
Replicare PostgreSQL: un ghid cuprinzător
Publicat: 2022-08-11După cum vă va spune orice proprietar de site, pierderea de date și timpul de nefuncționare, chiar și în doze minime, pot fi catastrofale. Ele pot lovi oricând pe cei nepregătiți, ceea ce duce la o productivitate redusă, accesibilitate și încredere în produs.
Pentru a proteja integritatea site-ului dvs., este vital să construiți garanții împotriva posibilității de nefuncționare sau pierderi de date.
Aici intervine replicarea datelor.
Replicarea datelor este un proces de backup automat în care datele dumneavoastră sunt copiate în mod repetat din baza de date principală într-o altă locație, la distanță, pentru păstrare în siguranță. Este o tehnologie integrală pentru orice site sau aplicație care rulează un server de baze de date. De asemenea, puteți utiliza baza de date replicată pentru a procesa SQL numai în citire, permițând rularea mai multor procese în sistem.
Configurarea replicării între două baze de date oferă toleranță la erori împotriva accidentelor neașteptate. Este considerată cea mai bună strategie pentru a obține o disponibilitate ridicată în timpul dezastrelor.
În acest articol, ne vom scufunda în diferitele strategii care pot fi implementate de dezvoltatorii backend pentru o replicare fără întreruperi PostgreSQL.
Ce este replicarea PostgreSQL?
Replicarea PostgreSQL este definită ca procesul de copiere a datelor de pe un server de baze de date PostgreSQL pe un alt server. Serverul bazei de date sursă este cunoscut și ca server „primar”, în timp ce serverul bazei de date care primește datele copiate este cunoscut ca server „replica”.
Baza de date PostgreSQL urmează un model de replicare simplu, în care toate scrierile merg la un nod primar. Nodul primar poate aplica apoi aceste modificări și le poate difuza către nodurile secundare.
Ce este failoverul automat?
Odată ce replicarea fizică în flux a fost configurată în PostgreSQL, failover-ul poate avea loc dacă serverul principal al bazei de date eșuează. Failover-ul este utilizat pentru a defini procesul de recuperare, care poate dura ceva timp, deoarece nu oferă instrumente încorporate pentru a identifica defecțiunile serverului.
Nu trebuie să fiți dependent de PostgreSQL pentru failover. Există instrumente dedicate care permit failover-ul automat și trecerea automată în standby, reducând timpul de nefuncționare a bazei de date.
Prin configurarea replicării cu failover, aproape garantați disponibilitatea ridicată, asigurându-vă că standby-urile sunt disponibile în cazul în care serverul principal se prăbușește vreodată.
Beneficiile utilizării replicării PostgreSQL
Iată câteva beneficii cheie ale utilizării replicării PostgreSQL:
- Migrarea datelor : Puteți utiliza replicarea PostgreSQL pentru migrarea datelor fie printr-o schimbare a hardware-ului serverului de baze de date, fie prin implementarea sistemului.
- Toleranță la erori : Dacă serverul primar eșuează, serverul de așteptare poate acționa ca un server, deoarece datele conținute atât pentru serverul primar, cât și pentru serverul de așteptare sunt aceleași.
- Performanța procesării tranzacțiilor online (OLTP) : puteți îmbunătăți timpul de procesare a tranzacțiilor și timpul de interogare a unui sistem OLTP eliminând încărcarea interogărilor de raportare. Timpul de procesare a tranzacției este durata necesară pentru ca o anumită interogare să fie executată înainte ca o tranzacție să se încheie.
- Testarea sistemului în paralel : în timp ce actualizați un nou sistem, trebuie să vă asigurați că sistemul se descurcă bine cu datele existente, de unde trebuie să testați cu o copie a bazei de date de producție înainte de implementare.
Cum funcționează replicarea PostgreSQL
În general, oamenii cred că atunci când te distragi cu o arhitectură primară și secundară, există o singură modalitate de a configura copii de rezervă și replicare, dar implementările PostgreSQL urmează una dintre următoarele trei abordări:
- Replicare la nivel de volum pentru a se replica la nivelul de stocare de la nodul primar la cel secundar, urmată de o copie de rezervă în stocarea blob/S3.
- Replicare în flux PostgreSQL pentru a replica datele de la nodul primar la cel secundar, urmată de o copie de rezervă în stocarea blob/S3.
