
PostgreSQL 복제: 종합 가이드
게시 됨: 2022-08-11모든 사이트 소유자가 말하듯이 데이터 손실 및 가동 중지 시간은 최소한의 용량으로도 치명적일 수 있습니다. 언제든지 준비되지 않은 공격을 받을 수 있으므로 생산성, 접근성 및 제품 신뢰도가 저하됩니다.
사이트의 무결성을 보호하려면 다운타임이나 데이터 손실 가능성에 대한 보호 장치를 구축하는 것이 중요합니다.
데이터 복제가 필요한 곳입니다.
데이터 복제는 데이터를 안전하게 보관하기 위해 기본 데이터베이스에서 다른 원격 위치로 반복적으로 복사하는 자동화된 백업 프로세스입니다. 데이터베이스 서버를 실행하는 모든 사이트 또는 앱에 필수적인 기술입니다. 또한 복제된 데이터베이스를 활용하여 읽기 전용 SQL을 처리하여 시스템 내에서 더 많은 프로세스를 실행할 수 있습니다.
두 데이터베이스 간의 복제를 설정하면 예기치 않은 사고에 대한 내결함성이 제공됩니다. 재해 발생 시 고가용성을 확보하기 위한 최상의 전략으로 간주됩니다.
이 기사에서는 원활한 PostgreSQL 복제를 위해 백엔드 개발자가 구현할 수 있는 다양한 전략에 대해 알아보겠습니다.
PostgreSQL 복제란 무엇입니까?
PostgreSQL 복제는 PostgreSQL 데이터베이스 서버에서 다른 서버로 데이터를 복사하는 프로세스로 정의됩니다. 원본 데이터베이스 서버는 "기본" 서버라고도 하는 반면 복사된 데이터를 수신하는 데이터베이스 서버는 "복제본" 서버로 알려져 있습니다.
PostgreSQL 데이터베이스는 모든 쓰기가 기본 노드로 이동하는 간단한 복제 모델을 따릅니다. 그런 다음 기본 노드는 이러한 변경 사항을 적용하고 보조 노드에 브로드캐스트할 수 있습니다.
자동 장애 조치란 무엇입니까?
PostgreSQL에서 물리적 스트리밍 복제가 구성되면 데이터베이스의 기본 서버에 장애가 발생하면 장애 조치가 발생할 수 있습니다. 장애 조치는 복구 프로세스를 정의하는 데 사용되며 서버 오류 범위를 지정하는 기본 제공 도구를 제공하지 않기 때문에 시간이 걸릴 수 있습니다.
장애 조치를 위해 PostgreSQL에 의존할 필요가 없습니다. 자동 장애 조치(failover) 및 대기 모드로의 자동 전환을 허용하는 전용 도구가 있어 데이터베이스 다운타임을 줄입니다.
장애 조치 복제를 설정하면 기본 서버가 무너지는 경우 대기를 사용할 수 있도록 하여 고가용성을 거의 보장할 수 있습니다.
PostgreSQL 복제 사용의 이점
다음은 PostgreSQL 복제를 활용하는 몇 가지 주요 이점입니다.
- 데이터 마이그레이션 : 데이터베이스 서버 하드웨어 변경 또는 시스템 배포를 통해 데이터 마이그레이션에 PostgreSQL 복제를 활용할 수 있습니다.
- 내결함성 : 기본 서버에 장애가 발생하면 기본 서버와 대기 서버에 포함된 데이터가 동일하므로 대기 서버가 서버 역할을 할 수 있습니다.
- OLTP(온라인 트랜잭션 처리) 성능 : 보고 쿼리 로드를 제거하여 OLTP 시스템의 트랜잭션 처리 시간 및 쿼리 시간을 향상시킬 수 있습니다. 트랜잭션 처리 시간은 트랜잭션이 완료되기 전에 주어진 쿼리가 실행되는 데 걸리는 시간입니다.
- 병렬 시스템 테스트 : 새 시스템을 업그레이드하는 동안 시스템이 기존 데이터와 잘 맞는지 확인해야 하므로 배포 전에 프로덕션 데이터베이스 복사본으로 테스트해야 합니다.
PostgreSQL 복제 작동 방식
일반적으로 사람들은 기본 및 보조 아키텍처를 다룰 때 백업 및 복제를 설정하는 방법이 한 가지뿐이라고 생각하지만 PostgreSQL 배포는 다음 세 가지 접근 방식 중 하나를 따릅니다.
- 스토리지 계층에서 기본 노드에서 보조 노드로 복제하는 볼륨 수준 복제 후 Blob/S3 스토리지에 백업합니다.
- 기본 노드에서 보조 노드로 데이터를 복제한 후 Blob/S3 스토리지에 백업하는 PostgreSQL 스트리밍 복제 .
