
Replica PostgreSQL: una guida completa
Pubblicato: 2022-08-11Come ti dirà qualsiasi proprietario di un sito, la perdita di dati e i tempi di inattività, anche in dosi minime, possono essere catastrofici. Possono colpire gli impreparati in qualsiasi momento, riducendo la produttività, l'accessibilità e la sicurezza del prodotto.
Per proteggere l'integrità del tuo sito, è fondamentale creare protezioni contro la possibilità di tempi di inattività o perdita di dati.
È qui che entra in gioco la replica dei dati.
La replica dei dati è un processo di backup automatizzato in cui i dati vengono copiati ripetutamente dal database principale a un'altra posizione remota per la custodia. È una tecnologia integrale per qualsiasi sito o app che esegue un server di database. È inoltre possibile sfruttare il database replicato per elaborare SQL di sola lettura, consentendo l'esecuzione di più processi all'interno del sistema.
L'impostazione della replica tra due database offre la tolleranza agli errori contro incidenti imprevisti. È considerata la migliore strategia per ottenere un'elevata disponibilità durante i disastri.
In questo articolo, analizzeremo le diverse strategie che possono essere implementate dagli sviluppatori di back-end per una replica PostgreSQL senza interruzioni.
Che cos'è la replica PostgreSQL?
La replica PostgreSQL è definita come il processo di copia dei dati da un server di database PostgreSQL a un altro server. Il server del database di origine è anche noto come server "primario", mentre il server del database che riceve i dati copiati è noto come server di "replica".
Il database PostgreSQL segue un modello di replica semplice, in cui tutte le scritture vanno a un nodo primario. Il nodo primario può quindi applicare queste modifiche e trasmetterle ai nodi secondari.
Che cos'è il failover automatico?
Una volta che la replica del flusso fisico è stata configurata in PostgreSQL, il failover può aver luogo se il server primario del database si guasta. Il failover viene utilizzato per definire il processo di ripristino, che può richiedere del tempo, poiché non fornisce strumenti integrati per individuare gli errori del server.
Non devi dipendere da PostgreSQL per il failover. Sono disponibili strumenti dedicati che consentono il failover automatico e il passaggio automatico allo standby, riducendo i tempi di inattività del database.
Impostando la replica di failover, garantisci un'elevata disponibilità assicurandoti che gli standby siano disponibili in caso di collasso del server primario.
Vantaggi dell'utilizzo della replica PostgreSQL
Ecco alcuni vantaggi chiave dell'utilizzo della replica PostgreSQL:
- Migrazione dei dati : puoi sfruttare la replica PostgreSQL per la migrazione dei dati tramite una modifica dell'hardware del server di database o tramite l'implementazione del sistema.
- Tolleranza agli errori: se il server primario si guasta, il server di standby può fungere da server poiché i dati contenuti sia per il server primario che per quello di standby sono gli stessi.
- Prestazioni dell'elaborazione transazionale in linea (OLTP) : è possibile migliorare il tempo di elaborazione delle transazioni e il tempo di query di un sistema OLTP rimuovendo il carico di query di reporting. Il tempo di elaborazione della transazione è la durata necessaria per l'esecuzione di una determinata query prima del completamento di una transazione.
- Test del sistema in parallelo : durante l'aggiornamento di un nuovo sistema, è necessario assicurarsi che il sistema funzioni bene con i dati esistenti, da qui la necessità di eseguire il test con una copia del database di produzione prima della distribuzione.
Come funziona la replica di PostgreSQL
In genere, le persone credono che quando ci si diletta con un'architettura primaria e secondaria, ci sia un solo modo per configurare backup e replica, ma le distribuzioni di PostgreSQL seguono uno dei tre approcci seguenti:
- Replica a livello di volume per la replica a livello di archiviazione dal nodo primario a quello secondario, seguita dal backup nell'archiviazione BLOB/S3.
- Replica in streaming PostgreSQL per replicare i dati dal nodo primario al nodo secondario, seguita dal backup nell'archiviazione BLOB/S3.
- Esecuzione di backup incrementali dal nodo primario a S3 durante la ricostruzione di un nuovo nodo secondario da S3. Quando il nodo secondario si trova nelle vicinanze del nodo primario, puoi avviare lo streaming dal nodo primario.
