
Replikasi PostgreSQL: Panduan Komprehensif
Diterbitkan: 2022-08-11Seperti yang akan dikatakan pemilik situs mana pun, kehilangan data dan waktu henti, bahkan dalam dosis minimal, dapat menjadi bencana besar. Mereka dapat melakukan hal yang tidak siap kapan saja, yang mengarah pada penurunan produktivitas, aksesibilitas, dan kepercayaan produk.
Untuk melindungi integritas situs Anda, sangat penting untuk membangun perlindungan terhadap kemungkinan waktu henti atau kehilangan data.
Di situlah replikasi data masuk.
Replikasi data adalah proses pencadangan otomatis di mana data Anda berulang kali disalin dari basis data utamanya ke lokasi lain yang jauh untuk diamankan. Ini adalah teknologi integral untuk situs atau aplikasi apa pun yang menjalankan server database. Anda juga dapat memanfaatkan database yang direplikasi untuk memproses SQL hanya-baca, yang memungkinkan lebih banyak proses dijalankan di dalam sistem.
Menyiapkan replikasi antara dua database menawarkan toleransi kesalahan terhadap kecelakaan tak terduga. Ini dianggap sebagai strategi terbaik untuk mencapai ketersediaan tinggi selama bencana.
Dalam artikel ini, kita akan membahas berbagai strategi yang dapat diterapkan oleh pengembang backend untuk replikasi PostgreSQL yang mulus.
Apa itu Replikasi PostgreSQL?
Replikasi PostgreSQL didefinisikan sebagai proses penyalinan data dari server database PostgreSQL ke server lain. Server database sumber juga dikenal sebagai server "primer", sedangkan server database yang menerima data yang disalin dikenal sebagai server "replika".
Basis data PostgreSQL mengikuti model replikasi langsung, di mana semua penulisan pergi ke node utama. Node utama kemudian dapat menerapkan perubahan ini dan menyiarkannya ke node sekunder.
Apa itu Kegagalan Otomatis?
Setelah replikasi streaming fisik dikonfigurasi di PostgreSQL, failover dapat terjadi jika server utama database gagal. Failover digunakan untuk menentukan proses pemulihan, yang dapat memakan waktu cukup lama, karena tidak menyediakan alat bawaan untuk mengatasi kegagalan server.
Anda tidak harus bergantung pada PostgreSQL untuk failover. Ada alat khusus yang memungkinkan failover otomatis dan peralihan otomatis ke standby, mengurangi downtime database.
Dengan menyiapkan replikasi failover, Anda menjamin ketersediaan tinggi dengan memastikan bahwa siaga tersedia jika server utama pernah runtuh.
Manfaat Menggunakan Replikasi PostgreSQL
Berikut adalah beberapa manfaat utama memanfaatkan replikasi PostgreSQL:
- Migrasi data : Anda dapat memanfaatkan replikasi PostgreSQL untuk migrasi data baik melalui perubahan perangkat keras server database atau melalui penerapan sistem.
- Toleransi kesalahan : Jika server utama gagal, server siaga dapat bertindak sebagai server karena data yang terkandung untuk server utama dan server siaga adalah sama.
- Kinerja pemrosesan transaksional (OLTP) online : Anda dapat meningkatkan waktu pemrosesan transaksi dan waktu kueri sistem OLTP dengan menghapus beban kueri pelaporan. Waktu pemrosesan transaksi adalah durasi yang diperlukan agar kueri tertentu dieksekusi sebelum transaksi selesai.
- Pengujian sistem secara paralel : Saat memutakhirkan sistem baru, Anda perlu memastikan bahwa sistem berjalan dengan baik dengan data yang ada, oleh karena itu perlu menguji dengan salinan basis data produksi sebelum penerapan.
Cara Kerja Replikasi PostgreSQL
Umumnya, orang percaya ketika Anda mencoba arsitektur primer dan sekunder, hanya ada satu cara untuk menyiapkan pencadangan dan replikasi, tetapi penerapan PostgreSQL mengikuti salah satu dari tiga pendekatan berikut:
- Replikasi tingkat volume untuk direplikasi pada lapisan penyimpanan dari node primer ke node sekunder, diikuti dengan mencadangkannya ke penyimpanan blob/S3.