- Realizarea de backup-uri incrementale de la nodul primar la S3 în timp ce se reconstruiește un nou nod secundar de la S3. Când nodul secundar se află în vecinătatea nodului primar, puteți începe transmiterea de la nodul principal.
Abordarea 1: Streaming
Replicarea în flux PostgreSQL, cunoscută și sub numele de replicare WAL, poate fi configurată fără probleme după instalarea PostgreSQL pe toate serverele. Această abordare a replicării se bazează pe mutarea fișierelor WAL din baza de date primară în baza de date țintă.
Puteți implementa replicarea în flux PostgreSQL utilizând o configurație primar-secundar. Serverul primar este instanța principală care se ocupă de baza de date primară și de toate operațiunile acesteia. Serverul secundar acționează ca instanță suplimentară și execută toate modificările aduse bazei de date primare pe sine, generând o copie identică în proces. Primarul este serverul de citire/scriere, în timp ce serverul secundar este doar de citire.
Pentru această abordare, trebuie să configurați atât nodul primar, cât și nodul de așteptare. Următoarele secțiuni vor elucida pașii implicați în configurarea lor cu ușurință.
Configurarea nodului primar
Puteți configura nodul primar pentru replicarea în flux, parcurgând următorii pași:
Pasul 1: Inițializați baza de date
Pentru a inițializa baza de date, puteți utiliza comanda initidb utility . Apoi, puteți crea un utilizator nou cu privilegii de replicare utilizând următoarea comandă:
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';Utilizatorul va trebui să furnizeze o parolă și un nume de utilizator pentru interogarea dată. Cuvântul cheie de replicare este folosit pentru a oferi utilizatorului privilegiile necesare. Un exemplu de interogare ar arăta cam așa:
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'Pasul 2: Configurați proprietățile de streaming
Apoi, puteți configura proprietățile de streaming cu fișierul de configurare PostgreSQL ( postgresql.conf ) care poate fi modificat după cum urmează:
wal_level = logical wal_log_hints = on max_wal_senders = 8 max_wal_size = 1GB hot_standby = onIată un mic fundal despre parametrii utilizați în fragmentul anterior:
-
wal_log_hints: Acest parametru este necesar pentru capacitateapg_rewind, care este utilă atunci când serverul de așteptare nu este sincronizat cu serverul principal. -
wal_level: Puteți utiliza acest parametru pentru a activa replicarea în flux PostgreSQL, cu valori posibile, inclusivminimal,replicasaulogical. -
max_wal_size: Aceasta poate fi folosită pentru a specifica dimensiunea fișierelor WAL care pot fi reținute în fișierele jurnal. -
hot_standby: Puteți utiliza acest parametru pentru o conexiune de citire cu secundarul atunci când este setat la ON. -
max_wal_senders: Puteți utilizamax_wal_senderspentru a specifica numărul maxim de conexiuni simultane care pot fi stabilite cu serverele de așteptare.
Pasul 3: Creați o intrare nouă
După ce ați modificat parametrii din fișierul postgresql.conf, o nouă intrare de replicare în fișierul pg_hba.conf poate permite serverelor să stabilească o conexiune între ele pentru replicare.
De obicei, puteți găsi acest fișier în directorul de date al PostgreSQL. Puteți utiliza următorul fragment de cod pentru același lucru:
host replication rep_user IPaddress md5 Odată ce fragmentul de cod este executat, serverul principal permite unui utilizator numit rep_user să se conecteze și să acționeze ca server de așteptare utilizând IP-ul specificat pentru replicare. De exemplu:
host replication rep_user 192.168.0.22/32 md5Configurarea Standby Node
Pentru a configura nodul de așteptare pentru replicarea în flux, urmați acești pași:
Pasul 1: Faceți backup pentru nodul primar
Pentru a configura nodul de așteptare, utilizați utilitarul pg_basebackup pentru a genera o copie de rezervă a nodului primar. Acesta va servi ca punct de plecare pentru nodul de așteptare. Puteți utiliza acest utilitar cu următoarea sintaxă:
pg_basebackp -D -h -X stream -c fast -U rep_user -WParametrii utilizați în sintaxa menționată mai sus sunt următorii:
-
-h: Puteți folosi acest lucru pentru a menționa gazda principală. -
-D: Acest parametru indică directorul la care lucrați în prezent. -
-C: Puteți folosi acest lucru pentru a seta punctele de control. -
-X: Acest parametru poate fi utilizat pentru a include fișierele jurnal tranzacționale necesare. -
-W: Puteți utiliza acest parametru pentru a solicita utilizatorului o parolă înainte de a vă conecta la baza de date.