Approccio 1: streaming
La replica in streaming PostgreSQL, nota anche come replica WAL, può essere configurata senza problemi dopo l'installazione di PostgreSQL su tutti i server. Questo approccio alla replica si basa sullo spostamento dei file WAL dal database primario al database di destinazione.
È possibile implementare la replica in streaming PostgreSQL utilizzando una configurazione primaria-secondaria. Il server primario è l'istanza principale che gestisce il database primario e tutte le sue operazioni. Il server secondario funge da istanza supplementare ed esegue su se stesso tutte le modifiche apportate al database primario, generando una copia identica nel processo. Il primario è il server di lettura/scrittura mentre il server secondario è di sola lettura.
Per questo approccio, è necessario configurare sia il nodo primario che il nodo standby. Le sezioni seguenti illustreranno i passaggi necessari per configurarli con facilità.
Configurazione del nodo primario
È possibile configurare il nodo principale per la replica in streaming eseguendo i passaggi seguenti:
Passaggio 1: inizializzare il database
Per inizializzare il database, puoi sfruttare il comando initidb utility . Successivamente, puoi creare un nuovo utente con privilegi di replica utilizzando il comando seguente:
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';L'utente dovrà fornire una password e un nome utente per la query data. La parola chiave replica viene utilizzata per fornire all'utente i privilegi richiesti. Una query di esempio sarebbe simile a questa:
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'Passaggio 2: configurare le proprietà di streaming
Successivamente, puoi configurare le proprietà di streaming con il file di configurazione di PostgreSQL ( postgresql.conf ) che può essere modificato come segue:
wal_level = logical wal_log_hints = on max_wal_senders = 8 max_wal_size = 1GB hot_standby = onEcco un piccolo background sui parametri utilizzati nello snippet precedente:
-
wal_log_hints: questo parametro è richiesto per la funzionalitàpg_rewindche risulta utile quando il server di standby non è sincronizzato con il server primario. -
wal_level: puoi utilizzare questo parametro per abilitare la replica in streaming PostgreSQL, con possibili valori inclusiminimal,replicaological. -
max_wal_size: può essere utilizzato per specificare la dimensione dei file WAL che possono essere conservati nei file di registro. -
hot_standby: puoi sfruttare questo parametro per una connessione in lettura con il secondario quando è impostato su ON. -
max_wal_senders: è possibile utilizzaremax_wal_sendersper specificare il numero massimo di connessioni simultanee che possono essere stabilite con i server di standby.
Passaggio 3: crea una nuova voce
Dopo aver modificato i parametri nel file postgresql.conf, una nuova voce di replica nel file pg_hba.conf può consentire ai server di stabilire una connessione tra loro per la replica.
Di solito puoi trovare questo file nella directory dei dati di PostgreSQL. Puoi usare il seguente frammento di codice per lo stesso:
host replication rep_user IPaddress md5 Una volta eseguito il frammento di codice, il server primario consente a un utente chiamato rep_user di connettersi e agire come server di standby utilizzando l'IP specificato per la replica. Per esempio:
host replication rep_user 192.168.0.22/32 md5Configurazione del nodo di attesa
Per configurare il nodo di standby per la replica in streaming, attenersi alla seguente procedura:
Passaggio 1: eseguire il backup del nodo principale
Per configurare il nodo di standby, sfruttare l'utilità pg_basebackup per generare un backup del nodo primario. Questo servirà come punto di partenza per il nodo standby. È possibile utilizzare questa utilità con la seguente sintassi:
pg_basebackp -D -h -X stream -c fast -U rep_user -WI parametri utilizzati nella sintassi sopra menzionata sono i seguenti:
-
-h: puoi usarlo per menzionare l'host principale. -
-D: Questo parametro indica la directory su cui stai attualmente lavorando. -
-C: Puoi usarlo per impostare i checkpoint. -
-X: questo parametro può essere utilizzato per includere i file di registro transazionali necessari. -
-W: È possibile utilizzare questo parametro per richiedere all'utente una password prima di collegarsi al database.
