
Robots.txt: cos'è e come crearlo (guida completa)
Pubblicato: 2023-05-05Se possiedi un sito web o ne gestisci i contenuti, probabilmente avrai sentito parlare di robots.txt. È un file che istruisce i robot dei motori di ricerca su come scansionare e indicizzare le pagine del tuo sito web. Nonostante la sua importanza nell'ottimizzazione per i motori di ricerca (SEO), molti proprietari di siti web trascurano l'importanza di un file robots.txt ben progettato.
In questa guida completa, esploreremo cos'è robots.txt, perché è importante per la SEO e come creare un file robots.txt per il tuo sito web.
Che cos'è il file Robots.txt?
Un robots.txt è un file che indica ai robot dei motori di ricerca (noti anche come crawler o spider) quali pagine o sezioni di un sito Web devono essere scansionate o meno. È un semplice file di testo situato nella directory principale di un sito Web e in genere include un elenco di directory, file o URL che il webmaster desidera bloccare dall'indicizzazione o dalla scansione del motore di ricerca.
Ecco come appare un file robots.txt:

Perché Robots.txt è importante?
Ci sono tre motivi principali per cui robots.txt è importante per il tuo sito web:
1. Massimizza il Crawl Budget
"Crawl budget" indica il numero di pagine che Google eseguirà la scansione del tuo sito in un dato momento. Il numero dipende dalle dimensioni, dalla salute e dalla quantità di backlink sul tuo sito.
Il crawl budget è importante perché se il numero di pagine del tuo sito supera il crawl budget, avrai pagine che non vengono indicizzate.
Inoltre, le pagine che non sono indicizzate non si classificheranno per nulla.
Utilizzando robots.txt per bloccare le pagine inutili, Googlebot (il crawler web di Google) potrebbe spendere una parte maggiore del tuo budget di scansione per le pagine che contano.
2. Blocca le pagine non pubbliche
Hai molte pagine sul tuo sito che non vuoi indicizzare.
Ad esempio, potresti avere una pagina dei risultati di ricerca interna o una pagina di accesso. Queste pagine devono esistere. Tuttavia, non vuoi che persone a caso atterrino su di loro.
In questo caso, utilizzeresti robots.txt per impedire ai crawler e ai bot dei motori di ricerca di accedere a determinate pagine.
3. Prevenire l'indicizzazione delle risorse
A volte vorrai che Google escluda risorse come PDF, video e immagini dai risultati di ricerca.
Forse vuoi mantenere quelle risorse private o vuoi che Google si concentri maggiormente su contenuti importanti.
In questi casi, l'utilizzo di robots.txt è l'approccio migliore per impedire che vengano indicizzati.
Come funziona un file Robots.txt?
I file Robots.txt indicano ai robot dei motori di ricerca quali pagine o directory del sito Web devono o non devono eseguire la scansione o l'indicizzazione.
Durante la scansione, i robot dei motori di ricerca trovano e seguono i collegamenti. Questo processo li porta dal sito X al sito Y al sito Z su miliardi di link e siti web.
Quando un bot visita un sito, la prima cosa che fa è cercare un file robots.txt.
Se ne rileva uno, leggerà il file prima di fare qualsiasi altra cosa.
Ad esempio, supponi di voler consentire a tutti i bot, tranne DuckDuckGo, di eseguire la scansione del tuo sito:
User-agent: DuckDuckBot Disallow: /
Nota: un file robots.txt può fornire solo istruzioni; non può imporli. È simile a un codice di condotta. I bot buoni (come i bot dei motori di ricerca) seguiranno le regole, mentre i bot cattivi (come i bot spam) le ignoreranno.
Come trovare un file Robots.txt?
Il file robots.txt, come qualsiasi altro file sul tuo sito web, è ospitato sul tuo server.
Puoi accedere al file robots.txt di qualsiasi sito Web inserendo l'URL completo della home page e aggiungendo /robots.txt alla fine, ad esempio https://pickupwp.com/robots.txt.
Tuttavia, se il sito Web non dispone di un file robots.txt, riceverai un messaggio di errore "404 non trovato".