- S3에서 새 보조 노드를 재구성하는 동안 기본 노드에서 S3으로 증분 백업 을 수행합니다. 보조 노드가 기본 노드 근처에 있으면 기본 노드에서 스트리밍을 시작할 수 있습니다.
접근 방식 1: 스트리밍
WAL 복제라고도 하는 PostgreSQL 스트리밍 복제는 모든 서버에 PostgreSQL을 설치한 후 원활하게 설정할 수 있습니다. 이 복제 접근 방식은 WAL 파일을 기본 데이터베이스에서 대상 데이터베이스로 이동하는 것을 기반으로 합니다.
기본-보조 구성을 사용하여 PostgreSQL 스트리밍 복제를 구현할 수 있습니다. 기본 서버는 기본 데이터베이스와 모든 작업을 처리하는 기본 인스턴스입니다. 보조 서버는 보조 인스턴스 역할을 하며 기본 데이터베이스에 대한 모든 변경 사항을 자체적으로 실행하여 프로세스에서 동일한 복사본을 생성합니다. 기본 서버는 읽기/쓰기 서버인 반면 보조 서버는 읽기 전용입니다.
이 접근 방식의 경우 기본 노드와 대기 노드를 모두 구성해야 합니다. 다음 섹션에서는 쉽게 구성하는 데 관련된 단계를 설명합니다.
기본 노드 구성
다음 단계를 수행하여 스트리밍 복제를 위한 기본 노드를 구성할 수 있습니다.
1단계: 데이터베이스 초기화
데이터베이스를 초기화하기 위해 initidb utility 명령을 활용할 수 있습니다. 다음으로 다음 명령을 사용하여 복제 권한이 있는 새 사용자를 생성할 수 있습니다.
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';사용자는 주어진 쿼리에 대한 암호와 사용자 이름을 제공해야 합니다. 복제 키워드는 사용자에게 필요한 권한을 부여하는 데 사용됩니다. 예제 쿼리는 다음과 같습니다.
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'2단계: 스트리밍 속성 구성
다음으로 다음과 같이 수정할 수 있는 PostgreSQL 구성 파일( postgresql.conf )을 사용하여 스트리밍 속성을 구성할 수 있습니다.
wal_level = logical wal_log_hints = on max_wal_senders = 8 max_wal_size = 1GB hot_standby = on다음은 이전 스니펫에서 사용된 매개변수에 대한 약간의 배경입니다.
-
wal_log_hints: 이 매개변수는 대기 서버가 기본 서버와 동기화되지 않을 때 유용한pg_rewind기능에 필요합니다. -
wal_level: 이 매개변수를 사용하여minimal,replica또는logical을 포함한 가능한 값으로 PostgreSQL 스트리밍 복제를 활성화할 수 있습니다. -
max_wal_size: 로그 파일에 보유할 수 있는 WAL 파일의 크기를 지정하는 데 사용할 수 있습니다. -
hot_standby: ON으로 설정된 경우 보조 장치와의 읽기 연결에 이 매개변수를 활용할 수 있습니다. -
max_wal_senders:max_wal_senders를 사용하여 대기 서버와 설정할 수 있는 최대 동시 연결 수를 지정할 수 있습니다.
3단계: 새 항목 만들기
postgresql.conf 파일의 매개변수를 수정한 후 pg_hba.conf 파일의 새 복제 항목을 통해 서버가 복제를 위해 서로 연결을 설정할 수 있습니다.
일반적으로 이 파일은 PostgreSQL의 데이터 디렉토리에서 찾을 수 있습니다. 동일한 경우 다음 코드 스니펫을 사용할 수 있습니다.
host replication rep_user IPaddress md5 코드 조각이 실행되면 주 서버는 rep_user 라는 사용자가 복제를 위해 지정된 IP를 사용하여 연결하고 대기 서버 역할을 할 수 있도록 합니다. 예를 들어:
host replication rep_user 192.168.0.22/32 md5대기 노드 구성
스트리밍 복제를 위해 대기 노드를 구성하려면 다음 단계를 따르십시오.
1단계: 기본 노드 백업
대기 노드를 구성하려면 pg_basebackup 유틸리티를 활용하여 기본 노드의 백업을 생성합니다. 이것은 대기 노드의 시작점 역할을 합니다. 다음 구문과 함께 이 유틸리티를 사용할 수 있습니다.
pg_basebackp -D -h -X stream -c fast -U rep_user -W위에서 언급한 구문에 사용된 매개변수는 다음과 같습니다.
-
-h: 이것을 사용하여 기본 호스트를 언급할 수 있습니다. -
-D: 이 매개변수는 현재 작업 중인 디렉토리를 나타냅니다. -
-C: 체크포인트를 설정하는데 사용할 수 있습니다. -
-X: 이 매개변수는 필요한 트랜잭션 로그 파일을 포함하는 데 사용할 수 있습니다. -
-W: 이 매개변수를 사용하여 데이터베이스에 연결하기 전에 사용자에게 암호를 묻도록 할 수 있습니다.