Passaggio 2: configurare il file di configurazione della replica
Successivamente, è necessario verificare se il file di configurazione della replica esiste. In caso contrario, è possibile generare il file di configurazione della replica come recovery.conf.
Dovresti creare questo file nella directory dei dati dell'installazione di PostgreSQL. Puoi generarlo automaticamente usando l'opzione -R all'interno dell'utilità pg_basebackup .
Il file recovery.conf dovrebbe contenere i seguenti comandi:
standby_mode = 'acceso'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name=”host_name”'
recovery_target_timeline = 'ultimo'
I parametri utilizzati nei suddetti comandi sono i seguenti:
-
primary_conninfo: puoi usarlo per stabilire una connessione tra i server primari e secondari sfruttando una stringa di connessione. -
standby_mode: questo parametro può far sì che il server primario si avvii come standby quando viene acceso. -
recovery_target_timeline: puoi usarlo per impostare il tempo di recupero.
Per impostare una connessione, è necessario fornire il nome utente, l'indirizzo IP e la password come valori per il parametro primary_conninfo. Per esempio:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Passaggio 3: riavvia il server secondario
Infine, puoi riavviare il server secondario per completare il processo di configurazione.
Tuttavia, la replica in streaming presenta diverse sfide, come ad esempio:
- Vari client PostgreSQL (scritti in diversi linguaggi di programmazione) dialogano con un unico endpoint. Quando il nodo primario si guasta, questi client continueranno a riprovare con lo stesso nome DNS o IP. Ciò rende il failover visibile all'applicazione.
- La replica PostgreSQL non include failover e monitoraggio integrati. Quando il nodo primario si guasta, devi promuovere un nodo secondario come nuovo primario. Questa promozione deve essere eseguita in modo che i client scrivano su un solo nodo primario e non osservino le incoerenze dei dati.
- PostgreSQL replica il suo intero stato. Quando è necessario sviluppare un nuovo nodo secondario, il secondario deve ricapitolare l'intera cronologia del cambiamento di stato dal nodo primario, che richiede molte risorse e rende costosa l'eliminazione dei nodi nella testa e la creazione di nuovi.
Approccio 2: dispositivo a blocchi replicato
L'approccio del dispositivo a blocchi replicato dipende dal mirroring del disco (noto anche come replica del volume). In questo approccio, le modifiche vengono scritte su un volume persistente che viene rispecchiato in modo sincrono su un altro volume.
Il vantaggio aggiuntivo di questo approccio è la compatibilità e la durabilità dei dati negli ambienti cloud con tutti i database relazionali, inclusi PostgreSQL, MySQL e SQL Server, solo per citarne alcuni.
Tuttavia, l'approccio del mirroring del disco alla replica PostgreSQL richiede la replica dei dati di registro e tabella WAL. Poiché ogni scrittura nel database ora deve passare sulla rete in modo sincrono, non puoi permetterti di perdere un singolo byte, poiché ciò potrebbe lasciare il tuo database in uno stato danneggiato.
Questo approccio viene normalmente sfruttato tramite Azure PostgreSQL e Amazon RDS.
Approccio 3: WAL
WAL è costituito da file di segmento (16 MB per impostazione predefinita). Ogni segmento ha uno o più record. Un record di sequenza di registro (LSN) è un puntatore a un record in WAL, che consente di conoscere la posizione/posizione in cui il record è stato salvato nel file di registro.
Un server standby sfrutta i segmenti WAL, noti anche come XLOGS nella terminologia PostgreSQL, per replicare continuamente le modifiche dal suo server primario. È possibile utilizzare la registrazione write-ahead per garantire la durabilità e l'atomicità in un DBMS serializzando blocchi di dati di array di byte (ciascuno con un LSN univoco) su un'archiviazione stabile prima che vengano applicati a un database.
L'applicazione di una mutazione a un database potrebbe portare a varie operazioni sul file system. Una domanda pertinente che si pone è come un database può garantire l'atomicità in caso di guasto del server a causa di un'interruzione di corrente mentre era nel bel mezzo di un aggiornamento del file system. Quando un database si avvia, avvia un processo di avvio o riproduzione che può leggere i segmenti WAL disponibili e confrontarli con l'LSN memorizzato in ogni pagina di dati (ogni pagina di dati è contrassegnata con l'LSN dell'ultimo record WAL che interessa la pagina).