Pasul 2: Configurați fișierul de configurare de replicare
Apoi, trebuie să verificați dacă fișierul de configurare de replicare există. Dacă nu, puteți genera fișierul de configurare a replicirii ca recovery.conf.
Ar trebui să creați acest fișier în directorul de date al instalării PostgreSQL. Îl puteți genera automat utilizând opțiunea -R din utilitarul pg_basebackup .
Fișierul recovery.conf ar trebui să conțină următoarele comenzi:
standby_mode = 'pornit'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<parola> application_name=”host_name”'
recovery_target_timeline = „cel mai recent”
Parametrii utilizați în comenzile menționate mai sus sunt următorii:
-
primary_conninfo: Puteți utiliza acest lucru pentru a realiza o conexiune între serverele primare și secundare utilizând un șir de conexiune. -
standby_mode: Acest parametru poate face ca serverul principal să pornească ca standby atunci când este pornit. -
recovery_target_timeline: Puteți folosi acest lucru pentru a seta timpul de recuperare.
Pentru a configura o conexiune, trebuie să furnizați numele de utilizator, adresa IP și parola ca valori pentru parametrul primary_conninfo. De exemplu:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Pasul 3: Reporniți serverul secundar
În cele din urmă, puteți reporni serverul secundar pentru a finaliza procesul de configurare.
Cu toate acestea, replicarea în flux vine cu mai multe provocări, cum ar fi:
- Diferiți clienți PostgreSQL (scriși în diferite limbaje de programare) conversează cu un singur punct final. Când nodul primar eșuează, acești clienți vor continua să reîncerce același nume DNS sau IP. Acest lucru face ca failoverul să fie vizibil pentru aplicație.
- Replicarea PostgreSQL nu vine cu failover și monitorizare încorporate. Când nodul primar eșuează, trebuie să promovați un nod secundar pentru a fi noul primar. Această promovare trebuie să fie executată într-un mod în care clienții scrie doar la un singur nod principal și nu observă inconsecvențele de date.
- PostgreSQL își reproduce întreaga stare. Când trebuie să dezvoltați un nou nod secundar, cel secundar trebuie să recapituleze întregul istoric al schimbării stării de la nodul primar, ceea ce necesită mult resurse și face costisitoare eliminarea nodurilor din cap și crearea altora noi.
Abordarea 2: Dispozitiv bloc replicat
Abordarea dispozitivului bloc replicat depinde de oglindirea discului (cunoscută și sub denumirea de replicare a volumului). În această abordare, modificările sunt scrise pe un volum persistent care este reflectat sincron pe un alt volum.
Avantajul suplimentar al acestei abordări este compatibilitatea și durabilitatea datelor în mediile cloud cu toate bazele de date relaționale, inclusiv PostgreSQL, MySQL și SQL Server, pentru a numi câteva.
Cu toate acestea, abordarea de oglindire a discului pentru replicarea PostgreSQL necesită să replicați atât jurnalul WAL, cât și datele tabelului. Deoarece fiecare scriere în baza de date trebuie acum să treacă prin rețea sincron, nu vă puteți permite să pierdeți un singur octet, deoarece asta ar putea lăsa baza de date într-o stare coruptă.
Această abordare este în mod normal utilizată folosind Azure PostgreSQL și Amazon RDS.
Abordarea 3: WAL
WAL este format din fișiere segmente (16 MB în mod implicit). Fiecare segment are una sau mai multe înregistrări. O înregistrare a secvenței de jurnal (LSN) este un indicator către o înregistrare în WAL, permițându-vă să cunoașteți poziția/locația în care înregistrarea a fost salvată în fișierul jurnal.
Un server de așteptare folosește segmentele WAL – cunoscute și ca XLOGS în terminologia PostgreSQL – pentru a replica continuu modificările de pe serverul său principal. Puteți utiliza înregistrarea de tip write-ahead pentru a oferi durabilitate și atomicitate într-un DBMS prin serializarea unor bucăți de date din matrice de octeți (fiecare cu un LSN unic) la stocare stabilă înainte de a fi aplicate unei baze de date.
