
PostgreSQL レプリケーション: 総合ガイド
公開: 2022-08-11サイト所有者なら誰でも言うように、データの損失とダウンタイムは、最小限の量であっても破滅的な結果をもたらす可能性があります。 彼らはいつでも準備ができていない人を襲う可能性があり、生産性、アクセシビリティ、および製品の信頼性の低下につながります.
サイトの整合性を保護するには、ダウンタイムやデータ損失の可能性に対する保護手段を構築することが不可欠です。
そこでデータ複製の出番です。
データ レプリケーションは、データをメイン データベースから別のリモート ロケーションに繰り返しコピーして保管する、自動化されたバックアップ プロセスです。 これは、データベース サーバーを実行するすべてのサイトまたはアプリにとって不可欠なテクノロジです。 また、複製されたデータベースを利用して読み取り専用 SQL を処理し、システム内でより多くのプロセスを実行できるようにすることもできます。
2 つのデータベース間でレプリケーションを設定すると、予期しない事故に対するフォールト トレランスが提供されます。 これは、災害時に高可用性を実現するための最良の戦略であると考えられています。
この記事では、シームレスな PostgreSQL レプリケーションのためにバックエンド開発者が実装できるさまざまな戦略について詳しく説明します。
PostgreSQL レプリケーションとは?
PostgreSQL レプリケーションは、PostgreSQL データベース サーバーから別のサーバーにデータをコピーするプロセスとして定義されます。 ソース データベース サーバーは「プライマリ」サーバーとも呼ばれ、コピーされたデータを受信するデータベース サーバーは「レプリカ」サーバーと呼ばれます。
PostgreSQL データベースは、すべての書き込みがプライマリ ノードに送信される単純なレプリケーション モデルに従います。 その後、プライマリ ノードはこれらの変更を適用し、セカンダリ ノードにブロードキャストできます。
自動フェールオーバーとは
PostgreSQL で物理ストリーミング レプリケーションが構成されると、データベースのプライマリ サーバーに障害が発生した場合にフェイルオーバーを実行できます。 フェールオーバーは回復プロセスを定義するために使用されますが、サーバー障害の範囲を特定するための組み込みツールが提供されないため、時間がかかる場合があります。
フェールオーバーのために PostgreSQL に依存する必要はありません。 自動フェイルオーバーとスタンバイへの自動切り替えを可能にする専用ツールがあり、データベースのダウンタイムを削減します。
フェールオーバー レプリケーションをセットアップすることで、プライマリ サーバーがダウンした場合にスタンバイを利用できるようにすることで、高可用性を保証します。
PostgreSQL レプリケーションを使用する利点
PostgreSQL レプリケーションを利用する主な利点をいくつか紹介します。
- データの移行: データベース サーバー ハードウェアの変更またはシステムの展開を通じて、データの移行に PostgreSQL レプリケーションを利用できます。
- 耐障害性: プライマリ サーバーに障害が発生した場合、プライマリ サーバーとスタンバイ サーバーの両方に含まれるデータが同じであるため、スタンバイ サーバーがサーバーとして機能できます。
- オンライン トランザクション処理 (OLTP) のパフォーマンス: レポート クエリの負荷を取り除くことで、OLTP システムのトランザクション処理時間とクエリ時間を改善できます。 トランザクション処理時間は、トランザクションが完了する前に特定のクエリが実行されるのにかかる時間です。
- 並行してシステムをテストする: 新しいシステムをアップグレードする際、システムが既存のデータにうまく適合することを確認する必要があるため、展開前に実稼働データベースのコピーでテストする必要があります。
PostgreSQL レプリケーションの仕組み
一般に、プライマリ アーキテクチャとセカンダリ アーキテクチャに手を出す場合、バックアップとレプリケーションをセットアップする方法は 1 つしかないと人々は信じていますが、PostgreSQL のデプロイは次の 3 つのアプローチのいずれかに従います。
- プライマリ ノードからセカンダリ ノードにストレージ レイヤーでレプリケートした後、BLOB/S3 ストレージにバックアップするボリューム レベルのレプリケーション。
- プライマリ ノードからセカンダリ ノードにデータをレプリケートした後、BLOB/S3 ストレージにバックアップするPostgreSQL ストリーミング レプリケーション。