Replica basata sul log shipping (livello di blocco)
La replica in streaming perfeziona il processo di log shipping. Invece di attendere lo switch WAL, i record vengono inviati man mano che vengono creati, diminuendo così il ritardo di replica.
La replica in streaming ha anche la meglio sul log shipping perché il server di standby si collega al server primario sulla rete sfruttando un protocollo di replica. Il server primario può quindi inviare record WAL direttamente su questa connessione senza dover dipendere dagli script forniti dall'utente finale.
Replica basata sul log shipping (a livello di file)
Il log shipping è definito come la copia di file di registro su un altro server PostgreSQL per generare un altro server di standby riproducendo i file WAL. Questo server è configurato per funzionare in modalità di ripristino e il suo unico scopo è applicare tutti i nuovi file WAL non appena vengono visualizzati.
Questo server secondario diventa quindi un backup a caldo del server PostgreSQL primario. Può anche essere configurato per essere una replica di lettura, dove può offrire query di sola lettura, denominate anche hot standby.
Archiviazione WAL continua
La duplicazione dei file WAL quando vengono creati in qualsiasi posizione diversa dalla sottodirectory pg_wal per archiviarli è nota come archiviazione WAL. PostgreSQL chiamerà uno script fornito dall'utente per l'archiviazione, ogni volta che viene creato un file WAL.
Lo script può sfruttare il comando scp per duplicare il file in una o più posizioni, ad esempio un montaggio NFS. Una volta archiviati, i file del segmento WAL possono essere sfruttati per ripristinare il database in qualsiasi momento.
Altre configurazioni basate su log includono:
- Replica sincrona : prima del commit di ogni transazione di replica sincrona, il server primario attende fino a quando gli standbys non confermano di aver ottenuto i dati. Il vantaggio di questa configurazione è che non ci saranno conflitti causati da processi di scrittura paralleli.
- Replica sincrona multi-master : qui, ogni server può accettare richieste di scrittura e i dati modificati vengono trasmessi dal server originale a ogni altro server prima che ogni transazione venga impegnata. Sfrutta il protocollo 2PC e aderisce alla regola tutto o niente.
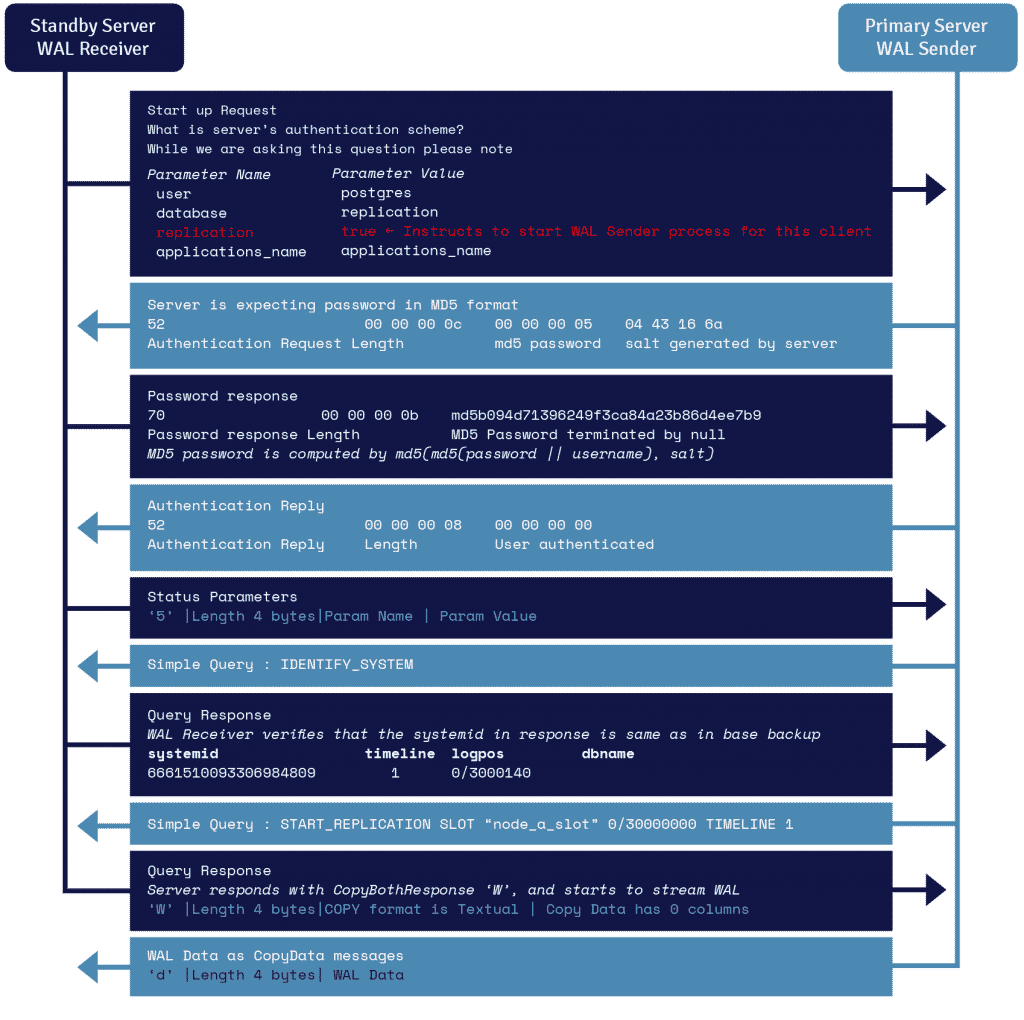
Dettagli del protocollo di streaming WAL