- Replikasi streaming PostgreSQL untuk mereplikasi data dari node primer ke node sekunder, diikuti dengan mencadangkannya ke penyimpanan blob/S3.
- Mengambil cadangan tambahan dari node utama ke S3 saat merekonstruksi node sekunder baru dari S3. Ketika node sekunder berada di sekitar node utama, Anda dapat mulai streaming dari node utama.
Pendekatan 1: Streaming
Replikasi streaming PostgreSQL juga dikenal sebagai replikasi WAL dapat diatur dengan lancar setelah menginstal PostgreSQL di semua server. Pendekatan replikasi ini didasarkan pada pemindahan file WAL dari database utama ke database target.
Anda dapat menerapkan replikasi streaming PostgreSQL dengan menggunakan konfigurasi primer-sekunder. Server utama adalah contoh utama yang menangani database utama dan semua operasinya. Server sekunder bertindak sebagai instance tambahan dan mengeksekusi semua perubahan yang dibuat pada database primer itu sendiri, menghasilkan salinan yang identik dalam prosesnya. Yang utama adalah server baca/tulis sedangkan server sekunder hanya baca-saja.
Untuk pendekatan ini, Anda perlu mengkonfigurasi node utama dan node siaga. Bagian berikut akan menjelaskan langkah-langkah yang terlibat dalam mengonfigurasinya dengan mudah.
Mengkonfigurasi Node Utama
Anda dapat mengonfigurasi node utama untuk replikasi streaming dengan melakukan langkah-langkah berikut:
Langkah 1: Inisialisasi Database
Untuk menginisialisasi database, Anda dapat memanfaatkan perintah initidb utility . Selanjutnya, Anda dapat membuat pengguna baru dengan hak replikasi dengan menggunakan perintah berikut:
CREATE USER REPLICATION LOGIN ENCRYPTED PASSWORD '';Pengguna harus memberikan kata sandi dan nama pengguna untuk kueri yang diberikan. Kata kunci replikasi digunakan untuk memberi pengguna hak istimewa yang diperlukan. Contoh kueri akan terlihat seperti ini:
CREATE USER rep_user REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_pass'Langkah 2: Konfigurasikan Properti Streaming
Selanjutnya, Anda dapat mengkonfigurasi properti streaming dengan file konfigurasi PostgreSQL ( postgresql.conf ) yang dapat dimodifikasi sebagai berikut:
wal_level = logical wal_log_hints = on max_wal_senders = 8 max_wal_size = 1GB hot_standby = onBerikut sedikit latar belakang seputar parameter yang digunakan dalam cuplikan sebelumnya:
-
wal_log_hints: Parameter ini diperlukan untuk kemampuanpg_rewindyang berguna saat server siaga tidak sinkron dengan server utama. -
wal_level: Anda dapat menggunakan parameter ini untuk mengaktifkan replikasi streaming PostgreSQL, dengan kemungkinan nilai termasukminimal,replica, ataulogical. -
max_wal_size: Ini dapat digunakan untuk menentukan ukuran file WAL yang dapat disimpan dalam file log. -
hot_standby: Anda dapat memanfaatkan parameter ini untuk koneksi read-on dengan sekunder saat disetel ke ON. -
max_wal_senders: Anda dapat menggunakanmax_wal_sendersuntuk menentukan jumlah maksimum koneksi bersamaan yang dapat dibuat dengan server siaga.
Langkah 3: Buat Entri Baru
Setelah Anda memodifikasi parameter dalam file postgresql.conf, entri replikasi baru di file pg_hba.conf dapat memungkinkan server untuk membuat koneksi satu sama lain untuk replikasi.