2단계: 복제 구성 파일 설정
다음으로 복제 설정 파일이 존재하는지 확인해야 합니다. 그렇지 않은 경우 복제 구성 파일을 recovery.conf로 생성할 수 있습니다.
PostgreSQL 설치의 데이터 디렉토리에 이 파일을 생성해야 합니다. pg_basebackup 유틸리티 내에서 -R 옵션을 사용하여 자동으로 생성할 수 있습니다.
Recovery.conf 파일에는 다음 명령이 포함되어야 합니다.
대기 모드 = '켜기'
primary_conninfo = '호스트=<마스터_호스트> 포트=<postgres_port> 사용자=<복제_사용자> 암호=<비밀번호> application_name=”호스트_이름”'
Recovery_target_timeline = '최신'
앞서 언급한 명령어에 사용되는 매개변수는 다음과 같습니다.
-
primary_conninfo: 연결 문자열을 활용하여 기본 서버와 보조 서버를 연결하는 데 사용할 수 있습니다. -
standby_mode: 이 매개변수는 스위치가 켜졌을 때 기본 서버가 대기로 시작되도록 할 수 있습니다. -
recovery_target_timeline: 복구 시간을 설정하는 데 사용할 수 있습니다.
연결을 설정하려면 사용자 이름, IP 주소 및 암호를 primary_conninfo 매개변수의 값으로 제공해야 합니다. 예를 들어:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'3단계: 보조 서버 다시 시작
마지막으로 보조 서버를 다시 시작하여 구성 프로세스를 완료할 수 있습니다.
그러나 스트리밍 복제에는 다음과 같은 몇 가지 문제가 있습니다.
- 다양한 PostgreSQL 클라이언트(서로 다른 프로그래밍 언어로 작성됨)는 단일 끝점과 대화합니다. 기본 노드가 실패하면 이러한 클라이언트는 동일한 DNS 또는 IP 이름을 계속 재시도합니다. 이렇게 하면 응용 프로그램에 장애 조치가 표시됩니다.
- PostgreSQL 복제는 기본 제공 장애 조치 및 모니터링과 함께 제공되지 않습니다. 기본 노드에 장애가 발생하면 보조 노드를 새 기본 노드로 승격해야 합니다. 이 승격은 클라이언트가 하나의 기본 노드에만 쓰고 데이터 불일치를 관찰하지 않는 방식으로 실행되어야 합니다.
- PostgreSQL은 전체 상태를 복제합니다. 새로운 2차 노드를 개발해야 하는 경우 2차 노드는 1차 노드에서 상태 변경의 전체 기록을 요약해야 합니다. 이는 리소스 집약적이며 헤드에서 노드를 제거하고 새 노드를 생성하는 데 비용이 많이 듭니다.
접근 방식 2: 복제된 블록 장치
복제된 블록 장치 접근 방식은 디스크 미러링(볼륨 복제라고도 함)에 따라 다릅니다. 이 접근 방식에서 변경 사항은 다른 볼륨에 동기적으로 미러링되는 영구 볼륨에 기록됩니다.
이 접근 방식의 추가 이점은 PostgreSQL, MySQL 및 SQL Server를 비롯한 모든 관계형 데이터베이스가 있는 클라우드 환경에서의 호환성 및 데이터 내구성입니다.
그러나 PostgreSQL 복제에 대한 디스크 미러링 방식을 사용하려면 WAL 로그와 테이블 데이터를 모두 복제해야 합니다. 데이터베이스에 대한 각 쓰기는 이제 네트워크를 통해 동기식으로 진행되어야 하므로 데이터베이스가 손상된 상태로 남을 수 있으므로 단일 바이트를 잃을 여유가 없습니다.
이 접근 방식은 일반적으로 Azure PostgreSQL 및 Amazon RDS를 사용하여 활용됩니다.
접근 방식 3: WAL
WAL은 세그먼트 파일(기본적으로 16MB)로 구성됩니다. 각 세그먼트에는 하나 이상의 레코드가 있습니다. LSN(로그 시퀀스 레코드)은 WAL의 레코드에 대한 포인터로, 로그 파일에서 레코드가 저장된 위치/위치를 알려줍니다.
대기 서버는 WAL 세그먼트(PostgreSQL 용어로 XLOGS라고도 함)를 활용하여 기본 서버의 변경 사항을 지속적으로 복제합니다. 미리 쓰기 로깅을 사용하면 바이트 배열 데이터 청크(각각 고유한 LSN이 있음)를 데이터베이스에 적용하기 전에 안정적인 저장소에 직렬화하여 DBMS에 내구성과 원자성을 부여할 수 있습니다.