Un processo noto come ricevitore WAL, in esecuzione sul server di standby, sfrutta i dettagli di connessione forniti nel parametro primary_conninfo di recovery.conf e si connette al server primario sfruttando una connessione TCP/IP.
Per avviare la replica in streaming, il frontend può inviare il parametro di replica all'interno del messaggio di avvio. Un valore booleano di true, yes, 1 o ON consente al back-end di sapere che deve passare alla modalità walsender di replica fisica.
Il mittente WAL è un altro processo che viene eseguito sul server primario ed è incaricato di inviare i record WAL al server di standby man mano che vengono generati. Il ricevitore WAL salva i record WAL in WAL come se fossero stati creati dall'attività client dei client connessi localmente.

Una volta che i record WAL raggiungono i file del segmento WAL, il server di standby continua a riprodurre costantemente il WAL in modo che primario e standby siano aggiornati.
Elementi di replica PostgreSQL
In questa sezione acquisirai una comprensione più approfondita dei modelli comunemente usati (replica a master singolo e multimaster), tipi (replica fisica e logica) e modalità (sincrona e asincrona) della replica PostgreSQL.
Modelli di replica del database PostgreSQL
Scalabilità significa aggiungere più risorse/hardware ai nodi esistenti per migliorare la capacità del database di archiviare ed elaborare più dati che possono essere raggiunti orizzontalmente e verticalmente. La replica PostgreSQL è un esempio di scalabilità orizzontale che è molto più difficile da implementare rispetto alla scalabilità verticale. Possiamo ottenere la scalabilità orizzontale principalmente tramite la replica a master singolo (SMR) e la replica a più master (MMR).
La replica a master singolo consente di modificare i dati solo su un singolo nodo e queste modifiche vengono replicate su uno o più nodi. Le tabelle replicate nel database di replica non possono accettare alcuna modifica, ad eccezione di quelle dal server primario. Anche se lo fanno, le modifiche non vengono replicate sul server primario.
Il più delle volte, SMR è sufficiente per l'applicazione perché è meno complicato da configurare e gestire senza possibilità di conflitti. Anche la replica a master singolo è unidirezionale, poiché i dati di replica fluiscono principalmente in una direzione, dal database primario al database di replica.