- S3 から新しいセカンダリ ノードを再構築しながら、プライマリ ノードから S3 への増分バックアップを取得します。 セカンダリ ノードがプライマリ ノードの近くにある場合は、プライマリ ノードからストリーミングを開始できます。
アプローチ 1: ストリーミング
WAL レプリケーションとも呼ばれる PostgreSQL ストリーミング レプリケーションは、すべてのサーバーに PostgreSQL をインストールした後、シームレスにセットアップできます。 このレプリケーションのアプローチは、プライマリ データベースからターゲット データベースへの WAL ファイルの移動に基づいています。
プライマリ/セカンダリ構成を使用して、PostgreSQL ストリーミング レプリケーションを実装できます。 プライマリ サーバーは、プライマリ データベースとそのすべての操作を処理するメイン インスタンスです。 セカンダリ サーバーは補助インスタンスとして機能し、プライマリ データベースに加えられたすべての変更をそれ自体で実行し、その過程で同一のコピーを生成します。 プライマリ サーバーは読み取り/書き込みサーバーですが、セカンダリ サーバーは単に読み取り専用です。
このアプローチでは、プライマリ ノードとスタンバイ ノードの両方を構成する必要があります。 次のセクションでは、それらを簡単に構成するための手順を説明します。
プライマリ ノードの構成
次の手順を実行して、ストリーミング レプリケーション用にプライマリ ノードを構成できます。
ステップ 1: データベースを初期化する
データベースを初期化するには、 initidb utilityコマンドを利用できます。 次に、次のコマンドを使用して、レプリケーション権限を持つ新しいユーザーを作成できます。
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';ユーザーは、指定されたクエリのパスワードとユーザー名を提供する必要があります。 replication キーワードは、ユーザーに必要な権限を付与するために使用されます。 クエリの例は次のようになります。
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'ステップ 2: ストリーミング プロパティを構成する
次に、次のように変更できる PostgreSQL 構成ファイル ( postgresql.conf ) を使用してストリーミング プロパティを構成できます。
wal_level = logical wal_log_hints = on max_wal_senders = 8 max_wal_size = 1GB hot_standby = on前のスニペットで使用されたパラメーターの背景を少し説明します。
-
wal_log_hints: このパラメーターは、スタンバイ サーバーがプライマリ サーバーと同期していない場合に役立つpg_rewind機能に必要です。 -
wal_level: このパラメーターを使用して、replicaストリーミング レプリケーションを有効にすることminimalできlogical。 -
max_wal_size: これは、ログ ファイルに保持できる WAL ファイルのサイズを指定するために使用できます。 -
hot_standby: このパラメーターを ON に設定すると、セカンダリとの読み取り接続にこのパラメーターを利用できます。 -
max_wal_senders:max_wal_sendersを使用して、スタンバイ サーバーで確立できる同時接続の最大数を指定できます。
ステップ 3: 新しいエントリを作成する
postgresql.conf ファイルのパラメーターを変更した後、 pg_hba.confファイルの新しいレプリケーション エントリにより、サーバーはレプリケーションのために相互に接続を確立できます。
通常、このファイルは PostgreSQL のデータ ディレクトリにあります。 同じために次のコード スニペットを使用できます。
host replication rep_user IPaddress md5 コード スニペットが実行されると、プライマリ サーバーは、レプリケーション用に指定された IP を使用して、 rep_userというユーザーが接続し、スタンバイ サーバーとして機能することを許可します。 例えば:
host replication rep_user 192.168.0.22/32 md5スタンバイ ノードの構成
ストリーミング レプリケーション用にスタンバイ ノードを構成するには、次の手順に従います。
ステップ 1: プライマリ ノードのバックアップ