Aplicarea unei mutații la o bază de date poate duce la diferite operațiuni ale sistemului de fișiere. O întrebare relevantă care apare este modul în care o bază de date poate asigura atomicitatea în cazul unei defecțiuni a serverului din cauza unei întreruperi de curent în timp ce se afla în mijlocul unei actualizări a sistemului de fișiere. Când o bază de date pornește, începe un proces de pornire sau de reluare care poate citi segmentele WAL disponibile și le compară cu LSN-ul stocat pe fiecare pagină de date (fiecare pagină de date este marcată cu LSN-ul celei mai recente înregistrări WAL care afectează pagina).
Replicare bazată pe expediere a jurnalelor (nivel de bloc)
Replicarea în flux rafinează procesul de expediere a jurnalelor. Spre deosebire de așteptarea comutatorului WAL, înregistrările sunt trimise pe măsură ce sunt create, scăzând astfel întârzierea de replicare.
Replicarea în flux depășește, de asemenea, expedierea jurnalelor, deoarece serverul de așteptare se conectează cu serverul principal prin intermediul rețelei utilizând un protocol de replicare. Serverul primar poate trimite apoi înregistrări WAL direct prin această conexiune, fără a fi nevoit să depindă de scripturile furnizate de utilizatorul final.
Replicare bazată pe expediere a jurnalelor (nivel de fișier)
Expedierea jurnalelor este definită ca copierea fișierelor jurnal pe alt server PostgreSQL pentru a genera un alt server de așteptare prin reluarea fișierelor WAL. Acest server este configurat să funcționeze în modul de recuperare și unicul său scop este să aplice orice fișiere WAL noi pe măsură ce apar.
Acest server secundar devine apoi o copie de rezervă caldă a serverului PostgreSQL primar. De asemenea, poate fi configurat pentru a fi o replică de citire, unde poate oferi interogări doar pentru citire, denumite și standby la cald.
Arhivare WAL continuă
Duplicarea fișierelor WAL pe măsură ce sunt create în orice altă locație decât subdirectorul pg_wal pentru a le arhiva este cunoscută ca arhivare WAL. PostgreSQL va apela un script dat de utilizator pentru arhivare, de fiecare dată când este creat un fișier WAL.
Scriptul poate folosi comanda scp pentru a duplica fișierul într-una sau mai multe locații, cum ar fi o montare NFS. Odată arhivate, fișierele segmentului WAL pot fi utilizate pentru a recupera baza de date la orice moment dat.
Alte configurații bazate pe jurnal includ:
- Replicare sincronă : înainte ca fiecare tranzacție de replicare sincronă să fie comisă, serverul principal așteaptă până când cei de așteptare confirmă că au primit datele. Avantajul acestei configurații este că nu vor exista conflicte cauzate din cauza proceselor de scriere paralelă.