In alcuni casi, l'SMR da solo potrebbe non essere sufficiente e potrebbe essere necessario implementare l'MMR. MMR consente a più nodi di fungere da nodo primario. Le modifiche alle righe della tabella in più di un database primario designato vengono replicate nelle tabelle della controparte in ogni altro database primario. In questo modello, vengono spesso utilizzati schemi di risoluzione dei conflitti per evitare problemi come la duplicazione delle chiavi primarie.
Ci sono alcuni vantaggi nell'usare MMR, vale a dire:
- In caso di guasto dell'host, altri host possono comunque fornire servizi di aggiornamento e inserimento.
- I nodi primari sono distribuiti in diverse posizioni, quindi la possibilità di guasto di tutti i nodi primari è molto ridotta.
- Capacità di utilizzare una rete WAN (Wide Area Network) di database primari che possono essere geograficamente vicini a gruppi di client, pur mantenendo la coerenza dei dati in tutta la rete.
Tuttavia, lo svantaggio dell'implementazione dell'MMR è la complessità e la difficoltà di risolvere i conflitti.
Diversi rami e applicazioni forniscono soluzioni MMR poiché PostgreSQL non lo supporta in modo nativo. Queste soluzioni possono essere open source, gratuite o a pagamento. Una di queste estensioni è la replica bidirezionale (BDR), che è asincrona e si basa sulla funzione di decodifica logica di PostgreSQL.
Poiché l'applicazione BDR riproduce le transazioni su altri nodi, l'operazione di riproduzione potrebbe non riuscire se si verifica un conflitto tra la transazione applicata e la transazione confermata sul nodo ricevente.
Tipi di replica PostgreSQL
Esistono due tipi di replica PostgreSQL: replica logica e fisica.
Una semplice operazione logica "initdb" eseguirebbe l'operazione fisica di creazione di una directory di base per un cluster. Allo stesso modo, una semplice operazione logica "CREA DATABASE" eseguirebbe l'operazione fisica di creazione di una sottodirectory nella directory di base.
La replica fisica di solito si occupa di file e directory. Non sa cosa rappresentano questi file e directory. Questi metodi vengono utilizzati per mantenere una copia completa di tutti i dati di un singolo cluster, in genere su un'altra macchina, e vengono eseguiti a livello di file system oa livello di disco e utilizzano indirizzi di blocco esatti.
La replica logica è un modo per riprodurre le entità di dati e le loro modifiche, in base alla loro identità di replica (di solito una chiave primaria). A differenza della replica fisica, si occupa di database, tabelle e operazioni DML e viene eseguita a livello di cluster di database. Utilizza un modello di pubblicazione e sottoscrizione in cui uno o più sottoscrittori sono iscritti a una o più pubblicazioni su un nodo editore .
Il processo di replica inizia acquisendo uno snapshot dei dati nel database dell'editore e quindi copiandolo nel sottoscrittore. Gli abbonati estraggono i dati dalle pubblicazioni a cui si abbonano e possono ripubblicare i dati in un secondo momento per consentire la replica a catena o configurazioni più complesse. L'abbonato applica i dati nello stesso ordine dell'editore in modo che la coerenza transazionale sia garantita per le pubblicazioni all'interno di un unico abbonamento noto anche come replica transazionale.
I casi d'uso tipici per la replica logica sono:
- Invio di modifiche incrementali in un singolo database (o un sottoinsieme di un database) agli abbonati non appena si verificano.
- Condivisione di un sottoinsieme del database tra più database.
- Attivazione dell'attivazione delle singole modifiche non appena arrivano all'abbonato.
- Consolidare più database in uno.
- Fornire l'accesso ai dati replicati a diversi gruppi di utenti.
Il database dell'abbonato si comporta allo stesso modo di qualsiasi altra istanza PostgreSQL e può essere utilizzato come editore per altri database definendone le pubblicazioni.
Quando l'abbonato viene trattato come di sola lettura dall'applicazione, non ci saranno conflitti da una singola sottoscrizione. D'altra parte, se sono presenti altre scritture eseguite da un'applicazione o da altri abbonati allo stesso insieme di tabelle, possono sorgere conflitti.
PostgreSQL supporta entrambi i meccanismi contemporaneamente. La replica logica consente un controllo granulare sia sulla replica dei dati che sulla sicurezza.