Anda biasanya dapat menemukan file ini di direktori data PostgreSQL. Anda dapat menggunakan cuplikan kode berikut untuk hal yang sama:
host replication rep_user IPaddress md5 Setelah potongan kode dieksekusi, server utama memungkinkan pengguna yang disebut rep_user untuk terhubung dan bertindak sebagai server siaga dengan menggunakan IP yang ditentukan untuk replikasi. Contohnya:
host replication rep_user 192.168.0.22/32 md5Mengonfigurasi Simpul Siaga
Untuk mengkonfigurasi node siaga untuk streaming replikasi, ikuti langkah-langkah berikut:
Langkah 1: Cadangkan Node Utama
Untuk mengonfigurasi node siaga, manfaatkan utilitas pg_basebackup untuk membuat cadangan node utama. Ini akan berfungsi sebagai titik awal untuk node siaga. Anda dapat menggunakan utilitas ini dengan sintaks berikut:
pg_basebackp -D -h -X stream -c fast -U rep_user -WParameter yang digunakan dalam sintaks yang disebutkan di atas adalah sebagai berikut:
-
-h: Anda dapat menggunakan ini untuk menyebutkan host utama. -
-D: Parameter ini menunjukkan direktori yang sedang Anda kerjakan. -
-C: Anda dapat menggunakan ini untuk mengatur pos pemeriksaan. -
-X: Parameter ini dapat digunakan untuk memasukkan file log transaksional yang diperlukan. -
-W: Anda dapat menggunakan parameter ini untuk meminta kata sandi kepada pengguna sebelum menautkan ke database.
Langkah 2: Siapkan File Konfigurasi Replikasi
Selanjutnya, Anda perlu memeriksa apakah file konfigurasi replikasi ada. Jika tidak, Anda dapat membuat file konfigurasi replikasi sebagai recovery.conf.
Anda harus membuat file ini di direktori data instalasi PostgreSQL. Anda dapat membuatnya secara otomatis dengan menggunakan opsi -R dalam utilitas pg_basebackup .
File recovery.conf harus berisi perintah berikut:
standby_mode = 'aktif'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name=”host_name”'
recovery_target_timeline = 'terbaru'
Parameter yang digunakan dalam perintah di atas adalah sebagai berikut:
-
primary_conninfo: Anda dapat menggunakan ini untuk membuat koneksi antara server primer dan sekunder dengan memanfaatkan string koneksi. -
standby_mode: Parameter ini dapat menyebabkan server utama mulai sebagai standby saat dinyalakan. -
recovery_target_timeline: Anda dapat menggunakan ini untuk mengatur waktu pemulihan.
Untuk menyiapkan koneksi, Anda perlu memberikan nama pengguna, alamat IP, dan kata sandi sebagai nilai untuk parameter primary_conninfo. Contohnya:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Langkah 3: Mulai Ulang Server Sekunder
Terakhir, Anda dapat memulai ulang server sekunder untuk menyelesaikan proses konfigurasi.
Namun, replikasi streaming memiliki beberapa tantangan, seperti:
- Berbagai klien PostgreSQL (ditulis dalam bahasa pemrograman yang berbeda) berkomunikasi dengan satu titik akhir. Ketika node utama gagal, klien ini akan terus mencoba lagi DNS atau nama IP yang sama. Ini membuat failover terlihat oleh aplikasi.
- Replikasi PostgreSQL tidak disertai dengan failover dan pemantauan bawaan. Ketika simpul utama gagal, Anda perlu mempromosikan simpul sekunder untuk menjadi simpul utama baru. Promosi ini perlu dijalankan dengan cara di mana klien menulis hanya ke satu node utama, dan mereka tidak mengamati inkonsistensi data.
- PostgreSQL mereplikasi seluruh statusnya. Saat Anda perlu mengembangkan simpul sekunder baru, simpul sekunder perlu merekap seluruh riwayat perubahan status dari simpul utama, yang membutuhkan banyak sumber daya dan membuatnya mahal untuk menghilangkan simpul di kepala dan membuat yang baru.
Pendekatan 2: Perangkat Blok yang Direplikasi
Pendekatan perangkat blok yang direplikasi bergantung pada pencerminan disk (juga dikenal sebagai replikasi volume). Dalam pendekatan ini, perubahan ditulis ke volume persisten yang secara sinkron dicerminkan ke volume lain.