- Replicare multi-master sincronă : aici, fiecare server poate accepta cereri de scriere, iar datele modificate sunt transmise de la serverul original la fiecare alt server înainte ca fiecare tranzacție să fie comisă. Utilizează protocolul 2PC și respectă regula totul sau nimic.
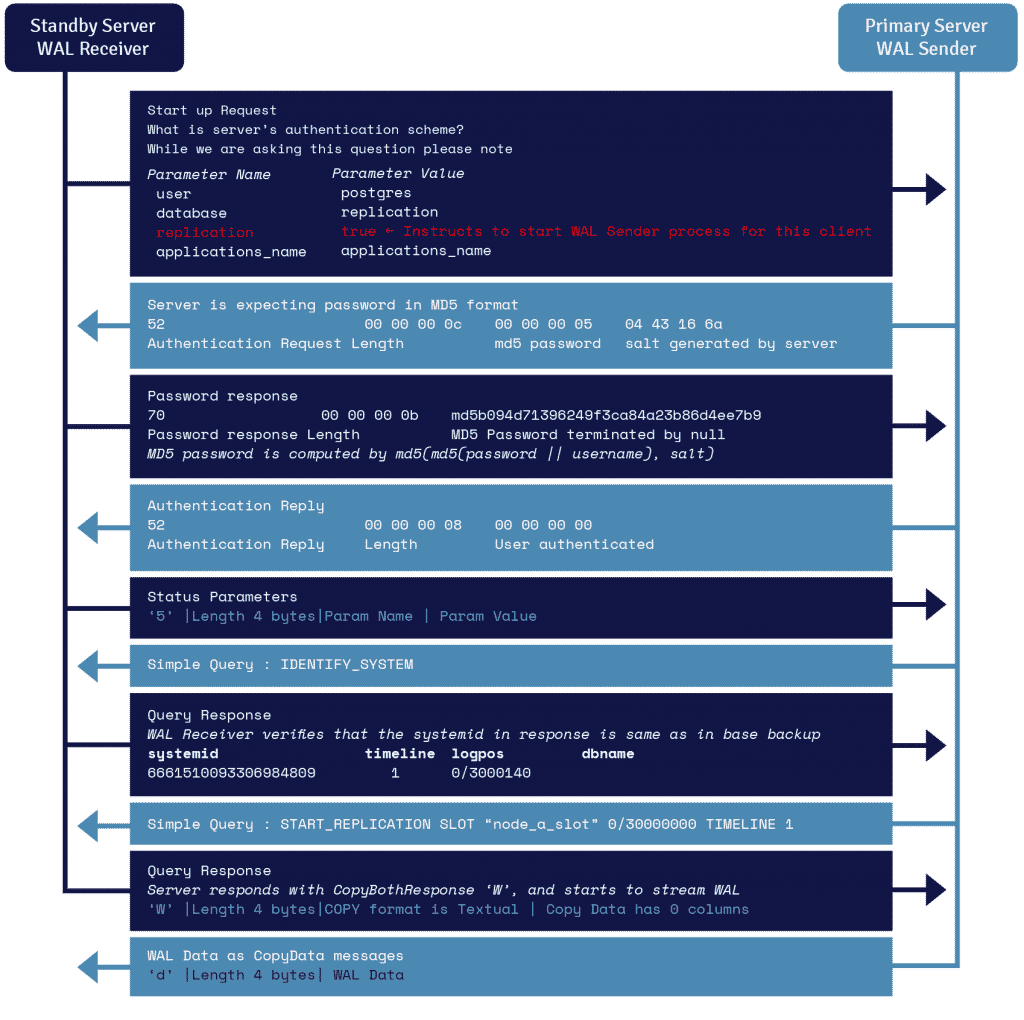
Detalii WAL Streaming Protocol
Un proces cunoscut sub numele de receptor WAL, care rulează pe serverul de așteptare, folosește detaliile de conexiune furnizate în parametrul primary_conninfo din recovery.conf și se conectează la serverul primar utilizând o conexiune TCP/IP.
Pentru a începe replicarea în flux, interfața poate trimite parametrul de replicare în mesajul de pornire. O valoare booleană true, yes, 1 sau ON informează backend-ul că trebuie să intre în modul walsender de replicare fizică.
WAL sender este un alt proces care rulează pe serverul primar și este responsabil de trimiterea înregistrărilor WAL către serverul de așteptare pe măsură ce sunt generate. Receptorul WAL salvează înregistrările WAL în WAL ca și cum ar fi fost create de activitatea clientului clienților conectați local.

Odată ce înregistrările WAL ajung la fișierele segmentului WAL, serverul de așteptare continuă să redă în mod constant WAL-ul, astfel încât principalul și cel de așteptare să fie actualizate.
Elemente de replicare PostgreSQL
În această secțiune, veți obține o înțelegere mai profundă a modelelor utilizate în mod obișnuit (replicare cu un singur master și multi-master), tipuri (replicare fizică și logică) și moduri (sincrone și asincrone) de replicare PostgreSQL.
Modele de replicare a bazelor de date PostgreSQL
Scalabilitate înseamnă adăugarea mai multor resurse/hardware la nodurile existente pentru a spori capacitatea bazei de date de a stoca și procesa mai multe date care pot fi obținute pe orizontală și pe verticală. Replicarea PostgreSQL este un exemplu de scalabilitate orizontală, care este mult mai dificil de implementat decât scalabilitatea verticală. Putem realiza scalabilitate orizontală în principal prin replicarea single-master (SMR) și replicarea multi-master (MMR).
Replicarea single-master permite ca datele să fie modificate doar pe un singur nod, iar aceste modificări sunt replicate la unul sau mai multe noduri. Tabelele replicate din baza de date replica nu au permisiunea de a accepta modificări, cu excepția celor de la serverul primar. Chiar dacă o fac, modificările nu sunt replicate înapoi pe serverul principal.
De cele mai multe ori, SMR este suficient pentru aplicație, deoarece este mai puțin complicat de configurat și gestionat, fără șanse de conflicte. Replicarea single-master este, de asemenea, unidirecțională, deoarece datele de replicare circulă în principal într-o singură direcție, de la baza de date primară la cea de replică.