Modalità di replica
Esistono principalmente due modalità di replica di PostgreSQL: sincrona e asincrona. La replica sincrona consente di scrivere i dati sia sul server primario che su quello secondario contemporaneamente, mentre la replica asincrona garantisce che i dati vengano prima scritti sull'host e quindi copiati sul server secondario.
Nella replica in modalità sincrona, le transazioni nel database primario sono considerate complete solo quando tali modifiche sono state replicate in tutte le repliche. I server di replica devono essere sempre disponibili per il completamento delle transazioni sul server primario. La modalità di replica sincrona viene utilizzata in ambienti transazionali di fascia alta con requisiti di failover immediati.
In modalità asincrona, le transazioni sul server primario possono essere dichiarate complete quando le modifiche sono state eseguite solo sul server primario. Queste modifiche vengono quindi replicate nelle repliche in un secondo momento. I server di replica possono rimanere non sincronizzati per un determinato periodo, chiamato ritardo di replica. In caso di arresto anomalo, potrebbe verificarsi una perdita di dati, ma l'overhead fornito dalla replica asincrona è ridotto, quindi è accettabile nella maggior parte dei casi (non sovraccarica l'host). Il failover dal database primario al database secondario richiede più tempo della replica sincrona.
Come configurare la replica PostgreSQL
Per questa sezione, dimostreremo come impostare il processo di replica di PostgreSQL su un sistema operativo Linux. Per questa istanza, utilizzeremo Ubuntu 18.04 LTS e PostgreSQL 10.
Scendiamo!
Installazione
Inizierai installando PostgreSQL su Linux con questi passaggi:
- Innanzitutto, dovresti importare la chiave di firma di PostgreSQL digitando il comando seguente nel terminale:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Quindi, aggiungi il repository PostgreSQL digitando il comando seguente nel terminale:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Aggiorna l'indice del repository digitando il seguente comando nel terminale:
sudo apt-get update - Installa il pacchetto PostgreSQL usando il comando apt:
sudo apt-get install -y postgresql-10 - Infine, imposta la password per l'utente PostgreSQL usando il seguente comando:
sudo passwd postgres
L'installazione di PostgreSQL è obbligatoria sia per il server primario che per quello secondario prima di avviare il processo di replica di PostgreSQL.
Dopo aver configurato PostgreSQL per entrambi i server, puoi passare alla configurazione della replica del server primario e secondario.
Configurazione della replica nel server primario
Esegui questi passaggi dopo aver installato PostgreSQL su entrambi i server primari e secondari.
- Innanzitutto, accedi al database PostgreSQL con il seguente comando:
su - postgres - Crea un utente di replica con il comando seguente:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Modifica pg_hba.cnf con qualsiasi applicazione nano in Ubuntu e aggiungi la seguente configurazione: comando file edit
nano /etc/postgresql/10/main/pg_hba.confPer configurare il file, utilizzare il comando seguente:
host replication replication MasterIP/24 md5 - Apri e modifica postgresql.conf e inserisci la seguente configurazione nel server primario:
nano /etc/postgresql/10/main/postgresql.confUtilizzare le seguenti impostazioni di configurazione:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - Infine, riavvia PostgreSQL nel server principale primario:
systemctl restart postgresqlOra hai completato l'installazione nel server primario.
Configurazione della replica nel server secondario
Attenersi alla seguente procedura per configurare la replica nel server secondario:
- Accedi a PostgreSQL RDMS con il comando seguente:
su - postgres - Interrompi il funzionamento del servizio PostgreSQL per consentirci di lavorarci sopra con il comando seguente:
systemctl stop postgresql - Modifica il file pg_hba.conf con questo comando e aggiungi la seguente configurazione:
Modifica comandonano /etc/postgresql/10/main/pg_hba.confConfigurazione
host replication replication MasterIP/24 md5 - Apri e modifica postgresql.conf nel server secondario e inserisci la seguente configurazione o decommenta se è commentata: Modifica comando
Configurazionenano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP è l'indirizzo del server secondario
- Accedi alla directory dei dati di PostgreSQL nel server secondario e rimuovi tutto:
cd /var/lib/postgresql/10/mainrm -rfv * - Copia i file della directory dei dati del server primario PostgreSQL nella directory dei dati del server secondario PostgreSQL e scrivi questo comando nel server secondario:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - Immettere la password PostgreSQL del server primario e premere invio. Quindi, aggiungi il seguente comando per la configurazione di ripristino: Modifica comando
nano /var/lib/postgresql/10/main/recovery.confConfigurazione
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Qui, YOUR_PASSWORD è la password per l'utente di replica nel server primario creato da PostgreSQL
- Una volta impostata la password, dovresti riavviare il database PostgreSQL secondario poiché è stato interrotto:
systemctl start postgresqlTestare la tua configurazione
Ora che abbiamo eseguito i passaggi, testiamo il processo di replica e osserviamo il database del server secondario. Per questo, creiamo una tabella nel server primario e osserviamo se lo stesso si riflette sul server secondario.