Come creare un file Robots.txt?
Prima di mostrare come creare un file robots.txt, diamo prima un'occhiata alla sintassi robots.txt.
La sintassi di un file robots.txt può essere suddivisa nei seguenti componenti:
- User-agent: specifica il robot o il crawler a cui si applica il record. Ad esempio, "User-agent: Googlebot" si applicherebbe solo al crawler di ricerca di Google, mentre "User-agent: *" si applicherebbe a tutti i crawler.
- Disallow: specifica le pagine o le directory che il robot non deve scansionare. Ad esempio, "Disallow: /private/" impedirebbe ai robot di eseguire la scansione di qualsiasi pagina all'interno della directory "private".
- Consenti: specifica le pagine o le directory che il robot dovrebbe essere autorizzato a scansionare, anche se la directory principale non è consentita. Ad esempio, "Consenti: /public/" consentirebbe ai robot di eseguire la scansione di qualsiasi pagina all'interno della directory "pubblica", anche se la directory principale non è consentita.
- Crawl-delay: specifica la quantità di tempo in secondi che il robot deve attendere prima di eseguire la scansione del sito web. Ad esempio, "Crawl-delay: 10" indica al robot di attendere 10 secondi prima di eseguire la scansione del sito web.
- Mappa del sito: specifica la posizione della mappa del sito del sito web. Ad esempio, "Sitemap: https://www.example.com/sitemap.xml" informerebbe il robot della posizione della mappa del sito web.
Ecco un esempio di file robots.txt:
User-agent: Googlebot Disallow: /private/ Allow: /public/ Crawl-delay: 10 Sitemap: https://www.example.com/sitemap.xml
Nota: è importante notare che i file robots.txt fanno distinzione tra maiuscole e minuscole, quindi è importante utilizzare le maiuscole e minuscole corrette quando si specificano gli URL.
Ad esempio, /public/ non è uguale a /Public/.
D'altra parte, Direttive come "Allow" e "Disallow" non fanno distinzione tra maiuscole e minuscole, quindi sta a te metterle in maiuscolo o meno.
Dopo aver appreso la sintassi di robots.txt, puoi creare un file robots.txt utilizzando uno strumento di generazione di robots.txt o crearne uno tu stesso.
Ecco come creare un file robots.txt in soli quattro passaggi:
1. Crea un nuovo file e chiamalo Robots.txt
Semplicemente aprendo un documento .txt con qualsiasi editor di testo o browser web.
Successivamente, assegna al documento il nome robots.txt. Per funzionare, deve essere chiamato robots.txt.
Una volta terminato, ora puoi iniziare a digitare le direttive.
2. Aggiungere direttive al file Robots.txt
Un file robots.txt contiene uno o più gruppi di direttive, ciascuno con più righe di istruzioni.
Ogni gruppo inizia con uno "User-agent" e contiene i seguenti dati:
- A chi si rivolge il gruppo (lo user-agent)
- A quali directory (pagine) o file può accedere l'agente?
- A quali directory (pagine) o file non può accedere l'agente?
- Una mappa del sito (opzionale) per informare i motori di ricerca sui siti e sui file che ritieni importanti.
Le righe che non corrispondono a nessuna di queste direttive vengono ignorate dai crawler.

Ad esempio, vuoi impedire a Google di eseguire la scansione della tua directory /private/.
Sembrerebbe così:
User-agent: Googlebot Disallow: /private/
Se avessi ulteriori istruzioni come questa per Google, le inseriresti in una riga separata direttamente sotto in questo modo:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google
Inoltre, se hai finito con le istruzioni specifiche di Google e desideri creare un nuovo gruppo di direttive.
Ad esempio, se si desidera impedire a tutti i motori di ricerca di eseguire la scansione delle directory /archive/ e /support/.
Sembrerebbe così:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/
Quando hai finito, puoi aggiungere la tua mappa del sito.