Manfaat tambahan dari pendekatan ini adalah kompatibilitas dan ketahanan datanya di lingkungan cloud dengan semua database relasional, termasuk PostgreSQL, MySQL, dan SQL Server, untuk beberapa nama.
Namun, pendekatan disk-mirroring untuk replikasi PostgreSQL mengharuskan Anda untuk mereplikasi data log dan tabel WAL. Karena setiap penulisan ke database sekarang harus melalui jaringan secara serempak, Anda tidak boleh kehilangan satu byte pun, karena hal itu dapat membuat database Anda rusak.
Pendekatan ini biasanya dimanfaatkan menggunakan Azure PostgreSQL dan Amazon RDS.
Pendekatan 3: WAL
WAL terdiri dari file segmen (16 MB secara default). Setiap segmen memiliki satu atau lebih record. Catatan urutan log (LSN) adalah penunjuk ke catatan di WAL, memberi tahu Anda posisi/lokasi tempat catatan disimpan dalam file log.
Server siaga memanfaatkan segmen WAL — juga dikenal sebagai XLOGS dalam terminologi PostgreSQL — untuk terus mereplikasi perubahan dari server utamanya. Anda dapat menggunakan write-ahead logging untuk memberikan daya tahan dan atomisitas dalam DBMS dengan membuat serial potongan data byte-array (masing-masing dengan LSN unik) ke penyimpanan yang stabil sebelum diterapkan ke database.
Menerapkan mutasi ke database dapat menyebabkan berbagai operasi sistem file. Pertanyaan terkait yang muncul adalah bagaimana database dapat memastikan atomisitas jika terjadi kegagalan server karena pemadaman listrik saat berada di tengah pembaruan sistem file. Ketika database melakukan boot, itu memulai proses startup atau replay yang dapat membaca segmen WAL yang tersedia dan membandingkannya dengan LSN yang disimpan pada setiap halaman data (setiap halaman data ditandai dengan LSN dari catatan WAL terbaru yang mempengaruhi halaman).
Replikasi Berbasis Pengiriman Log (Tingkat Blok)
Replikasi streaming menyempurnakan proses pengiriman log. Berbeda dengan menunggu sakelar WAL, catatan dikirim saat dibuat, sehingga mengurangi penundaan replikasi.
Replikasi streaming juga mengalahkan pengiriman log karena server siaga terhubung dengan server utama melalui jaringan dengan memanfaatkan protokol replikasi. Server utama kemudian dapat mengirim catatan WAL secara langsung melalui koneksi ini tanpa harus bergantung pada skrip yang disediakan oleh pengguna akhir.
Replikasi Berbasis Pengiriman Log (Level File)
Pengiriman log didefinisikan sebagai menyalin file log ke server PostgreSQL lain untuk menghasilkan server siaga lain dengan memutar ulang file WAL. Server ini dikonfigurasi untuk bekerja dalam mode pemulihan, dan satu-satunya tujuan adalah untuk menerapkan file WAL baru saat muncul.
Server sekunder ini kemudian menjadi cadangan hangat dari server PostgreSQL utama. Itu juga dapat dikonfigurasi untuk menjadi replika baca, di mana ia dapat menawarkan kueri hanya-baca, juga disebut sebagai siaga panas.
Pengarsipan WAL Berkelanjutan
Menggandakan file WAL saat dibuat ke lokasi mana pun selain subdirektori pg_wal untuk mengarsipkannya dikenal sebagai pengarsipan WAL. PostgreSQL akan memanggil skrip yang diberikan oleh pengguna untuk pengarsipan, setiap kali file WAL dibuat.
Script dapat memanfaatkan perintah scp untuk menduplikasi file ke satu atau lebih lokasi seperti NFS mount. Setelah diarsipkan, file segmen WAL dapat dimanfaatkan untuk memulihkan database pada titik waktu tertentu.
Konfigurasi berbasis log lainnya meliputi:
- Replikasi sinkron : Sebelum setiap transaksi replikasi sinkron dilakukan, server utama menunggu hingga standbys mengonfirmasi bahwa mereka mendapatkan data. Manfaat dari konfigurasi ini adalah tidak akan ada konflik yang disebabkan karena proses penulisan paralel.