데이터베이스에 변형을 적용하면 다양한 파일 시스템 작업이 발생할 수 있습니다. 제기되는 관련 질문은 파일 시스템 업데이트 도중 정전으로 인해 서버 장애가 발생한 경우 데이터베이스가 원자성을 보장할 수 있는 방법입니다. 데이터베이스가 부팅되면 사용 가능한 WAL 세그먼트를 읽고 이를 모든 데이터 페이지에 저장된 LSN과 비교할 수 있는 시작 또는 재생 프로세스를 시작합니다(모든 데이터 페이지는 페이지에 영향을 미치는 최신 WAL 레코드의 LSN으로 표시됨).
로그 전달 기반 복제(블록 수준)
스트리밍 복제는 로그 전달 프로세스를 개선합니다. WAL 스위치를 기다리는 것과 달리 레코드가 생성될 때 전송되므로 복제 지연이 줄어듭니다.
스트리밍 복제는 또한 대기 서버가 복제 프로토콜을 활용하여 네트워크를 통해 기본 서버와 연결하기 때문에 로그 전달보다 우선합니다. 그러면 주 서버는 최종 사용자가 제공한 스크립트에 의존하지 않고도 이 연결을 통해 직접 WAL 레코드를 보낼 수 있습니다.
로그 전달 기반 복제(파일 수준)
로그 전달은 WAL 파일을 재생하여 다른 대기 서버를 생성하기 위해 다른 PostgreSQL 서버에 로그 파일을 복사하는 것으로 정의됩니다. 이 서버는 복구 모드에서 작동하도록 구성되어 있으며 유일한 목적은 새 WAL 파일이 표시될 때 적용하는 것입니다.
그러면 이 보조 서버가 기본 PostgreSQL 서버의 웜 백업이 됩니다. 또한 읽기 전용 쿼리(핫 스탠바이라고도 함)를 제공할 수 있는 읽기 전용 복제본으로 구성할 수도 있습니다.
지속적인 WAL 아카이빙
WAL 파일을 아카이브하기 위해 pg_wal 하위 디렉토리가 아닌 다른 위치에 생성할 때 복제하는 것을 WAL 아카이브라고 합니다. PostgreSQL은 WAL 파일이 생성될 때마다 아카이브를 위해 사용자가 제공한 스크립트를 호출합니다.
스크립트는 scp 명령을 활용하여 NFS 마운트와 같은 하나 이상의 위치에 파일을 복제할 수 있습니다. 일단 아카이브되면 WAL 세그먼트 파일을 활용하여 특정 시점에 데이터베이스를 복구할 수 있습니다.
기타 로그 기반 구성은 다음과 같습니다.
- 동기식 복제 : 모든 동기식 복제 트랜잭션이 커밋되기 전에 기본 서버는 대기 서버가 데이터를 얻었음을 확인할 때까지 기다립니다. 이 구성의 이점은 병렬 쓰기 프로세스로 인해 발생하는 충돌이 없다는 것입니다.
- 동기식 다중 마스터 복제 : 여기에서 모든 서버는 쓰기 요청을 수락할 수 있으며 수정된 데이터는 각 트랜잭션이 커밋되기 전에 원래 서버에서 다른 모든 서버로 전송됩니다. 그것은 2PC 프로토콜을 활용하고 all-or-none 규칙을 준수합니다.