În unele cazuri, SMR singur poate să nu fie suficient și poate fi necesar să implementați MMR. MMR permite mai mult de un nod să acționeze ca nod primar. Modificările la rândurile de tabel din mai mult de o bază de date primară desemnată sunt replicate în tabelele lor omoloage din orice altă bază de date primară. În acest model, schemele de rezolvare a conflictelor sunt adesea folosite pentru a evita probleme precum cheile primare duplicate.
Există câteva avantaje în utilizarea MMR, și anume:
- În cazul eșecului gazdei, alte gazde pot oferi în continuare servicii de actualizare și inserare.
- Nodurile primare sunt răspândite în mai multe locații diferite, astfel încât șansa de eșec a tuturor nodurilor primare este foarte mică.
- Abilitatea de a folosi o rețea de arie largă (WAN) de baze de date primare care pot fi apropiate din punct de vedere geografic de grupuri de clienți, menținând totuși coerența datelor în întreaga rețea.
Cu toate acestea, dezavantajul implementării MMR este complexitatea și dificultatea acesteia de a rezolva conflictele.
Mai multe ramuri și aplicații oferă soluții MMR, deoarece PostgreSQL nu le acceptă în mod nativ. Aceste soluții pot fi open-source, gratuite sau plătite. O astfel de extensie este replicarea bidirecțională (BDR), care este asincronă și se bazează pe funcția de decodare logică PostgreSQL.
Deoarece aplicația BDR redă tranzacțiile pe alte noduri, operația de redare poate eșua dacă există un conflict între tranzacția aplicată și tranzacția comisă pe nodul receptor.
Tipuri de replicare PostgreSQL
Există două tipuri de replicare PostgreSQL: replicare logică și replicare fizică.
O operațiune logică simplă „initdb” ar realiza operația fizică de a crea un director de bază pentru un cluster. La fel, o operațiune logică simplă „CREATE DATABASE” ar efectua operația fizică de creare a unui subdirector în directorul de bază.
Replicarea fizică se ocupă de obicei de fișiere și directoare. Nu știe ce reprezintă aceste fișiere și directoare. Aceste metode sunt folosite pentru a menține o copie completă a datelor întregii unui singur cluster, de obicei pe o altă mașină, și sunt efectuate la nivel de sistem de fișiere sau la nivel de disc și folosesc adrese exacte de bloc.
Replicarea logică este o modalitate de reproducere a entităților de date și a modificărilor acestora, pe baza identității de replicare a acestora (de obicei, o cheie primară). Spre deosebire de replicarea fizică, se ocupă de baze de date, tabele și operațiuni DML și se face la nivel de cluster de baze de date. Utilizează un model de publicare și abonare în care unul sau mai mulți abonați sunt abonați la una sau mai multe publicații pe un nod de editor .
Procesul de replicare începe prin realizarea unui instantaneu al datelor din baza de date a editorului și apoi copierea acestuia către abonat. Abonații extrag date din publicațiile la care sunt abonați și pot republica datele ulterior pentru a permite replicarea în cascadă sau configurații mai complexe. Abonatul aplică datele în aceeași ordine ca și editorul, astfel încât consecvența tranzacțională să fie garantată pentru publicațiile dintr-un singur abonament cunoscut și sub denumirea de replicare tranzacțională.
Cazurile de utilizare tipice pentru replicarea logică sunt:
- Trimiterea modificărilor incrementale într-o singură bază de date (sau un subset al unei baze de date) către abonați pe măsură ce apar.
- Partajarea unui subset al bazei de date între mai multe baze de date.
- Declanșarea declanșării modificărilor individuale pe măsură ce ajung la abonat.
- Consolidarea mai multor baze de date într-una singură.
- Oferirea accesului la date replicate diferitelor grupuri de utilizatori.
Baza de date abonaților se comportă în același mod ca orice altă instanță PostgreSQL și poate fi folosită ca editor pentru alte baze de date prin definirea publicațiilor sale.
Când abonatul este tratat ca fiind doar în citire de către aplicație, nu vor exista conflicte de la un singur abonament. Pe de altă parte, dacă există alte scrieri efectuate fie de o aplicație, fie de alți abonați la același set de tabele, pot apărea conflicte.
PostgreSQL acceptă ambele mecanisme simultan. Replicarea logică permite un control fin atât asupra replicării datelor, cât și asupra securității.