スタンバイ ノードを構成するには、 pg_basebackupユーティリティを利用して、プライマリ ノードのバックアップを生成します。 これは、スタンバイ ノードの開始点として機能します。 このユーティリティは、次の構文で使用できます。
pg_basebackp -D -h -X stream -c fast -U rep_user -W上記の構文で使用されるパラメーターは次のとおりです。
-
-h: これを使用して、プライマリ ホストに言及できます。 -
-D: このパラメーターは、現在作業中のディレクトリを示します。 -
-C: これを使用してチェックポイントを設定できます。 -
-X: このパラメーターを使用して、必要なトランザクション ログ ファイルを含めることができます。 -
-W: このパラメーターを使用して、データベースにリンクする前にユーザーにパスワードの入力を求めることができます。
ステップ 2: レプリケーション構成ファイルのセットアップ
次に、レプリケーション構成ファイルが存在するかどうかを確認する必要があります。 そうでない場合は、レプリケーション構成ファイルを recovery.conf として生成できます。
このファイルは、PostgreSQL インストールのデータ ディレクトリに作成する必要があります。 pg_basebackupユーティリティ内で-Rオプションを使用すると、自動的に生成できます。
recovery.confファイルには、次のコマンドが含まれている必要があります。
スタンバイモード = 'オン'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name="host_name"'
recovery_target_timeline = '最新'
前述のコマンドで使用されるパラメーターは次のとおりです。
-
primary_conninfo: これを使用して、接続文字列を利用してプライマリ サーバーとセカンダリ サーバー間の接続を確立できます。 -
standby_mode: このパラメータにより、スイッチがオンになったときにプライマリ サーバがスタンバイとして起動する可能性があります。 -
recovery_target_timeline: これを使用して回復時間を設定できます。
接続をセットアップするには、ユーザー名、IP アドレス、およびパスワードを primary_conninfo パラメーターの値として指定する必要があります。 例えば:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'ステップ 3: セカンダリ サーバーを再起動する
最後に、セカンダリ サーバを再起動して設定プロセスを完了できます。
ただし、ストリーミング レプリケーションには、次のようないくつかの課題があります。
- さまざまな PostgreSQL クライアント (さまざまなプログラミング言語で記述) が、単一のエンドポイントと通信します。 プライマリ ノードに障害が発生すると、これらのクライアントは同じ DNS または IP 名を再試行し続けます。 これにより、フェイルオーバーがアプリケーションから見えるようになります。
- PostgreSQL のレプリケーションには、組み込みのフェールオーバーと監視が付属していません。 プライマリ ノードに障害が発生した場合、セカンダリを新しいプライマリに昇格させる必要があります。 この昇格は、クライアントが 1 つのプライマリ ノードのみに書き込み、データの不整合を観察しない方法で実行する必要があります。
- PostgreSQL はその状態全体を複製します。 新しいセカンダリ ノードを開発する必要がある場合、セカンダリはプライマリ ノードからの状態変更の履歴全体を要約する必要があります。これはリソースを大量に消費し、ヘッド内のノードを削除して新しいノードを作成するにはコストがかかります。
アプローチ 2: レプリケートされたブロック デバイス
レプリケートされたブロック デバイスのアプローチは、ディスク ミラーリング (ボリューム レプリケーションとも呼ばれます) に依存します。 このアプローチでは、別のボリュームに同期的にミラーリングされる永続ボリュームに変更が書き込まれます。
このアプローチの追加の利点は、いくつか例を挙げると、PostgreSQL、MySQL、および SQL Server を含むすべてのリレーショナル データベースとのクラウド環境での互換性とデータの耐久性です。
ただし、PostgreSQL レプリケーションへのディスク ミラーリング アプローチでは、WAL ログとテーブル データの両方をレプリケートする必要があります。 データベースへの各書き込みは同期的にネットワークを経由する必要があるため、データベースが破損した状態になる可能性があるため、1 バイトを失うわけにはいきません。