WAL 스트리밍 프로토콜 세부 정보
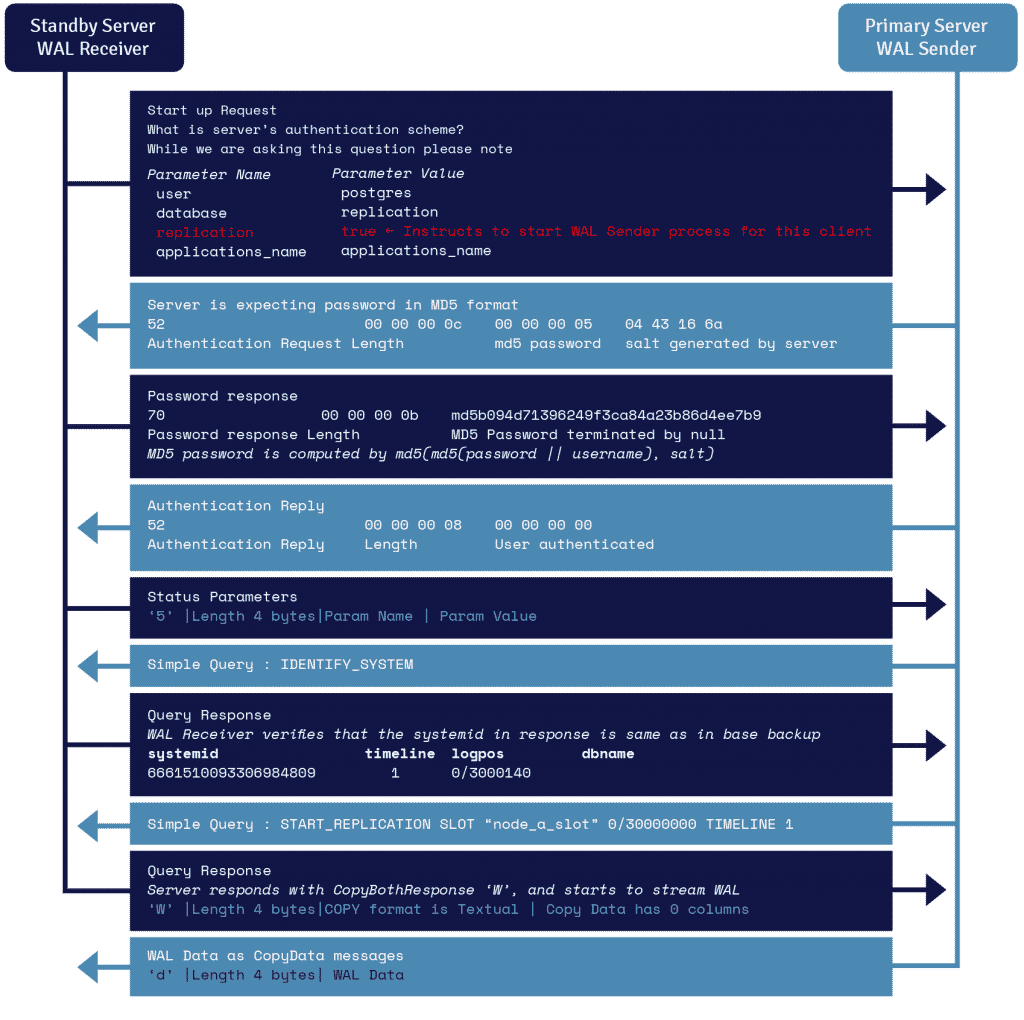
대기 서버에서 실행되는 WAL 수신기로 알려진 프로세스는 recovery.conf 의 primary_conninfo 매개변수에 제공된 연결 세부 정보를 활용하고 TCP/IP 연결을 활용하여 기본 서버에 연결합니다.
스트리밍 복제를 시작하기 위해 프런트엔드는 시작 메시지 내에서 복제 매개변수를 보낼 수 있습니다. true, yes, 1 또는 ON의 부울 값은 백엔드가 물리적 복제 walsender 모드로 전환해야 함을 알립니다.
WAL 발신자는 기본 서버에서 실행되는 또 다른 프로세스이며 WAL 레코드가 생성될 때 대기 서버에 WAL 레코드를 보내는 역할을 합니다. WAL 수신자는 로컬로 연결된 클라이언트의 클라이언트 활동에 의해 생성된 것처럼 WAL 레코드를 WAL에 저장합니다.
WAL 레코드가 WAL 세그먼트 파일에 도달하면 대기 서버는 WAL을 지속적으로 재생하여 기본 및 대기가 최신 상태가 되도록 합니다.
PostgreSQL 복제 요소
이 섹션에서는 일반적으로 사용되는 PostgreSQL 복제 모델(단일 마스터 및 다중 마스터 복제), 유형(물리적 및 논리적 복제), 모드(동기 및 비동기)에 대해 더 깊이 이해할 수 있습니다.

PostgreSQL 데이터베이스 복제 모델
확장성은 수평 및 수직으로 달성할 수 있는 더 많은 데이터를 저장하고 처리할 수 있는 데이터베이스의 기능을 향상시키기 위해 기존 노드에 더 많은 리소스/하드웨어를 추가하는 것을 의미합니다. PostgreSQL 복제는 수직적 확장성보다 구현하기가 훨씬 더 어려운 수평적 확장성의 예입니다. 주로 단일 마스터 복제(SMR) 및 다중 마스터 복제(MMR)를 통해 수평 확장성을 달성할 수 있습니다.
단일 마스터 복제를 사용하면 단일 노드에서만 데이터를 수정할 수 있으며 이러한 수정 사항은 하나 이상의 노드에 복제됩니다. 복제본 데이터베이스의 복제된 테이블은 기본 서버의 변경 사항을 제외하고 변경 사항을 수락할 수 없습니다. 그렇더라도 변경 사항은 기본 서버로 다시 복제되지 않습니다.
대부분의 경우 SMR은 충돌 가능성 없이 구성 및 관리가 덜 복잡하기 때문에 응용 프로그램에 충분합니다. 단일 마스터 복제도 단방향입니다. 복제 데이터는 주로 기본 데이터베이스에서 복제 데이터베이스로 한 방향으로 흐르기 때문입니다.