Moduri de replicare
Există în principal două moduri de replicare PostgreSQL: sincronă și asincronă. Replicarea sincronă permite ca datele să fie scrise atât pe serverul primar, cât și pe cel secundar în același timp, în timp ce replicarea asincronă asigură că datele sunt scrise mai întâi pe gazdă și apoi copiate pe serverul secundar.
În replicarea în modul sincron, tranzacțiile din baza de date primară sunt considerate complete numai atunci când acele modificări au fost replicate la toate replicile. Serverele de replică trebuie să fie disponibile tot timpul pentru ca tranzacțiile să fie finalizate pe primar. Modul sincron de replicare este utilizat în mediile tranzacționale de vârf cu cerințe de failover imediate.
În modul asincron, tranzacțiile pe serverul primar pot fi declarate finalizate atunci când modificările au fost efectuate doar pe serverul principal. Aceste modificări sunt apoi replicate în replici mai târziu. Serverele de replică pot rămâne nesincronizate pentru o anumită perioadă, numită întârziere de replicare. În cazul unui accident, poate apărea pierderea de date, dar supraîncărcarea oferită de replicarea asincronă este mică, deci este acceptabilă în majoritatea cazurilor (nu supraîncărcează gazda). Failover-ul de la baza de date primară la baza de date secundară durează mai mult decât replicarea sincronă.
Cum se configurează replicarea PostgreSQL
Pentru această secțiune, vom demonstra cum să configurați procesul de replicare PostgreSQL pe un sistem de operare Linux. În acest caz, vom folosi Ubuntu 18.04 LTS și PostgreSQL 10.
Să pătrundem!
Instalare
Veți începe prin a instala PostgreSQL pe Linux cu acești pași:
- În primul rând, ar trebui să importați cheia de semnare PostgreSQL tastând comanda de mai jos în terminal:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Apoi, adăugați depozitul PostgreSQL tastând comanda de mai jos în terminal:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Actualizați indexul depozitului tastând următoarea comandă în terminal:
sudo apt-get update - Instalați pachetul PostgreSQL folosind comanda apt:
sudo apt-get install -y postgresql-10 - În cele din urmă, setați parola pentru utilizatorul PostgreSQL utilizând următoarea comandă:
sudo passwd postgres
Instalarea PostgreSQL este obligatorie atât pentru serverul primar, cât și pentru cel secundar înainte de a începe procesul de replicare PostgreSQL.
După ce ați configurat PostgreSQL pentru ambele servere, puteți trece la configurarea de replicare a serverului principal și secundar.
Configurarea replicării pe serverul primar
Efectuați acești pași după ce ați instalat PostgreSQL atât pe serverele primare, cât și pe cele secundare.
- În primul rând, conectați-vă la baza de date PostgreSQL cu următoarea comandă:
su - postgres - Creați un utilizator de replicare cu următoarea comandă:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Editați pg_hba.cnf cu orice aplicație nano din Ubuntu și adăugați următoarea configurație: comanda de editare a fișierului
nano /etc/postgresql/10/main/pg_hba.confPentru a configura fișierul, utilizați următoarea comandă:
host replication replication MasterIP/24 md5 - Deschideți și editați postgresql.conf și puneți următoarea configurație în serverul principal:
nano /etc/postgresql/10/main/postgresql.confUtilizați următoarele setări de configurare:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - În cele din urmă, reporniți PostgreSQL pe serverul principal principal:
systemctl restart postgresqlAcum ați finalizat configurarea pe serverul principal.
