
Replikacja PostgreSQL: kompleksowy przewodnik
Opublikowany: 2022-08-11Jak powie każdy właściciel witryny, utrata danych i przestoje, nawet przy minimalnych dawkach, mogą być katastrofalne. Mogą trafić w nieprzygotowanych w dowolnym momencie, co prowadzi do zmniejszenia wydajności, dostępności i pewności produktu.
Aby chronić integralność witryny, konieczne jest stworzenie zabezpieczeń przed możliwością przestojów lub utraty danych.
Tu właśnie pojawia się replikacja danych.
Replikacja danych to zautomatyzowany proces tworzenia kopii zapasowej, w którym dane są wielokrotnie kopiowane z głównej bazy danych do innej, zdalnej lokalizacji w celu ich przechowania. Jest to integralna technologia dla każdej witryny lub aplikacji obsługującej serwer bazy danych. Możesz także wykorzystać zreplikowaną bazę danych do przetwarzania SQL tylko do odczytu, co pozwoli na uruchamianie większej liczby procesów w systemie.
Skonfigurowanie replikacji między dwiema bazami danych zapewnia odporność na błędy w przypadku nieoczekiwanych wpadek. Uważa się, że jest to najlepsza strategia osiągania wysokiej dostępności podczas katastrof.
W tym artykule zagłębimy się w różne strategie, które mogą być zaimplementowane przez programistów backendu w celu bezproblemowej replikacji PostgreSQL.
Co to jest replikacja PostgreSQL?
Replikacja PostgreSQL jest definiowana jako proces kopiowania danych z serwera bazy danych PostgreSQL na inny serwer. Źródłowy serwer bazy danych jest również nazywany serwerem „podstawowym”, natomiast serwer bazy danych odbierający skopiowane dane jest nazywany serwerem „repliki”.
Baza danych PostgreSQL jest zgodna z prostym modelem replikacji, w którym wszystkie zapisy trafiają do węzła podstawowego. Węzeł podstawowy może następnie zastosować te zmiany i rozesłać je do węzłów drugorzędnych.
Co to jest automatyczne przełączanie awaryjne?
Po skonfigurowaniu fizycznej replikacji strumieniowej w PostgreSQL, przełączenie awaryjne może nastąpić w przypadku awarii podstawowego serwera bazy danych. Przełączanie awaryjne służy do zdefiniowania procesu odzyskiwania, który może zająć trochę czasu, ponieważ nie zapewnia wbudowanych narzędzi do określania zakresu awarii serwera.
Nie musisz być zależny od PostgreSQL w celu przełączenia awaryjnego. Istnieją dedykowane narzędzia, które umożliwiają automatyczne przełączanie awaryjne i automatyczne przełączanie w stan gotowości, skracając przestoje bazy danych.
Konfigurując replikację awaryjną, gwarantujesz wysoką dostępność, zapewniając dostępność trybu gotowości w przypadku awarii serwera podstawowego.
Korzyści z używania replikacji PostgreSQL
Oto kilka kluczowych korzyści płynących z wykorzystania replikacji PostgreSQL:
- Migracja danych : Replikację PostgreSQL można wykorzystać do migracji danych poprzez zmianę sprzętu serwera bazy danych lub wdrożenie systemu.
- Odporność na awarie : W przypadku awarii serwera głównego serwer rezerwowy może działać jako serwer, ponieważ dane zawarte dla serwera głównego i serwera rezerwowego są takie same.
- Wydajność przetwarzania transakcyjnego online (OLTP) : możesz poprawić czas przetwarzania transakcji i czas zapytań w systemie OLTP, usuwając obciążenie zapytaniami raportowania. Czas przetwarzania transakcji to czas potrzebny na wykonanie danego zapytania przed zakończeniem transakcji.
- Równoległe testowanie systemu : aktualizując nowy system, należy upewnić się, że system dobrze radzi sobie z istniejącymi danymi, stąd konieczność testowania produkcyjnej kopii bazy danych przed wdrożeniem.
Jak działa replikacja PostgreSQL
Ogólnie rzecz biorąc, ludzie wierzą, że gdy bawisz się architekturą podstawową i drugorzędną, istnieje tylko jeden sposób na skonfigurowanie kopii zapasowych i replikacji, ale wdrożenia PostgreSQL opierają się na jednym z następujących trzech podejść:
- Replikacja na poziomie woluminu w celu replikacji w warstwie magazynu od węzła podstawowego do dodatkowego, a następnie utworzenie kopii zapasowej w magazynie obiektów blob/S3.
- Replikacja strumieniowa PostgreSQL w celu replikacji danych z węzła podstawowego do pomocniczego, a następnie utworzenie kopii zapasowej w magazynie obiektów blob/S3.