경우에 따라 SMR만으로는 충분하지 않을 수 있으며 MMR을 구현해야 할 수도 있습니다. MMR을 사용하면 둘 이상의 노드가 기본 노드로 작동할 수 있습니다. 둘 이상의 지정된 기본 데이터베이스의 테이블 행에 대한 변경 사항은 다른 모든 기본 데이터베이스의 해당 테이블에 복제됩니다. 이 모델에서는 중복 기본 키와 같은 문제를 피하기 위해 충돌 해결 방식이 자주 사용됩니다.
MMR을 사용하면 다음과 같은 몇 가지 이점이 있습니다.
- 호스트 오류의 경우 다른 호스트는 계속 업데이트 및 삽입 서비스를 제공할 수 있습니다.
- 기본 노드는 여러 위치에 분산되어 있으므로 모든 기본 노드가 실패할 가능성은 매우 낮습니다.
- 클라이언트 그룹과 지리적으로 가깝지만 네트워크 전체에서 데이터 일관성을 유지할 수 있는 기본 데이터베이스의 WAN(광역 네트워크)을 사용하는 기능.
그러나 MMR 구현의 단점은 복잡성과 충돌 해결의 어려움입니다.
PostgreSQL이 기본적으로 MMR을 지원하지 않기 때문에 여러 지점과 응용 프로그램에서 MMR 솔루션을 제공합니다. 이러한 솔루션은 오픈 소스, 무료 또는 유료일 수 있습니다. 그러한 확장 중 하나는 비동기식이며 PostgreSQL 논리적 디코딩 기능을 기반으로 하는 양방향 복제(BDR)입니다.
BDR 응용 프로그램은 다른 노드에서 트랜잭션을 재생하므로 적용 중인 트랜잭션과 수신 노드에서 커밋된 트랜잭션 사이에 충돌이 있는 경우 재생 작업이 실패할 수 있습니다.
PostgreSQL 복제 유형
PostgreSQL 복제에는 논리적 복제와 물리적 복제의 두 가지 유형이 있습니다.
간단한 논리적 작업 "initdb"는 클러스터의 기본 디렉터리를 만드는 물리적 작업을 수행합니다. 마찬가지로 간단한 논리적 작업 "CREATE DATABASE"는 기본 디렉터리에 하위 디렉터리를 만드는 물리적 작업을 수행합니다.
물리적 복제는 일반적으로 파일과 디렉터리를 다룹니다. 이 파일과 디렉토리가 무엇을 나타내는지 모릅니다. 이러한 방법은 일반적으로 다른 시스템에 있는 단일 클러스터의 전체 데이터 전체 복사본을 유지 관리하는 데 사용되며 파일 시스템 수준 또는 디스크 수준에서 수행되며 정확한 블록 주소를 사용합니다.
논리적 복제는 복제 ID(일반적으로 기본 키)를 기반으로 데이터 엔터티 및 수정 사항을 재현하는 방법입니다. 물리적 복제와 달리 데이터베이스, 테이블 및 DML 작업을 처리하며 데이터베이스 클러스터 수준에서 수행됩니다. 하나 이상의 구독자 가 발행자 노드에서 하나 이상의 발행 에 구독되는 발행 및 구독 모델을 사용합니다.
복제 프로세스는 게시자 데이터베이스에 있는 데이터의 스냅샷을 만든 다음 구독자에게 복사하는 것으로 시작됩니다. 구독자는 구독하는 게시에서 데이터를 가져오고 나중에 데이터를 다시 게시하여 계단식 복제 또는 더 복잡한 구성을 허용할 수 있습니다. 구독자는 게시자와 동일한 순서로 데이터를 적용하므로 트랜잭션 복제라고도 하는 단일 구독 내의 게시에 대해 트랜잭션 일관성이 보장됩니다.
논리적 복제의 일반적인 사용 사례는 다음과 같습니다.
- 단일 데이터베이스(또는 데이터베이스의 하위 집합)의 증분 변경이 발생할 때 구독자에게 전송합니다.
- 여러 데이터베이스 간에 데이터베이스의 하위 집합을 공유합니다.
- 구독자에게 도착한 개별 변경 사항의 실행을 트리거합니다.
- 여러 데이터베이스를 하나로 통합합니다.
- 다른 사용자 그룹에 복제된 데이터에 대한 액세스를 제공합니다.
구독자 데이터베이스는 다른 PostgreSQL 인스턴스와 동일한 방식으로 작동하며 게시를 정의하여 다른 데이터베이스의 게시자로 사용할 수 있습니다.
구독자가 응용 프로그램에서 읽기 전용으로 처리되면 단일 구독에서 충돌이 발생하지 않습니다. 반면에 응용 프로그램이나 동일한 테이블 집합에 대한 다른 구독자가 수행한 다른 쓰기가 있는 경우 충돌이 발생할 수 있습니다.
PostgreSQL은 두 메커니즘을 동시에 지원합니다. 논리적 복제를 통해 데이터 복제와 보안 모두를 세밀하게 제어할 수 있습니다.
