea puterii cuvintelor cheie cu coadă lungă (Ghid pentru începători)
În cele din urmă, urmăriți-ne pe Twitter pentru actualizări regulate despre articole noi.