- Pobieranie przyrostowych kopii zapasowych z węzła podstawowego do S3 podczas rekonstrukcji nowego węzła pomocniczego z S3. Gdy węzeł drugorzędny znajduje się w pobliżu węzła podstawowego, możesz rozpocząć przesyłanie strumieniowe z węzła podstawowego.
Podejście 1: Streaming
Replikację strumieniową PostgreSQL, znaną również jako replikacja WAL, można bezproblemowo skonfigurować po zainstalowaniu PostgreSQL na wszystkich serwerach. To podejście do replikacji polega na przeniesieniu plików WAL z podstawowej do docelowej bazy danych.
Replikację strumieniową PostgreSQL można zaimplementować przy użyciu konfiguracji podstawowa-dodatkowa. Serwer podstawowy to główna instancja, która obsługuje podstawową bazę danych i wszystkie jej operacje. Serwer pomocniczy działa jako dodatkowa instancja i samodzielnie wykonuje wszystkie zmiany wprowadzone w podstawowej bazie danych, generując w procesie identyczną kopię. Podstawowym jest serwer do odczytu/zapisu, podczas gdy serwer pomocniczy jest tylko do odczytu.
W tym podejściu należy skonfigurować zarówno węzeł podstawowy, jak i węzeł rezerwowy. Poniższe sekcje z łatwością wyjaśnią kroki związane z ich konfiguracją.
Konfiguracja węzła głównego
Węzeł podstawowy można skonfigurować do replikacji strumieniowej, wykonując następujące czynności:
Krok 1: Zainicjuj bazę danych
Aby zainicjować bazę danych, możesz użyć polecenia initidb utility . Następnie możesz utworzyć nowego użytkownika z uprawnieniami do replikacji, korzystając z następującego polecenia:
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';Użytkownik będzie musiał podać hasło i nazwę użytkownika dla danego zapytania. Słowo kluczowe replikacja służy do nadania użytkownikowi wymaganych uprawnień. Przykładowe zapytanie wyglądałoby mniej więcej tak:
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'Krok 2: Skonfiguruj właściwości przesyłania strumieniowego
Następnie możesz skonfigurować właściwości przesyłania strumieniowego za pomocą pliku konfiguracyjnego PostgreSQL ( postgresql.conf ), który można zmodyfikować w następujący sposób:
wal_level = logical wal_log_hints = on max_wal_senders = 8 max_wal_size = 1GB hot_standby = onOto krótkie tło dotyczące parametrów użytych w poprzednim fragmencie:
-
wal_log_hints: Ten parametr jest wymagany dla możliwościpg_rewind, która jest przydatna, gdy serwer rezerwowy nie jest zsynchronizowany z serwerem podstawowym. -
wal_level: możesz użyć tego parametru, aby włączyć replikację strumieniową PostgreSQL z możliwymi wartościami, takimi jakminimal,replicalublogical. -
max_wal_size: może służyć do określenia rozmiaru plików WAL, które mogą być przechowywane w plikach dziennika. -
hot_standby: możesz wykorzystać ten parametr do połączenia do odczytu z dodatkowym, gdy jest ustawiony na ON. -
max_wal_senders: Możesz użyćmax_wal_senders, aby określić maksymalną liczbę jednoczesnych połączeń, które można nawiązać z serwerami rezerwowymi.
Krok 3: Utwórz nowy wpis
Po zmodyfikowaniu parametrów w pliku postgresql.conf nowy wpis replikacji w pliku pg_hba.conf może umożliwić serwerom nawiązanie połączenia między sobą w celu replikacji.
Zwykle możesz znaleźć ten plik w katalogu danych PostgreSQL. Możesz użyć następującego fragmentu kodu do tego samego:
host replication rep_user IPaddress md5 Po wykonaniu fragmentu kodu serwer główny umożliwia użytkownikowi o nazwie rep_user nawiązanie połączenia i działanie jako serwer rezerwowy przy użyciu określonego adresu IP do replikacji. Na przykład:
host replication rep_user 192.168.0.22/32 md5Konfiguracja węzła gotowości
Aby skonfigurować węzeł gotowości do replikacji strumieniowej, wykonaj następujące kroki:
Krok 1: Utwórz kopię zapasową węzła podstawowego
Aby skonfigurować węzeł rezerwowy, użyj narzędzia pg_basebackup do wygenerowania kopii zapasowej węzła podstawowego. Będzie to służyć jako punkt wyjścia dla węzła gotowości. Możesz użyć tego narzędzia z następującą składnią:
pg_basebackp -D -h -X stream -c fast -U rep_user -WParametry użyte w powyższej składni są następujące:
-
-h: Możesz użyć tego, aby wspomnieć o głównym hoście. -
-D: Ten parametr wskazuje katalog, nad którym aktualnie pracujesz. -
-C: Możesz użyć tego do ustawienia punktów kontrolnych. -
-X: Ten parametr może służyć do dołączenia niezbędnych plików dziennika transakcji. -
-W: Możesz użyć tego parametru, aby zapytać użytkownika o hasło przed połączeniem z bazą danych.