Configurarea replicării pe serverul secundar
Urmați acești pași pentru a configura replicarea pe serverul secundar:
- Conectați-vă la PostgreSQL RDMS cu comanda de mai jos:
su - postgres - Opriți serviciul PostgreSQL să funcționeze pentru a ne permite să lucrăm la el cu comanda de mai jos:
systemctl stop postgresql - Editați fișierul pg_hba.conf cu această comandă și adăugați următoarea configurație:
Comanda Editarenano /etc/postgresql/10/main/pg_hba.confConfigurare
host replication replication MasterIP/24 md5 - Deschideți și editați postgresql.conf pe serverul secundar și puneți următoarea configurație sau decomentați dacă este comentat: Edit Command
Configurarenano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP este adresa serverului secundar
- Accesați directorul de date PostgreSQL din serverul secundar și eliminați totul:
cd /var/lib/postgresql/10/mainrm -rfv * - Copiați fișierele din directorul de date al serverului primar PostgreSQL în directorul de date al serverului secundar PostgreSQL și scrieți această comandă pe serverul secundar:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - Introduceți parola PostgreSQL a serverului principal și apăsați pe Enter. Apoi, adăugați următoarea comandă pentru configurația de recuperare: Edit Command
nano /var/lib/postgresql/10/main/recovery.confConfigurare
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Aici, YOUR_PASSWORD este parola pentru utilizatorul de replicare pe serverul primar creat de PostgreSQL
- Odată ce parola a fost setată, va trebui să reporniți baza de date secundară PostgreSQL, deoarece a fost oprită:
systemctl start postgresqlTestarea configurației dvs
Acum că am efectuat pașii, să testăm procesul de replicare și să observăm baza de date a serverului secundar. Pentru aceasta, creăm un tabel în serverul primar și observăm dacă același lucru se reflectă și pe serverul secundar.
Să ajungem la asta.
- Deoarece creăm tabelul pe serverul principal, va trebui să vă conectați la serverul principal:
su - postgres psql - Acum creăm un tabel simplu numit „testtable” și inserăm date în tabel rulând următoarele interogări PostgreSQL în terminal:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Observați baza de date PostgreSQL a serverului secundar, conectându-vă la serverul secundar:
su - postgres psql - Acum, verificăm dacă tabelul „testtable” există și poate returna datele rulând următoarele interogări PostgreSQL în terminal. Această comandă afișează în esență întregul tabel.
select * from testtable;
Aceasta este rezultatul tabelului de testare:
| websites | ------------------- | section.com | | google.com | | github.com | --------------------Ar trebui să puteți observa aceleași date ca și cele de pe serverul principal.
Dacă vedeți cele de mai sus, atunci ați efectuat cu succes procesul de replicare!
Care sunt pașii manuali de failover PostgreSQL?
Să trecem peste pașii pentru o failover manuală PostgreSQL:
- Blocați serverul principal.
- Promovați serverul de așteptare rulând următoarea comandă pe serverul de așteptare:
./pg_ctl promote -D ../sb_data/ server promoting - Conectați-vă la serverul de așteptare promovat și introduceți un rând:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values (4,'Four');
Dacă inserarea funcționează bine, atunci modul de așteptare, anterior un server numai pentru citire, a fost promovat ca noul server principal.
Cum să automatizezi failoverul în PostgreSQL
Configurarea failoverului automat este ușoară.
Veți avea nevoie de EDB PostgreSQL failover manager (EFM). După descărcarea și instalarea EFM pe fiecare nod primar și standby, puteți crea un cluster EFM, care constă dintr-un nod primar, unul sau mai multe noduri Standby și un nod Witness opțional care confirmă afirmațiile în caz de eșec.
EFM monitorizează continuu sănătatea sistemului și trimite alerte prin e-mail pe baza evenimentelor din sistem. Când apare o defecțiune, trece automat la cel mai recent mod de așteptare și reconfigurează toate celelalte servere de așteptare pentru a recunoaște noul nod primar.
De asemenea, reconfigurează echilibratoarele de încărcare (cum ar fi pgPool) și previne apariția „creierului divizat” (atunci când două noduri consideră fiecare că sunt primare).
rezumat
Datorită cantităților mari de date, scalabilitatea și securitatea au devenit două dintre cele mai importante criterii în managementul bazelor de date, în special într-un mediu de tranzacții. Deși putem îmbunătăți scalabilitatea pe verticală adăugând mai multe resurse/hardware la nodurile existente, acest lucru nu este întotdeauna posibil, adesea din cauza costului sau limitărilor adăugării de hardware nou.
Prin urmare, este necesară scalabilitatea orizontală, ceea ce înseamnă adăugarea mai multor noduri la nodurile de rețea existente, mai degrabă decât îmbunătățirea funcționalității nodurilor existente. Aici intervine replicarea PostgreSQL.
În acest articol, am discutat despre tipurile de replicări PostgreSQL, beneficii, moduri de replicare, instalare și failover PostgreSQL între SMR și MMR. Acum să auzim de la tine.
Pe care o implementezi de obicei? Care caracteristică a bazei de date este cea mai importantă pentru tine și de ce? Ne-ar plăcea să vă citim gândurile! Distribuiți-le în secțiunea de comentarii de mai jos.