このアプローチは通常、Azure PostgreSQL と Amazon RDS を使用して活用されます。
アプローチ 3: WAL
WAL はセグメント ファイル (デフォルトで 16 MB) で構成されます。 各セグメントには、1 つ以上のレコードがあります。 ログ シーケンス レコード (LSN) は、WAL 内のレコードへのポインタであり、ログ ファイル内でレコードが保存された位置/場所を示します。
スタンバイ サーバーは、WAL セグメント (PostgreSQL 用語では XLOGS とも呼ばれます) を活用して、プライマリ サーバーからの変更を継続的にレプリケートします。 先行書き込みログを使用して、データベースに適用される前にバイト配列データのチャンク (それぞれが一意の LSN を持つ) を安定したストレージにシリアル化することにより、DBMS で耐久性と原子性を付与できます。
データベースにミューテーションを適用すると、さまざまなファイル システム操作が発生する可能性があります。 ファイル システムの更新中に停電が原因でサーバーに障害が発生した場合に、データベースが原子性をどのように保証できるかという問題が生じます。 データベースが起動すると、利用可能な WAL セグメントを読み取り、それらをすべてのデータ ページに保存されている LSN と比較できる起動または再生プロセスが開始されます (すべてのデータ ページは、ページに影響する最新の WAL レコードの LSN でマークされます)。
ログ配布ベースのレプリケーション (ブロック レベル)
ストリーミング レプリケーションは、ログ配布プロセスを改善します。 WAL スイッチを待つのではなく、レコードが作成されると送信されるため、レプリケーションの遅延が減少します。
また、ストリーミング レプリケーションは、レプリケーション プロトコルを利用してスタンバイ サーバーがネットワーク経由でプライマリ サーバーとリンクするため、ログ配布よりも優先されます。 プライマリ サーバーは、エンド ユーザーが提供するスクリプトに依存することなく、この接続を介して直接 WAL レコードを送信できます。
ログ配布ベースのレプリケーション (ファイル レベル)
ログ配布は、ログ ファイルを別の PostgreSQL サーバーにコピーし、WAL ファイルを再生して別のスタンバイ サーバーを生成することと定義されています。 このサーバーは回復モードで動作するように構成されており、その唯一の目的は、新しい WAL ファイルが表示されたときに適用することです。
このセカンダリ サーバーは、プライマリ PostgreSQL サーバーのウォーム バックアップになります。 また、ホット スタンバイとも呼ばれる読み取り専用クエリを提供できる読み取りレプリカとして構成することもできます。
継続的な WAL アーカイブ
WAL ファイルをアーカイブするために、作成時にpg_walサブディレクトリ以外の場所に複製することを、WAL アーカイブと呼びます。 PostgreSQL は、WAL ファイルが作成されるたびに、アーカイブのためにユーザーが指定したスクリプトを呼び出します。
スクリプトはscpコマンドを利用して、NFS マウントなどの 1 つ以上の場所にファイルを複製できます。 アーカイブが完了すると、WAL セグメント ファイルを利用して、任意の時点でデータベースを復元できます。
その他のログベースの構成には、次のものがあります。
- 同期レプリケーション: すべての同期レプリケーション トランザクションがコミットされる前に、プライマリ サーバーはスタンバイ サーバーがデータを取得したことを確認するまで待機します。 この構成の利点は、並列書き込みプロセスによる競合が発生しないことです。
- 同期マルチマスター レプリケーション: ここでは、すべてのサーバーが書き込み要求を受け入れることができ、各トランザクションがコミットされる前に、変更されたデータが元のサーバーから他のすべてのサーバーに送信されます。 2PC プロトコルを活用し、全か無かのルールに従います。
WAL ストリーミング プロトコルの詳細
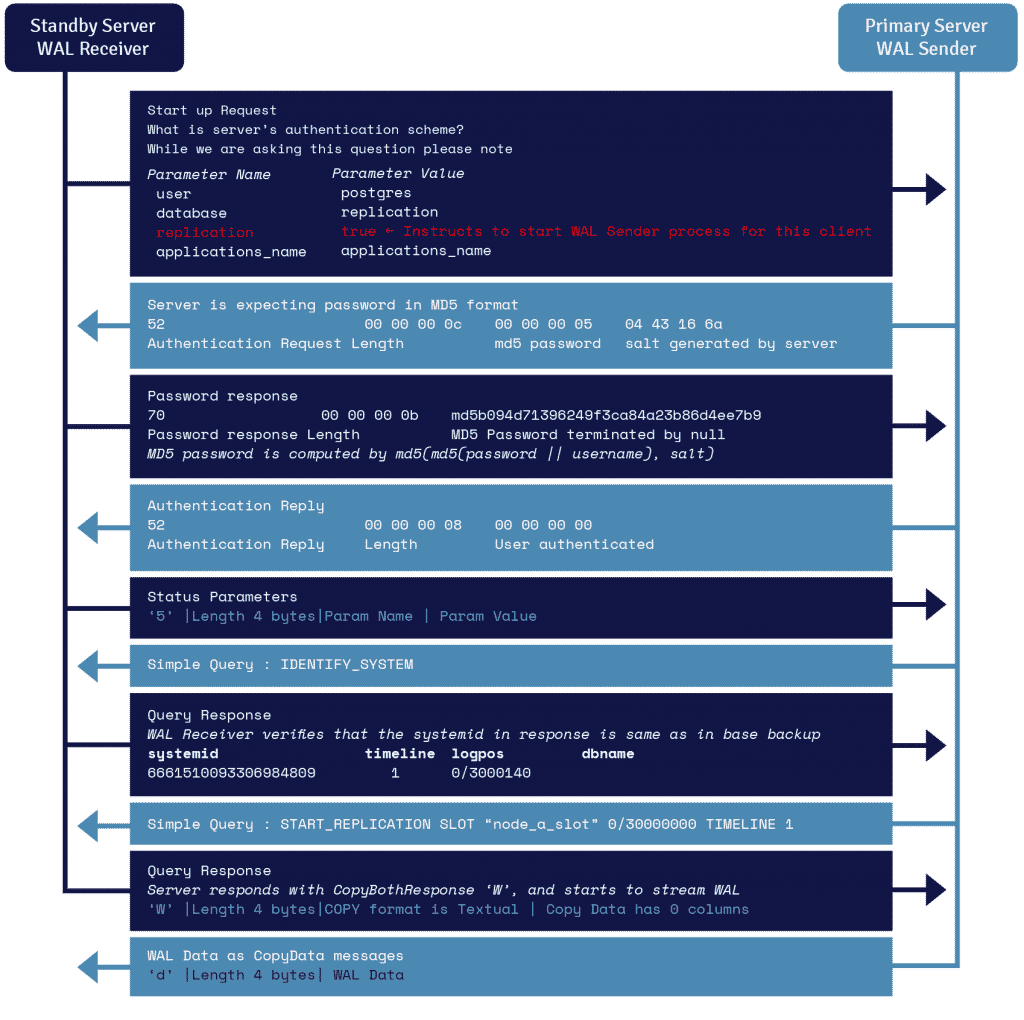
スタンバイ サーバーで実行される WAL レシーバーと呼ばれるプロセスは、 recovery.confのprimary_conninfoパラメータで提供される接続の詳細を利用し、TCP/IP 接続を利用してプライマリ サーバーに接続します。
ストリーミング レプリケーションを開始するために、フロントエンドは起動メッセージ内でレプリケーション パラメータを送信できます。 true、yes、1、または ON のブール値は、バックエンドに、物理レプリケーション walsender モードに入る必要があることを知らせます。