Krok 2: Skonfiguruj plik konfiguracyjny replikacji
Następnie musisz sprawdzić, czy plik konfiguracyjny replikacji istnieje. Jeśli tak się nie stanie, możesz wygenerować plik konfiguracyjny replikacji jako recovery.conf.
Powinieneś utworzyć ten plik w katalogu danych instalacji PostgreSQL. Możesz go wygenerować automatycznie, używając opcji -R w narzędziu pg_basebackup .
Plik recovery.conf powinien zawierać następujące polecenia:
standby_mode = 'włączony'
primary_conninfo = 'host=<host_główny> port=<port_postgres> user=<użytkownik_replikacji> password=<hasło> nazwa_aplikacji=”nazwa_hosta”'
recovery_target_timeline = 'najnowszy'
Parametry użyte w wyżej wymienionych poleceniach są następujące:
-
primary_conninfo: możesz użyć tego do nawiązania połączenia między serwerami podstawowymi i pomocniczymi, wykorzystując ciąg połączenia. -
standby_mode: Ten parametr może spowodować, że serwer podstawowy będzie uruchamiany w trybie gotowości po włączeniu. -
recovery_target_timeline: Możesz użyć tego do ustawienia czasu odzyskiwania.
Aby skonfigurować połączenie, musisz podać nazwę użytkownika, adres IP i hasło jako wartości parametru primary_conninfo. Na przykład:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Krok 3: Uruchom ponownie serwer pomocniczy
Na koniec możesz ponownie uruchomić serwer pomocniczy, aby zakończyć proces konfiguracji.
Jednak replikacja strumieniowa wiąże się z kilkoma wyzwaniami, takimi jak:
- Różne klienty PostgreSQL (napisane w różnych językach programowania) komunikują się z jednym punktem końcowym. Gdy węzeł podstawowy ulegnie awarii, klienci ci będą nadal ponawiać tę samą nazwę DNS lub IP. Dzięki temu przełączanie awaryjne jest widoczne dla aplikacji.
- Replikacja PostgreSQL nie ma wbudowanego przełączania awaryjnego i monitorowania. Gdy węzeł podstawowy ulegnie awarii, musisz awansować drugorzędny na nowy główny. Ta promocja musi być wykonywana w sposób, w którym klienci zapisują tylko w jednym węźle podstawowym i nie zauważają niespójności danych.
- PostgreSQL replikuje cały swój stan. Kiedy trzeba opracować nowy węzeł drugorzędny, drugorzędny musi podsumować całą historię zmian stanu z węzła podstawowego, co wymaga dużych zasobów i sprawia, że eliminacja węzłów w głowie i tworzenie nowych jest kosztowna.
Podejście 2: Replikowane urządzenie blokowe
Podejście zreplikowanego urządzenia blokowego zależy od dublowania dysku (znanego również jako replikacja woluminu). W tym podejściu zmiany są zapisywane na trwałym woluminie, który jest synchronicznie dublowany na innym woluminie.
Dodatkową korzyścią tego podejścia jest jego kompatybilność i trwałość danych w środowiskach chmurowych ze wszystkimi relacyjnymi bazami danych, w tym między innymi PostgreSQL, MySQL i SQL Server.
Jednak podejście dublowania dysku do replikacji PostgreSQL wymaga replikacji zarówno danych dziennika, jak i tabeli WAL. Ponieważ każdy zapis do bazy danych musi teraz przechodzić przez sieć synchronicznie, nie możesz sobie pozwolić na utratę jednego bajtu, ponieważ może to spowodować uszkodzenie bazy danych.
To podejście jest zwykle wykorzystywane przy użyciu Azure PostgreSQL i Amazon RDS.
Podejście 3: WAL
WAL składa się z plików segmentowych (domyślnie 16 MB). Każdy segment ma co najmniej jeden rekord. Rekord sekwencji dziennika (LSN) jest wskaźnikiem do rekordu w WAL, informującym o pozycji/lokalizacji, w której rekord został zapisany w pliku dziennika.
Serwer rezerwowy wykorzystuje segmenty WAL — znane również jako XLOGS w terminologii PostgreSQL — do ciągłego replikowania zmian z serwera podstawowego. Za pomocą rejestrowania zapisu z wyprzedzeniem można zapewnić trwałość i niepodzielność w systemie DBMS, serializując fragmenty danych tablicy bajtów (każdy z unikatowym LSN) do stabilnej pamięci masowej, zanim zostaną zastosowane do bazy danych.