복제 모드
PostgreSQL 복제에는 주로 동기 및 비동기의 두 가지 모드가 있습니다. 동기 복제를 사용하면 데이터를 주 서버와 보조 서버에 동시에 쓸 수 있는 반면 비동기 복제는 데이터를 먼저 호스트에 기록한 다음 보조 서버에 복사합니다.
동기 모드 복제에서 기본 데이터베이스의 트랜잭션은 변경 사항이 모든 복제본에 복제된 경우에만 완료된 것으로 간주됩니다. 기본 서버에서 트랜잭션을 완료하려면 복제본 서버를 항상 사용할 수 있어야 합니다. 동기식 복제 모드는 즉각적인 장애 조치가 필요한 고급 트랜잭션 환경에서 사용됩니다.
비동기 모드에서 기본 서버의 트랜잭션은 기본 서버에서만 변경이 완료되었을 때 완료로 선언될 수 있습니다. 이러한 변경 사항은 나중에 복제본에 복제됩니다. 복제 서버는 복제 지연이라고 하는 특정 기간 동안 동기화되지 않은 상태로 유지될 수 있습니다. 충돌의 경우 데이터 손실이 발생할 수 있지만 비동기 복제에서 제공하는 오버헤드가 작기 때문에 대부분의 경우 허용됩니다(호스트에 과부하가 걸리지 않음). 기본 데이터베이스에서 보조 데이터베이스로의 장애 조치는 동기 복제보다 시간이 오래 걸립니다.
PostgreSQL 복제를 설정하는 방법
이 섹션에서는 Linux 운영 체제에서 PostgreSQL 복제 프로세스를 설정하는 방법을 보여줍니다. 이 예에서는 Ubuntu 18.04 LTS 및 PostgreSQL 10을 사용합니다.
파헤쳐보자!
설치
다음 단계에 따라 Linux에 PostgreSQL을 설치하는 것으로 시작합니다.
- 먼저 터미널에 아래 명령을 입력하여 PostgreSQL 서명 키를 가져와야 합니다.
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - 그런 다음 터미널에 아래 명령을 입력하여 PostgreSQL 저장소를 추가합니다.
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - 터미널에 다음 명령을 입력하여 리포지토리 인덱스를 업데이트합니다.
sudo apt-get update - apt 명령을 사용하여 PostgreSQL 패키지를 설치합니다.
sudo apt-get install -y postgresql-10 - 마지막으로 다음 명령을 사용하여 PostgreSQL 사용자의 비밀번호를 설정합니다.
sudo passwd postgres
PostgreSQL 복제 프로세스를 시작하기 전에 주 서버와 보조 서버 모두에 PostgreSQL 설치가 필수입니다.
두 서버 모두에 대해 PostgreSQL을 설정했으면 기본 및 보조 서버의 복제 설정으로 이동할 수 있습니다.
주 서버에서 복제 설정
주 서버와 보조 서버 모두에 PostgreSQL을 설치했으면 이 단계를 수행하십시오.
- 먼저 다음 명령을 사용하여 PostgreSQL 데이터베이스에 로그인합니다.
su - postgres - 다음 명령을 사용하여 복제 사용자를 만듭니다.
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Ubuntu의 nano 응용 프로그램으로 pg_hba.cnf 를 편집하고 다음 구성을 추가합니다. file edit 명령
nano /etc/postgresql/10/main/pg_hba.conf파일을 구성하려면 다음 명령을 사용하십시오.
host replication replication MasterIP/24 md5 - postgresql.conf를 열고 편집하고 다음 구성을 기본 서버에 넣습니다.
nano /etc/postgresql/10/main/postgresql.conf다음 구성 설정을 사용합니다.
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - 마지막으로 기본 주 서버에서 PostgreSQL을 다시 시작합니다.
systemctl restart postgresql이제 기본 서버에서 설정을 완료했습니다.
보조 서버에서 복제 설정
보조 서버에서 복제를 설정하려면 다음 단계를 따르십시오.
- 아래 명령을 사용하여 PostgreSQL RDMS에 로그인합니다.
su - postgres - 아래 명령을 사용하여 작업할 수 있도록 PostgreSQL 서비스의 작동을 중지합니다.
systemctl stop postgresql - 이 명령으로 pg_hba.conf 파일을 편집하고 다음 구성을 추가합니다.
편집 명령nano /etc/postgresql/10/main/pg_hba.conf구성
host replication replication MasterIP/24 md5 - 보조 서버에서 postgresql.conf 를 열고 편집하고 다음 구성을 추가하거나 주석이 있는 경우 주석 처리를 제거합니다. Edit Command
구성nano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP는 보조 서버의 주소입니다.