WAL 送信者は、プライマリ サーバー上で実行される別のプロセスであり、生成された WAL レコードをスタンバイ サーバーに送信する役割を担います。 WAL レシーバーは、ローカルに接続されたクライアントのクライアント アクティビティによって作成されたかのように、WAL レコードを WAL に保存します。
WAL レコードが WAL セグメント ファイルに到達すると、スタンバイ サーバーは常に WAL を再生し続け、プライマリとスタンバイが最新の状態になるようにします。
PostgreSQL レプリケーションの要素
このセクションでは、一般的に使用されるモデル (シングルマスターおよびマルチマスター レプリケーション)、タイプ (物理および論理レプリケーション)、および PostgreSQL レプリケーションのモード (同期および非同期) についてより深く理解することができます。

PostgreSQL データベース レプリケーションのモデル
スケーラビリティとは、既存のノードにリソース/ハードウェアを追加して、水平方向および垂直方向に達成できるより多くのデータを保存および処理するデータベースの能力を強化することを意味します。 PostgreSQL のレプリケーションは、垂直方向のスケーラビリティよりも実装がはるかに難しい水平方向のスケーラビリティの例です。 主にシングルマスター レプリケーション (SMR) とマルチマスター レプリケーション (MMR) によって、水平方向のスケーラビリティを実現できます。
シングルマスター レプリケーションでは、データを 1 つのノードでのみ変更でき、これらの変更は 1 つ以上のノードにレプリケートされます。 レプリカ データベース内のレプリケートされたテーブルは、プライマリ サーバーからの変更を除き、変更を受け入れることはできません。 たとえそうであっても、変更はプライマリ サーバーにレプリケートされません。
ほとんどの場合、アプリケーションには SMR で十分です。構成と管理が簡単で、競合の可能性もないからです。 レプリケーション データは主に一方向 (プライマリ データベースからレプリカ データベース) に流れるため、シングルマスター レプリケーションも単方向です。
場合によっては、SMR だけでは不十分な場合があり、MMR を実装する必要がある場合があります。 MMR では、複数のノードをプライマリ ノードとして機能させることができます。 指定された複数のプライマリ データベースのテーブル行に対する変更は、他のすべてのプライマリ データベースの対応するテーブルに複製されます。 このモデルでは、主キーの重複などの問題を回避するために競合解決スキームがよく使用されます。
MMR を使用すると、次のような利点があります。
- ホストに障害が発生した場合でも、他のホストは引き続き更新および挿入サービスを提供できます。
- プライマリ ノードは複数の異なる場所に分散しているため、すべてのプライマリ ノードで障害が発生する可能性は非常に低くなります。
- クライアントのグループに地理的に近いプライマリ データベースのワイド エリア ネットワーク (WAN) を使用しながら、ネットワーク全体でデータの一貫性を維持する機能。
ただし、MMR を実装することの欠点は、複雑さと競合の解決の難しさです。
PostgreSQL は MMR ソリューションをネイティブにサポートしていないため、いくつかのブランチとアプリケーションが MMR ソリューションを提供しています。 これらのソリューションは、オープンソース、無料、または有料の場合があります。 そのような拡張機能の 1 つが双方向レプリケーション (BDR) です。これは非同期で、PostgreSQL の論理デコード機能に基づいています。
BDR アプリケーションは他のノードでトランザクションをリプレイするため、適用されているトランザクションと受信ノードでコミットされたトランザクションとの間に競合がある場合、リプレイ操作が失敗する可能性があります。
PostgreSQL レプリケーションの種類
PostgreSQL のレプリケーションには、論理レプリケーションと物理レプリケーションの 2 種類があります。
単純な論理操作「initdb」は、クラスターのベース ディレクトリを作成する物理操作を実行します。 同様に、単純な論理操作「CREATE DATABASE」は、ベース ディレクトリにサブディレクトリを作成する物理操作を実行します。
通常、物理レプリケーションはファイルとディレクトリを扱います。 これらのファイルとディレクトリが何を表しているかはわかりません。 これらの方法は、通常は別のマシン上にある 1 つのクラスターのデータ全体の完全なコピーを維持するために使用され、ファイル システム レベルまたはディスク レベルで実行され、正確なブロック アドレスを使用します。