Zastosowanie mutacji do bazy danych może prowadzić do różnych operacji na systemie plików. Istotnym pytaniem, które się pojawia, jest to, w jaki sposób baza danych może zapewnić niepodzielność w przypadku awarii serwera z powodu przerwy w zasilaniu, gdy była w trakcie aktualizacji systemu plików. Podczas uruchamiania bazy danych rozpoczyna się proces uruchamiania lub odtwarzania, który może odczytać dostępne segmenty WAL i porównać je z numerem LSN zapisanym na każdej stronie danych (każda strona danych jest oznaczona numerem LSN najnowszego rekordu WAL, który ma wpływ na stronę).
Replikacja oparta na wysyłce dziennika (poziom bloku)
Replikacja strumieniowa usprawnia proces wysyłania dziennika. W przeciwieństwie do oczekiwania na przełącznik WAL, rekordy są wysyłane w miarę ich tworzenia, co zmniejsza opóźnienie replikacji.
Replikacja strumieniowa ma również przewagę nad przesyłaniem dzienników, ponieważ serwer rezerwowy łączy się z serwerem głównym przez sieć, wykorzystując protokół replikacji. Serwer główny może następnie wysyłać rekordy WAL bezpośrednio przez to połączenie, bez konieczności polegania na skryptach dostarczonych przez użytkownika końcowego.
Replikacja oparta na wysyłce dziennika (poziom pliku)
Wysyłanie dziennika jest definiowane jako kopiowanie plików dziennika na inny serwer PostgreSQL w celu wygenerowania kolejnego serwera rezerwowego poprzez odtwarzanie plików WAL. Ten serwer jest skonfigurowany do pracy w trybie odzyskiwania, a jego jedynym celem jest zastosowanie wszelkich nowych plików WAL, gdy się pojawią.
Ten serwer pomocniczy staje się następnie ciepłą kopią zapasową podstawowego serwera PostgreSQL. Można go również skonfigurować jako replikę do odczytu, w której może oferować zapytania tylko do odczytu, określane również jako gorąca rezerwa.
Ciągła archiwizacja WAL
Powielanie plików WAL podczas ich tworzenia w dowolnej lokalizacji innej niż podkatalog pg_wal w celu ich archiwizacji jest znane jako archiwizacja WAL. PostgreSQL wywoła skrypt podany przez użytkownika do archiwizacji za każdym razem, gdy zostanie utworzony plik WAL.
Skrypt może wykorzystać polecenie scp do zduplikowania pliku w jednej lub kilku lokalizacjach, takich jak montowanie NFS. Po zarchiwizowaniu pliki segmentowe WAL można wykorzystać do odzyskania bazy danych w dowolnym momencie.
Inne konfiguracje oparte na dziennikach obejmują:
- Replikacja synchroniczna : zanim każda transakcja replikacji synchronicznej zostanie zatwierdzona, serwer główny czeka, aż stan wstrzymania potwierdzi, że otrzymał dane. Zaletą tej konfiguracji jest brak konfliktów spowodowanych równoległymi procesami zapisu.
- Synchroniczna replikacja z wieloma wzorcami : tutaj każdy serwer może akceptować żądania zapisu, a zmodyfikowane dane są przesyłane z oryginalnego serwera do każdego innego serwera przed zatwierdzeniem każdej transakcji. Wykorzystuje protokół 2PC i przestrzega zasady „wszystko albo nic”.