- 보조 서버의 PostgreSQL 데이터 디렉터리에 액세스하고 모든 항목을 제거합니다.
cd /var/lib/postgresql/10/mainrm -rfv * - PostgreSQL 기본 서버 데이터 디렉터리 파일을 PostgreSQL 보조 서버 데이터 디렉터리에 복사하고 보조 서버에 다음 명령을 작성합니다.
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - 기본 서버 PostgreSQL 암호를 입력하고 Enter 키를 누릅니다. 그런 다음 복구 구성에 대해 다음 명령을 추가합니다. 명령 편집
nano /var/lib/postgresql/10/main/recovery.conf구성
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'여기서 YOUR_PASSWORD는 PostgreSQL이 생성한 기본 서버의 복제 사용자에 대한 암호입니다.
- 암호가 설정되면 중지된 보조 PostgreSQL 데이터베이스를 다시 시작해야 합니다.
systemctl start postgresql설정 테스트
이제 단계를 수행했으므로 복제 프로세스를 테스트하고 보조 서버 데이터베이스를 관찰해 보겠습니다. 이를 위해 기본 서버에 테이블을 생성하고 보조 서버에도 동일한 내용이 반영되는지 관찰합니다.
시작하겠습니다.
- 기본 서버에서 테이블을 생성하기 때문에 기본 서버에 로그인해야 합니다.
su - postgres psql - 이제 'testtable'이라는 간단한 테이블을 만들고 터미널에서 다음 PostgreSQL 쿼리를 실행하여 테이블에 데이터를 삽입합니다.
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - 보조 서버에 로그인하여 보조 서버 PostgreSQL 데이터베이스를 관찰합니다.
su - postgres psql - 이제 'testtable' 테이블이 존재하는지 확인하고 터미널에서 다음 PostgreSQL 쿼리를 실행하여 데이터를 반환할 수 있습니다. 이 명령은 기본적으로 전체 테이블을 표시합니다.
select * from testtable;
다음은 테스트 테이블의 출력입니다.
| websites | ------------------- | section.com | | google.com | | github.com | --------------------주 서버에 있는 것과 동일한 데이터를 관찰할 수 있어야 합니다.
위의 내용이 보이면 복제 프로세스를 성공적으로 수행한 것입니다!
PostgreSQL 수동 장애 조치 단계는 무엇입니까?
PostgreSQL 수동 장애 조치 단계를 살펴보겠습니다.
- 주 서버에 충돌이 발생합니다.
- 대기 서버에서 다음 명령을 실행하여 대기 서버를 승격합니다.
./pg_ctl promote -D ../sb_data/ server promoting - 승격된 대기 서버에 연결하고 행을 삽입합니다.
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values (4,'Four');
삽입이 제대로 작동하면 이전에 읽기 전용 서버였던 대기 서버가 새 기본 서버로 승격된 것입니다.
PostgreSQL에서 장애 조치를 자동화하는 방법
자동 장애 조치를 설정하는 것은 쉽습니다.
EDB PostgreSQL 장애 조치 관리자(EFM)가 필요합니다. 각 기본 및 대기 노드에 EFM을 다운로드 및 설치한 후 기본 노드, 하나 이상의 대기 노드 및 실패 시 어설션을 확인하는 선택적 감시 노드로 구성된 EFM 클러스터를 생성할 수 있습니다.
EFM은 시스템 상태를 지속적으로 모니터링하고 시스템 이벤트를 기반으로 이메일 경고를 보냅니다. 장애가 발생하면 자동으로 최신 대기 서버로 전환하고 다른 모든 대기 서버를 재구성하여 새 기본 노드를 인식합니다.
또한 로드 밸런서(예: pgPool)를 재구성하고 "스플릿 브레인"(두 노드가 각각이 기본 노드라고 생각하는 경우)이 발생하는 것을 방지합니다.
요약
많은 양의 데이터로 인해 확장성과 보안은 특히 트랜잭션 환경에서 데이터베이스 관리에서 가장 중요한 두 가지 기준이 되었습니다. 기존 노드에 더 많은 리소스/하드웨어를 추가하여 수직적으로 확장성을 개선할 수 있지만, 종종 새 하드웨어를 추가하는 비용이나 제한으로 인해 항상 가능한 것은 아닙니다.
따라서 기존 노드의 기능을 향상시키는 것보다 기존 네트워크 노드에 더 많은 노드를 추가하는 수평적 확장성이 필요합니다. 이것이 PostgreSQL 복제가 그림에 등장하는 곳입니다.
이 기사에서는 PostgreSQL 복제 유형, 이점, 복제 모드, 설치 및 SMR과 MMR 간의 PostgreSQL 장애 조치에 대해 논의했습니다. 이제 여러분의 의견을 들어보겠습니다.
일반적으로 어느 것을 구현합니까? 귀하에게 가장 중요한 데이터베이스 기능과 그 이유는 무엇입니까? 우리는 당신의 생각을 읽고 싶습니다! 아래 댓글 섹션에서 공유하세요.