論理レプリケーションは、レプリケーション ID (通常は主キー) に基づいて、データ エンティティとその変更を再現する方法です。 物理レプリケーションとは異なり、データベース、テーブル、および DML 操作を処理し、データベース クラスター レベルで実行されます。 1 つ以上のサブスクライバーがパブリッシャーノード上の 1 つ以上のパブリケーションにサブスクライブされるパブリッシュおよびサブスクライブモデルを使用します。
レプリケーション プロセスは、パブリッシャー データベース上のデータのスナップショットを取得し、それをサブスクライバーにコピーすることから始まります。 サブスクライバーは、サブスクライブしているパブリケーションからデータをプルし、後でデータを再パブリッシュして、カスケード レプリケーションやより複雑な構成を可能にします。 サブスクライバーはパブリッシャーと同じ順序でデータを適用するため、トランザクション レプリケーションとも呼ばれる単一のサブスクリプション内のパブリケーションに対してトランザクションの一貫性が保証されます。
論理レプリケーションの一般的な使用例は次のとおりです。
- 1 つのデータベース (またはデータベースのサブセット) の増分変更を、発生時にサブスクライバーに送信します。
- 複数のデータベース間でデータベースのサブセットを共有します。
- 個々の変更がサブスクライバーに到着したときに、それらの変更をトリガーします。
- 複数のデータベースを 1 つに統合します。
- レプリケートされたデータへのアクセスをさまざまなユーザー グループに提供します。
サブスクライバー データベースは、他の PostgreSQL インスタンスと同じように動作し、そのパブリケーションを定義することにより、他のデータベースのパブリッシャーとして使用できます。
サブスクライバーがアプリケーションによって読み取り専用として扱われる場合、単一のサブスクリプションからの競合は発生しません。 一方、アプリケーションまたは他のサブスクライバーによって同じテーブルセットに対して行われた他の書き込みがある場合、競合が発生する可能性があります。
PostgreSQL は両方のメカニズムを同時にサポートします。 論理レプリケーションにより、データのレプリケーションとセキュリティの両方をきめ細かく制御できます。
レプリケーション モード
PostgreSQL レプリケーションには、主に同期と非同期の 2 つのモードがあります。 同期レプリケーションでは、データをプライマリ サーバーとセカンダリ サーバーの両方に同時に書き込むことができますが、非同期レプリケーションでは、データが最初にホストに書き込まれ、次にセカンダリ サーバーにコピーされます。
同期モードのレプリケーションでは、プライマリ データベースのトランザクションは、それらの変更がすべてのレプリカにレプリケートされた場合にのみ完了したと見なされます。 プライマリでトランザクションを完了するには、すべてのレプリカ サーバーが常に使用可能である必要があります。 レプリケーションの同期モードは、すぐにフェールオーバーが必要なハイエンド トランザクション環境で使用されます。
非同期モードでは、変更がプライマリ サーバー上でのみ行われたときに、プライマリ サーバー上のトランザクションが完了したと宣言できます。 これらの変更は、後でレプリカに複製されます。 レプリカ サーバーは、レプリケーション ラグと呼ばれる一定期間、非同期のままになることがあります。 クラッシュの場合、データの損失が発生する可能性がありますが、非同期レプリケーションによって提供されるオーバーヘッドは小さいため、ほとんどの場合は許容されます (ホストに過負荷がかかることはありません)。 プライマリ データベースからセカンダリ データベースへのフェールオーバーは、同期レプリケーションよりも時間がかかります。
PostgreSQL レプリケーションの設定方法
このセクションでは、Linux オペレーティング システムで PostgreSQL レプリケーション プロセスをセットアップする方法を示します。 この例では、Ubuntu 18.04 LTS と PostgreSQL 10 を使用します。
掘り下げましょう!
インストール
次の手順で PostgreSQL を Linux にインストールすることから始めます。
- まず、ターミナルで以下のコマンドを入力して、PostgreSQL 署名キーをインポートする必要があります。
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - 次に、ターミナルで次のコマンドを入力して、PostgreSQL リポジトリを追加します。