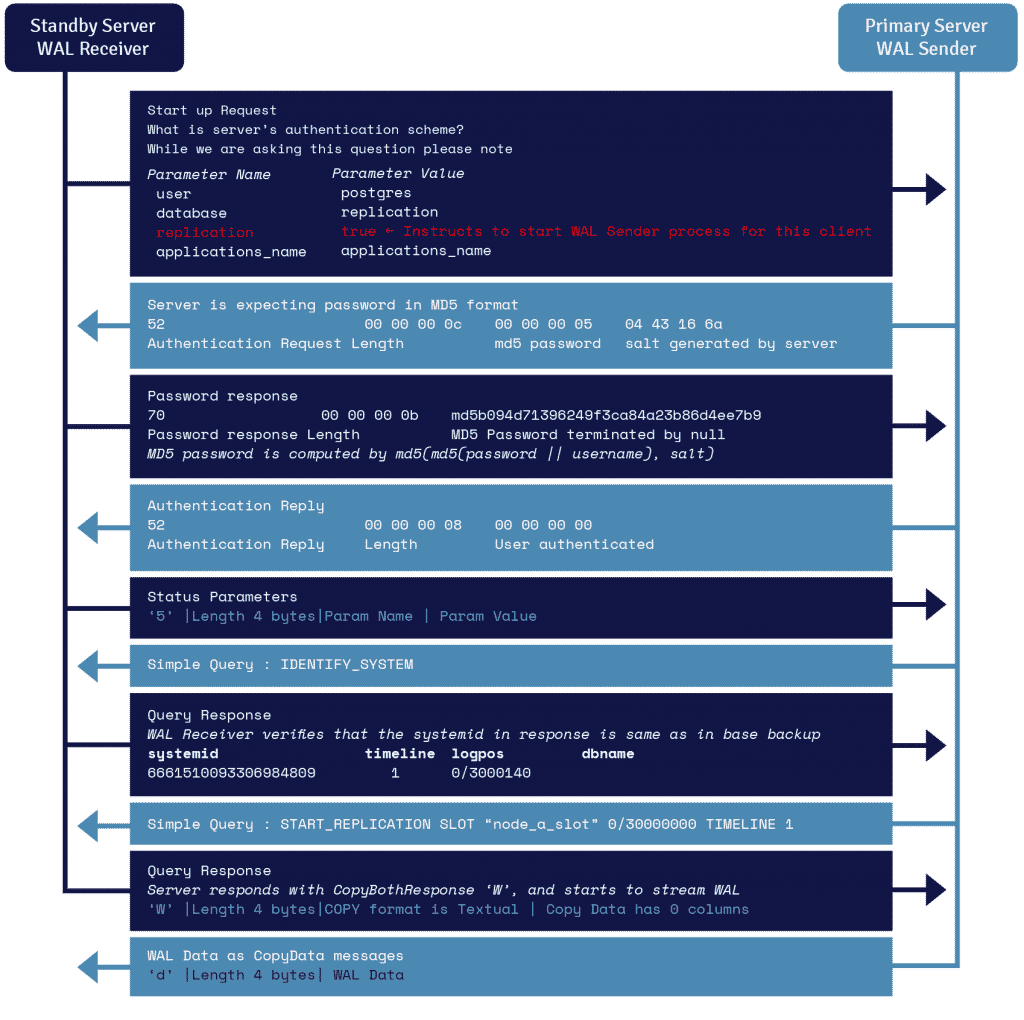
Szczegóły protokołu przesyłania strumieniowego WAL
Proces znany jako odbiornik WAL, działający na serwerze rezerwowym, wykorzystuje szczegóły połączenia podane w parametrze primary_conninfo recovery.conf i łączy się z serwerem podstawowym, wykorzystując połączenie TCP/IP.
Aby rozpocząć replikację strumieniową, frontend może wysłać parametr replikacji w komunikacie startowym. Wartość logiczna true, yes, 1 lub ON informuje backend, że musi przejść w tryb walsender replikacji fizycznej.
Nadawca WAL to kolejny proces działający na serwerze podstawowym, który odpowiada za wysyłanie rekordów WAL do serwera rezerwowego w miarę ich generowania. Odbiornik WAL zapisuje rekordy WAL w WAL tak, jakby zostały utworzone w wyniku aktywności klientów podłączonych lokalnie.

Gdy rekordy WAL dotrą do plików segmentu WAL, serwer rezerwowy stale odtwarza WAL, dzięki czemu podstawowy i rezerwowy są aktualne.
Elementy replikacji PostgreSQL
W tej sekcji uzyskasz głębsze zrozumienie powszechnie używanych modeli (replikacja jedno- i wielo-wzorcowa), typów (replikacja fizyczna i logiczna) oraz trybów (synchroniczna i asynchroniczna) replikacji PostgreSQL.
Modele replikacji baz danych PostgreSQL
Skalowalność oznacza dodanie większej ilości zasobów/sprzętu do istniejących węzłów w celu zwiększenia zdolności bazy danych do przechowywania i przetwarzania większej ilości danych, co można osiągnąć poziomo i pionowo. Replikacja PostgreSQL jest przykładem skalowalności poziomej, która jest znacznie trudniejsza do zaimplementowania niż skalowalność pionowa. Skalowalność poziomą możemy osiągnąć głównie poprzez replikację jednorzędową (SMR) i replikację wielowzorcową (MMR).
Replikacja z jednym wzorcem umożliwia modyfikowanie danych tylko w jednym węźle, a modyfikacje te są replikowane do jednego lub większej liczby węzłów. Zreplikowane tabele w bazie danych replik nie mogą akceptować żadnych zmian, z wyjątkiem tych z serwera podstawowego. Nawet jeśli tak, zmiany nie są replikowane z powrotem na serwer podstawowy.
W większości przypadków SMR jest wystarczający dla aplikacji, ponieważ jest mniej skomplikowany w konfiguracji i zarządzaniu, a także nie ma szans na konflikty. Replikacja z jednym wzorcem jest również jednokierunkowa, ponieważ dane replikacji przepływają głównie w jednym kierunku, z bazy podstawowej do bazy danych repliki.
W niektórych przypadkach samo SMR może nie wystarczyć i może być konieczne wdrożenie MMR. MMR pozwala więcej niż jednemu węzłowi działać jako węzeł podstawowy. Zmiany w wierszach tabeli w więcej niż jednej wyznaczonej podstawowej bazie danych są replikowane do odpowiadających im tabel w każdej innej podstawowej bazie danych. W tym modelu często stosuje się schematy rozwiązywania konfliktów, aby uniknąć problemów, takich jak zduplikowane klucze podstawowe.