Il tuo file robots.txt completato dovrebbe avere questo aspetto:
User-agent: Googlebot Disallow: /private/ Disallow: /not-for-google User-agent: * Disallow: /archive/ Disallow: /support/ Sitemap: https://www.example.com/sitemap.xml
Successivamente, salva il tuo file robots.txt. Ricorda, deve essere chiamato robots.txt.
Per regole robots.txt più utili, consulta questa utile guida di Google.
3. Carica il file Robots.txt
Dopo aver salvato il tuo file robots.txt sul tuo computer, caricalo sul tuo sito web e rendilo disponibile per la scansione da parte dei motori di ricerca.
Sfortunatamente, non esiste uno strumento che possa aiutare in questo passaggio.
Il caricamento del file robots.txt dipende dalla struttura dei file del tuo sito e dall'hosting web.
Per istruzioni su come caricare il tuo file robots.txt, cerca online o contatta il tuo provider di hosting.
4. Prova il tuo Robots.txt
Dopo aver caricato il file robots.txt, puoi controllare se qualcuno può vederlo e se Google può leggerlo.
Basta aprire una nuova scheda nel browser e cercare il file robots.txt.
Ad esempio, https://pickupwp.com/robots.txt.
Se vedi il tuo file robots.txt, sei pronto per testare il markup (codice HTML).
Per questo, puoi utilizzare un Google robots.txt Tester.
Nota: hai un account Search Console configurato per testare il tuo file robots.txt utilizzando robots.txt Tester.
Il tester di robots.txt troverà eventuali avvisi di sintassi o errori logici e li evidenzierà.
Inoltre, mostra anche gli avvisi e gli errori sotto l'editor.
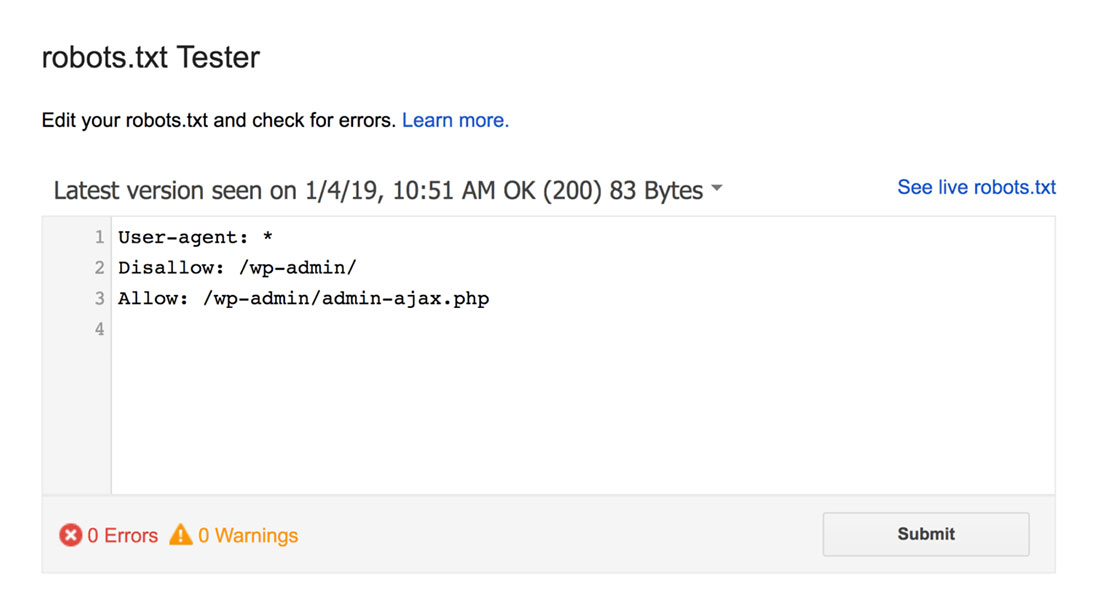
Puoi modificare gli errori o gli avvisi sulla pagina e ripetere il test tutte le volte che è necessario.
Tieni presente che le modifiche apportate alla pagina non vengono salvate sul tuo sito.
Per apportare eventuali modifiche, copia e incolla questo nel file robots.txt del tuo sito.