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - ターミナルで次のコマンドを入力して、リポジトリ インデックスを更新します。
sudo apt-get update - apt コマンドを使用して PostgreSQL パッケージをインストールします。
sudo apt-get install -y postgresql-10 - 最後に、次のコマンドを使用して PostgreSQL ユーザーのパスワードを設定します。
sudo passwd postgres
PostgreSQL のレプリケーション プロセスを開始する前に、プライマリ サーバーとセカンダリ サーバーの両方に PostgreSQL のインストールが必須です。
両方のサーバーに PostgreSQL をセットアップしたら、プライマリ サーバーとセカンダリ サーバーのレプリケーションのセットアップに進むことができます。
プライマリ サーバーでのレプリケーションの設定
プライマリ サーバーとセカンダリ サーバーの両方に PostgreSQL をインストールしたら、これらの手順を実行します。
- まず、次のコマンドを使用して PostgreSQL データベースにログインします。
su - postgres - 次のコマンドでレプリケーション ユーザーを作成します。
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Ubuntu の任意の nano アプリケーションでpg_hba.cnfを編集し、次の構成を追加します。 file edit コマンド
nano /etc/postgresql/10/main/pg_hba.confファイルを構成するには、次のコマンドを使用します。
host replication replication MasterIP/24 md5 - postgresql.conf を開いて編集し、次の構成をプライマリ サーバーに配置します。
nano /etc/postgresql/10/main/postgresql.conf次の構成設定を使用します。
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - 最後に、プライマリ メイン サーバーで PostgreSQL を再起動します。
systemctl restart postgresqlこれで、プライマリ サーバーでのセットアップが完了しました。
セカンダリ サーバーでのレプリケーションの設定
次の手順に従って、セカンダリ サーバーでレプリケーションをセットアップします。
- 以下のコマンドで PostgreSQL RDMS にログインします。
su - postgres - 以下のコマンドを使用して PostgreSQL サービスを停止し、作業できるようにします。
systemctl stop postgresql - このコマンドでpg_hba.confファイルを編集し、次の構成を追加します。
編集コマンドnano /etc/postgresql/10/main/pg_hba.conf構成
host replication replication MasterIP/24 md5 - セカンダリ サーバーでpostgresql.confを開いて編集し、次の構成を追加するか、コメント化されている場合はコメントを解除します。コマンドの編集
構成nano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP はセカンダリ サーバーのアドレスです。
- セカンダリ サーバーの PostgreSQL データ ディレクトリにアクセスし、すべてを削除します。
cd /var/lib/postgresql/10/mainrm -rfv * - PostgreSQL プライマリ サーバーのデータ ディレクトリ ファイルを PostgreSQL セカンダリ サーバーのデータ ディレクトリにコピーし、次のコマンドをセカンダリ サーバーに書き込みます。
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - プライマリ サーバーの PostgreSQL パスワードを入力し、Enter キーを押します。 次に、リカバリ構成用に次のコマンドを追加します。 Edit Command
nano /var/lib/postgresql/10/main/recovery.conf構成
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'ここで、 YOUR_PASSWORD は、PostgreSQL が作成したプライマリ サーバーのレプリケーション ユーザーのパスワードです。