Korzystanie z MMR ma kilka zalet, a mianowicie:
- W przypadku awarii hosta inne hosty mogą nadal świadczyć usługi aktualizacji i wstawiania.
- Węzły podstawowe są rozmieszczone w kilku różnych lokalizacjach, więc prawdopodobieństwo awarii wszystkich węzłów głównych jest bardzo małe.
- Możliwość wykorzystania sieci rozległej (WAN) podstawowych baz danych, która może znajdować się geograficznie blisko grup klientów, zachowując jednocześnie spójność danych w całej sieci.
Jednak wadą wdrożenia MMR jest złożoność i trudność w rozwiązywaniu konfliktów.
Kilka gałęzi i aplikacji udostępnia rozwiązania MMR, ponieważ PostgreSQL nie obsługuje ich natywnie. Te rozwiązania mogą być open-source, bezpłatne lub płatne. Jednym z takich rozszerzeń jest replikacja dwukierunkowa (BDR), która jest asynchroniczna i opiera się na logicznej funkcji dekodowania PostgreSQL.
Ponieważ aplikacja BDR odtwarza transakcje na innych węzłach, operacja odtwarzania może zakończyć się niepowodzeniem, jeśli wystąpi konflikt między transakcją zastosowaną a transakcją zatwierdzoną w węźle odbierającym.
Rodzaje replikacji PostgreSQL
Istnieją dwa typy replikacji PostgreSQL: replikacja logiczna i fizyczna.
Prosta logiczna operacja „initdb” wykonałaby fizyczną operację tworzenia podstawowego katalogu dla klastra. Podobnie prosta operacja logiczna „CREATE DATABASE” wykonałaby fizyczną operację tworzenia podkatalogu w katalogu podstawowym.
Replikacja fizyczna zwykle dotyczy plików i katalogów. Nie wie, co reprezentują te pliki i katalogi. Te metody są używane do utrzymywania pełnej kopii wszystkich danych pojedynczego klastra, zwykle na innym komputerze, i są wykonywane na poziomie systemu plików lub dysku i używają dokładnych adresów blokowych.
Replikacja logiczna to sposób odtwarzania jednostek danych i ich modyfikacji na podstawie ich tożsamości replikacji (zwykle klucza podstawowego). W przeciwieństwie do replikacji fizycznej, zajmuje się ona bazami danych, tabelami i operacjami DML i jest wykonywana na poziomie klastra bazy danych. Wykorzystuje model publikowania i subskrybowania , w którym jeden lub więcej subskrybentów subskrybuje jedną lub więcej publikacji w węźle wydawcy .
Proces replikacji rozpoczyna się od wykonania migawki danych w bazie danych wydawcy, a następnie skopiowania jej do subskrybenta. Subskrybenci pobierają dane z subskrybowanych publikacji i mogą je później ponownie opublikować, aby umożliwić replikację kaskadową lub bardziej złożone konfiguracje. Subskrybent stosuje dane w tej samej kolejności co wydawca, aby zagwarantować spójność transakcyjną publikacji w ramach jednej subskrypcji, zwanej również replikacją transakcyjną.
Typowe przypadki użycia replikacji logicznej to:
- Wysyłanie przyrostowych zmian w pojedynczej bazie danych (lub podzbiorze bazy danych) do subskrybentów w miarę ich występowania.
- Udostępnianie podzbioru bazy danych między wieloma bazami danych.
- Uruchamianie wyzwalania poszczególnych zmian, gdy dotrą one do subskrybenta.
- Konsolidacja wielu baz danych w jedną.
- Zapewnienie dostępu do zreplikowanych danych różnym grupom użytkowników.
Baza subskrybentów zachowuje się tak samo jak każda inna instancja PostgreSQL i może być używana jako wydawca dla innych baz danych poprzez zdefiniowanie jej publikacji.
Gdy subskrybent jest traktowany jako tylko do odczytu przez aplikację, nie będzie żadnych konfliktów z pojedynczej subskrypcji. Z drugiej strony, jeśli istnieją inne zapisy wykonane przez aplikację lub przez innych subskrybentów tego samego zestawu tabel, mogą wystąpić konflikty.
PostgreSQL obsługuje oba mechanizmy jednocześnie. Replikacja logiczna umożliwia precyzyjną kontrolę zarówno nad replikacją danych, jak i zabezpieczeniami.
Tryby replikacji
Istnieją głównie dwa tryby replikacji PostgreSQL: synchroniczny i asynchroniczny. Replikacja synchroniczna umożliwia jednoczesne zapisywanie danych zarówno na serwerze podstawowym, jak i pomocniczym, podczas gdy replikacja asynchroniczna zapewnia, że dane są najpierw zapisywane na hoście, a następnie kopiowane na serwer pomocniczy.