Best practice di Robots.txt
Tieni a mente queste best practice durante la creazione del tuo file robots.txt per evitare alcuni errori comuni.
1. Usa nuove righe per ogni direttiva
Per evitare confusione per i crawler dei motori di ricerca, aggiungi ciascuna direttiva a una nuova riga nel tuo file robots.txt. Questo vale per entrambe le regole Consenti e Non consentire.
Ad esempio, se non desideri che un web crawler esegua la scansione del tuo blog o della tua pagina di contatto, aggiungi le seguenti regole:
Disallow: /blog/ Disallow: /contact/
2. Utilizzare ogni agente utente solo una volta
I bot non hanno alcun problema se usi lo stesso user agent ancora e ancora.
Tuttavia, usarlo solo una volta mantiene le cose organizzate e riduce la possibilità di errore umano.
3. Utilizzare i caratteri jolly per semplificare le istruzioni
Se hai un numero elevato di pagine da bloccare, l'aggiunta di una regola per ognuna potrebbe richiedere molto tempo. Fortunatamente, puoi usare i caratteri jolly per semplificare le tue istruzioni.
Un carattere jolly è un carattere che può rappresentare uno o più caratteri. Il carattere jolly più comunemente utilizzato è l'asterisco (*).
Ad esempio, se desideri bloccare tutti i file che terminano in .jpg, devi aggiungere la seguente regola:
Disallow: /*.jpg
4. Utilizzare "$" per specificare la fine di un URL
Il simbolo del dollaro ($) è un altro carattere jolly che può essere utilizzato per identificare la fine di un URL. Questo è utile se vuoi limitare una pagina specifica ma non quelle successive.
Supponiamo che tu voglia bloccare la pagina dei contatti ma non la pagina di successo del contatto, dovresti aggiungere la seguente regola:
Disallow: /contact$
5. Usa il cancelletto (#) per aggiungere commenti
Tutto ciò che inizia con un cancelletto (#) viene ignorato dai crawler.
Di conseguenza, gli sviluppatori utilizzano spesso l'hash per aggiungere commenti al file robots.txt. Mantiene il documento organizzato e leggibile.
Ad esempio, se desideri evitare che tutti i file terminino con .jpg, puoi aggiungere il seguente commento:
# Block all files that end in .jpg Disallow: /*.jpg
Questo aiuta chiunque a capire a cosa serve la regola e perché è lì.
6. Utilizzare file Robots.txt separati per ogni sottodominio
Se disponi di un sito Web con più sottodomini, ti consigliamo di creare un singolo file robots.txt per ciascuno di essi. Ciò mantiene le cose organizzate e aiuta i crawler dei motori di ricerca a comprendere più facilmente le tue regole.
Avvolgendo!
Il file robots.txt è un utile strumento SEO poiché istruisce i robot dei motori di ricerca su cosa indicizzare e cosa no.
Tuttavia, è importante usarlo con cautela. Poiché una configurazione errata può comportare la completa deindicizzazione del tuo sito Web (ad esempio, utilizzando Disallow: /).
In generale, il buon modo è consentire ai motori di ricerca di scansionare la maggior parte possibile del tuo sito mantenendo le informazioni sensibili ed evitando i contenuti duplicati. Ad esempio, è possibile utilizzare la direttiva Disallow per impedire pagine o directory specifiche o la direttiva Allow per ignorare una regola Disallow per una determinata pagina.
Vale anche la pena ricordare che non tutti i bot seguono le regole fornite nel file robots.txt, quindi non è un metodo perfetto per controllare ciò che viene indicizzato. Ma è ancora uno strumento prezioso da avere nella tua strategia SEO.
Ci auguriamo che questa guida ti aiuti a capire cos'è un file robots.txt e come crearne uno.
Per ulteriori informazioni, puoi consultare queste altre risorse utili:
- 15 suggerimenti utili per i blog per i nuovi blogger
- Sbloccare il potere delle parole chiave a coda lunga (Guida per principianti)
Infine, seguici su Twitter per aggiornamenti regolari sui nuovi articoli.