- パスワードが設定されたら、セカンダリ PostgreSQL データベースが停止されたため、再起動する必要があります。
systemctl start postgresqlセットアップのテスト
手順を実行したので、レプリケーション プロセスをテストし、セカンダリ サーバー データベースを観察します。 このために、プライマリ サーバーにテーブルを作成し、それがセカンダリ サーバーに反映されるかどうかを観察します。
始めましょう。
- プライマリ サーバーにテーブルを作成しているため、プライマリ サーバーにログインする必要があります。
su - postgres psql - 次に、「testtable」という名前の単純なテーブルを作成し、ターミナルで次の PostgreSQL クエリを実行してテーブルにデータを挿入します。
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - セカンダリ サーバーにログインして、セカンダリ サーバーの PostgreSQL データベースを確認します。
su - postgres psql - ここで、テーブル「testtable」が存在するかどうかを確認し、ターミナルで次の PostgreSQL クエリを実行してデータを返すことができるかどうかを確認します。 このコマンドは、基本的にテーブル全体を表示します。
select * from testtable;
これは、テスト テーブルの出力です。
| websites | ------------------- | section.com | | google.com | | github.com | --------------------プライマリ サーバーのデータと同じデータを観察できるはずです。
上記のように表示された場合、レプリケーション プロセスは正常に実行されています。
PostgreSQL の手動フェールオーバー手順とは?
PostgreSQL の手動フェイルオーバーの手順を見てみましょう。
- プライマリ サーバーをクラッシュさせます。
- スタンバイ サーバーで次のコマンドを実行して、スタンバイ サーバーを昇格します。
./pg_ctl promote -D ../sb_data/ server promoting - 昇格したスタンバイ サーバーに接続し、行を挿入します。
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values (4,'Four');
挿入が正常に機能する場合は、以前は読み取り専用サーバーであったスタンバイ サーバーが新しいプライマリ サーバーとして昇格されています。
PostgreSQL でフェイルオーバーを自動化する方法
自動フェイルオーバーの設定は簡単です。
EDB PostgreSQL フェールオーバー マネージャー (EFM) が必要です。 各プライマリ ノードとスタンバイ ノードに EFM をダウンロードしてインストールしたら、EFM クラスタを作成できます。これは、プライマリ ノード、1 つ以上のスタンバイ ノード、および障害発生時にアサーションを確認するオプションの監視ノードで構成されます。
EFM は、システムの状態を継続的に監視し、システム イベントに基づいて電子メール アラートを送信します。 障害が発生すると、最新のスタンバイ サーバーに自動的に切り替わり、他のすべてのスタンバイ サーバーが新しいプライマリ ノードを認識するように再構成されます。
また、ロード バランサー (pgPool など) を再構成し、「スプリット ブレイン」 (2 つのノードがそれぞれプライマリと見なす) の発生を防ぎます。
概要
大量のデータがあるため、スケーラビリティとセキュリティは、データベース管理、特にトランザクション環境における最も重要な基準の 2 つになっています。 既存のノードにリソース/ハードウェアを追加することで垂直方向のスケーラビリティを改善できますが、新しいハードウェアを追加する際のコストや制限が原因で、常に可能であるとは限りません。
したがって、水平方向のスケーラビリティが必要です。これは、既存のノードの機能を強化するのではなく、既存のネットワーク ノードにノードを追加することを意味します。 ここで、PostgreSQL レプリケーションの出番です。
この記事では、PostgreSQL レプリケーションの種類、利点、レプリケーション モード、インストール、および SMR と MMR 間の PostgreSQL フェールオーバーについて説明しました。 それでは、あなたから聞いてみましょう。
通常はどちらを実装しますか? あなたにとって最も重要なデータベース機能はどれですか?その理由は? 皆様のご意見をお待ちしております。 以下のコメントセクションでそれらを共有してください。