W replikacji w trybie synchronicznym transakcje w podstawowej bazie danych są uznawane za zakończone tylko wtedy, gdy te zmiany zostały zreplikowane do wszystkich replik. Wszystkie serwery replik muszą być dostępne przez cały czas, aby transakcje zostały zakończone na serwerze podstawowym. Synchroniczny tryb replikacji jest używany w zaawansowanych środowiskach transakcyjnych z natychmiastowymi wymaganiami dotyczącymi przełączania awaryjnego.
W trybie asynchronicznym transakcje na serwerze głównym można uznać za zakończone, gdy zmiany zostały wprowadzone tylko na serwerze głównym. Te zmiany są następnie replikowane w replikach w późniejszym czasie. Serwery replik mogą pozostawać niezsynchronizowane przez pewien czas, zwany opóźnieniem replikacji. W przypadku awarii może nastąpić utrata danych, ale obciążenie zapewniane przez replikację asynchroniczną jest niewielkie, więc w większości przypadków jest to dopuszczalne (nie obciąża hosta). Przełączanie awaryjne z podstawowej bazy danych do pomocniczej bazy danych trwa dłużej niż replikacja synchroniczna.
Jak skonfigurować replikację PostgreSQL
W tej sekcji zademonstrujemy, jak skonfigurować proces replikacji PostgreSQL w systemie operacyjnym Linux. W tym przypadku użyjemy Ubuntu 18.04 LTS i PostgreSQL 10.
Zagłębmy się!
Instalacja
Zaczniesz od zainstalowania PostgreSQL w systemie Linux, wykonując następujące kroki:
- Po pierwsze, musisz zaimportować klucz podpisywania PostgreSQL, wpisując poniższe polecenie w terminalu:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Następnie dodaj repozytorium PostgreSQL, wpisując w terminalu poniższe polecenie:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Zaktualizuj indeks repozytorium, wpisując w terminalu następujące polecenie:
sudo apt-get update - Zainstaluj pakiet PostgreSQL za pomocą polecenia apt:
sudo apt-get install -y postgresql-10 - Na koniec ustaw hasło dla użytkownika PostgreSQL za pomocą następującego polecenia:
sudo passwd postgres
Instalacja PostgreSQL jest obowiązkowa zarówno dla serwera podstawowego, jak i pomocniczego przed rozpoczęciem procesu replikacji PostgreSQL.
Po skonfigurowaniu PostgreSQL dla obu serwerów możesz przejść do konfiguracji replikacji serwera podstawowego i pomocniczego.
Konfigurowanie replikacji na serwerze głównym
Wykonaj te czynności po zainstalowaniu PostgreSQL na serwerach podstawowych i pomocniczych.
- Najpierw zaloguj się do bazy danych PostgreSQL za pomocą następującego polecenia:
su - postgres - Utwórz użytkownika replikacji za pomocą następującego polecenia:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Edytuj pg_hba.cnf za pomocą dowolnej aplikacji nano w Ubuntu i dodaj następującą konfigurację: polecenie edycji pliku
nano /etc/postgresql/10/main/pg_hba.confAby skonfigurować plik, użyj następującego polecenia:
host replication replication MasterIP/24 md5 - Otwórz i edytuj postgresql.conf i umieść następującą konfigurację na serwerze podstawowym:
nano /etc/postgresql/10/main/postgresql.confUżyj następujących ustawień konfiguracyjnych:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - Na koniec zrestartuj PostgreSQL na głównym serwerze głównym:
systemctl restart postgresqlKonfiguracja na serwerze podstawowym została zakończona.
Konfigurowanie replikacji na serwerze pomocniczym
Wykonaj następujące kroki, aby skonfigurować replikację na serwerze pomocniczym:
- Zaloguj się do PostgreSQL RDMS za pomocą poniższego polecenia:
su - postgres - Zatrzymaj działanie usługi PostgreSQL, abyśmy mogli nad nią pracować za pomocą poniższego polecenia:
systemctl stop postgresql - Edytuj plik pg_hba.conf za pomocą tego polecenia i dodaj następującą konfigurację:
Edytuj polecenienano /etc/postgresql/10/main/pg_hba.confKonfiguracja
host replication replication MasterIP/24 md5 - Otwórz i edytuj postgresql.conf na serwerze pomocniczym i umieść następującą konfigurację lub usuń komentarz, jeśli jest skomentowany: Edytuj polecenie
Konfiguracjanano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP to adres serwera pomocniczego
- Uzyskaj dostęp do katalogu danych PostgreSQL na serwerze pomocniczym i usuń wszystko:
cd /var/lib/postgresql/10/mainrm -rfv * - Skopiuj pliki katalogu danych serwera głównego PostgreSQL do katalogu danych serwera pomocniczego PostgreSQL i wpisz to polecenie na serwerze pomocniczym:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - Wprowadź hasło serwera głównego PostgreSQL i naciśnij enter. Następnie dodaj następujące polecenie dla konfiguracji odzyskiwania: Edytuj polecenie
nano /var/lib/postgresql/10/main/recovery.confKonfiguracja
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Tutaj TWOJE_HASŁO jest hasłem dla użytkownika replikacji na głównym serwerze utworzonym przez PostgreSQL
- Po ustawieniu hasła będziesz musiał ponownie uruchomić dodatkową bazę danych PostgreSQL, ponieważ została zatrzymana:
systemctl start postgresqlTestowanie konfiguracji
Teraz, gdy wykonaliśmy wszystkie kroki, przetestujmy proces replikacji i przyjrzyjmy się bazie danych serwera pomocniczego. W tym celu tworzymy tabelę na serwerze głównym i obserwujemy, czy to samo znajduje odzwierciedlenie na serwerze pomocniczym.