Andiamo a questo.
- Dato che stiamo creando la tabella nel server primario, dovrai accedere al server primario:
su - postgres psql - Ora creiamo una semplice tabella denominata 'testtable' e inseriamo i dati nella tabella eseguendo le seguenti query PostgreSQL nel terminale:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Osservare il database PostgreSQL del server secondario accedendo al server secondario:
su - postgres psql - Ora controlliamo se la tabella 'testtable' esiste e possiamo restituire i dati eseguendo le seguenti query PostgreSQL nel terminale. Questo comando visualizza essenzialmente l'intera tabella.
select * from testtable;
Questo è l'output della tabella di test:
| websites | ------------------- | section.com | | google.com | | github.com | --------------------Dovresti essere in grado di osservare gli stessi dati di quello nel server primario.
Se vedi quanto sopra, allora hai eseguito con successo il processo di replica!
Quali sono i passaggi di failover manuale di PostgreSQL?
Esaminiamo i passaggi per un failover manuale di PostgreSQL:
- Arresta il server primario.
- Promuovi il server di standby eseguendo il comando seguente sul server di standby:
./pg_ctl promote -D ../sb_data/ server promoting - Connettiti al server di standby promosso e inserisci una riga:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values (4,'Four');
Se l'inserimento funziona correttamente, lo standby, in precedenza un server di sola lettura, è stato promosso come nuovo server primario.
Come automatizzare il failover in PostgreSQL
La configurazione del failover automatico è facile.
Avrai bisogno dell'EDB PostgreSQL failover manager (EFM). Dopo aver scaricato e installato EFM su ciascun nodo primario e di standby, è possibile creare un cluster EFM, costituito da un nodo primario, uno o più nodi Standby e un nodo Witness facoltativo che conferma le asserzioni in caso di errore.
EFM monitora continuamente lo stato del sistema e invia avvisi e-mail in base agli eventi di sistema. Quando si verifica un errore, passa automaticamente allo standby più aggiornato e riconfigura tutti gli altri server di standby per riconoscere il nuovo nodo primario.
Riconfigura inoltre i sistemi di bilanciamento del carico (come pgPool) e impedisce che si verifichi il "cervello diviso" (quando due nodi ciascuno pensa di essere primario).
Riepilogo
A causa dell'elevata quantità di dati, scalabilità e sicurezza sono diventati due dei criteri più importanti nella gestione dei database, soprattutto in un ambiente transazionale. Sebbene possiamo migliorare la scalabilità verticalmente aggiungendo più risorse/hardware ai nodi esistenti, non è sempre possibile, spesso a causa del costo o delle limitazioni dell'aggiunta di nuovo hardware.
Pertanto, è necessaria la scalabilità orizzontale, il che significa aggiungere più nodi ai nodi di rete esistenti piuttosto che migliorare la funzionalità dei nodi esistenti. È qui che entra in gioco la replica di PostgreSQL.
In questo articolo, abbiamo discusso i tipi di repliche di PostgreSQL, i vantaggi, le modalità di replica, l'installazione e il failover di PostgreSQL tra SMR e MMR. Ora sentiamo te.
Quale implementi di solito? Quale caratteristica del database è la più importante per te e perché? Ci piacerebbe leggere i tuoi pensieri! Condividili nella sezione commenti qui sotto.