Weźmy się za to.
- Ponieważ tworzymy tabelę na serwerze głównym, musisz zalogować się do serwera głównego:
su - postgres psql - Teraz tworzymy prostą tabelę o nazwie „testtable” i wstawiamy dane do tabeli, uruchamiając w terminalu następujące zapytania PostgreSQL:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Obserwuj bazę danych PostgreSQL serwera pomocniczego, logując się do serwera pomocniczego:
su - postgres psql - Teraz sprawdzamy, czy istnieje tabela „testtable” i możemy zwrócić dane, uruchamiając w terminalu następujące zapytania PostgreSQL. To polecenie zasadniczo wyświetla całą tabelę.
select * from testtable;
To jest wynik tabeli testowej:
| websites | ------------------- | section.com | | google.com | | github.com | --------------------Powinieneś być w stanie obserwować te same dane, co na serwerze głównym.
Jeśli widzisz powyższe, oznacza to, że pomyślnie przeprowadziłeś proces replikacji!
Jakie są kroki ręcznego przełączania awaryjnego PostgreSQL?
Przyjrzyjmy się krokom ręcznego przełączania awaryjnego PostgreSQL:
- Awaria serwera podstawowego.
- Podwyższ poziom serwera rezerwowego, uruchamiając następujące polecenie na serwerze rezerwowym:
./pg_ctl promote -D ../sb_data/ server promoting - Połącz się z promowanym serwerem rezerwowym i wstaw wiersz:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values (4,'Four');
Jeśli wstawianie działa prawidłowo, oznacza to, że rezerwowy, poprzednio serwer tylko do odczytu, został promowany jako nowy serwer podstawowy.
Jak zautomatyzować przełączanie awaryjne w PostgreSQL
Konfiguracja automatycznego przełączania awaryjnego jest łatwa.
Będziesz potrzebował menedżera pracy awaryjnej EDB PostgreSQL (EFM). Po pobraniu i zainstalowaniu EFM na każdym węźle podstawowym i rezerwowym można utworzyć klaster EFM, który składa się z węzła podstawowego, co najmniej jednego węzła w trybie gotowości oraz opcjonalnego węzła świadka, który potwierdza asercje w przypadku niepowodzenia.
EFM stale monitoruje stan systemu i wysyła alerty e-mail w oparciu o zdarzenia systemowe. Gdy wystąpi awaria, automatycznie przełącza się na najbardziej aktualny stan gotowości i ponownie konfiguruje wszystkie inne serwery gotowości, aby rozpoznać nowy węzeł podstawowy.
Rekonfiguruje również systemy równoważenia obciążenia (takie jak pgPool) i zapobiega występowaniu „podziału mózgu” (gdy dwa węzły myślą, że są podstawowe).
Streszczenie
Ze względu na duże ilości danych skalowalność i bezpieczeństwo stały się dwoma najważniejszymi kryteriami w zarządzaniu bazami danych, zwłaszcza w środowisku transakcyjnym. Chociaż możemy poprawić skalowalność w pionie, dodając więcej zasobów/sprzętu do istniejących węzłów, nie zawsze jest to możliwe, często ze względu na koszty lub ograniczenia związane z dodawaniem nowego sprzętu.
Dlatego wymagana jest skalowalność pozioma, co oznacza dodawanie większej liczby węzłów do istniejących węzłów sieci, a nie zwiększanie funkcjonalności istniejących węzłów. W tym miejscu pojawia się replikacja PostgreSQL.
W tym artykule omówiliśmy typy replikacji PostgreSQL, korzyści, tryby replikacji, instalację i przełączanie awaryjne PostgreSQL między SMR i MMR. Teraz posłuchajmy od Ciebie.
Którą zazwyczaj wdrażasz? Która funkcja bazy danych jest dla Ciebie najważniejsza i dlaczego? Chętnie przeczytamy Twoje myśli! Udostępnij je w sekcji komentarzy poniżej.