- Replikasi multi-master sinkron : Di sini, setiap server dapat menerima permintaan tulis, dan data yang dimodifikasi dikirim dari server asli ke setiap server lain sebelum setiap transaksi dilakukan. Ini memanfaatkan protokol 2PC dan mematuhi aturan semua atau tidak sama sekali.
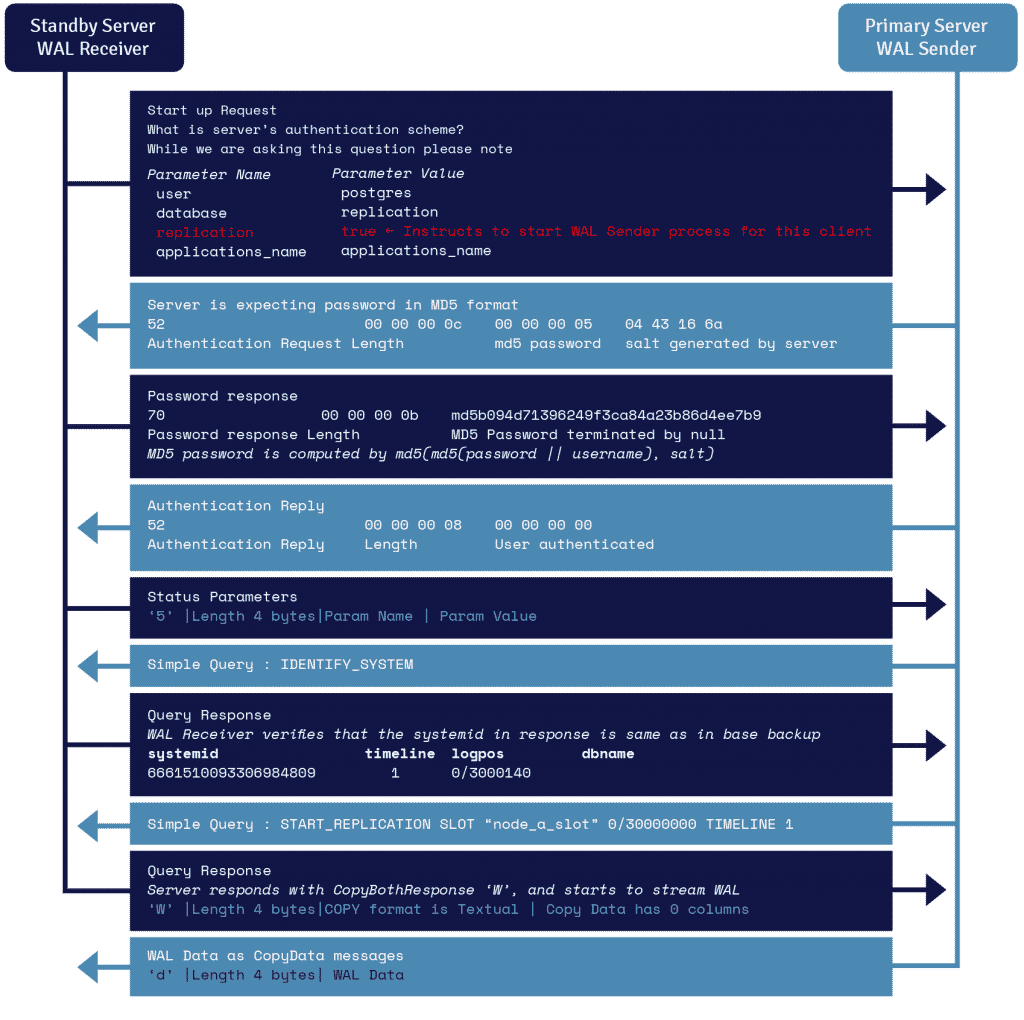
Detail Protokol Streaming WAL
Proses yang dikenal sebagai penerima WAL, berjalan di server siaga, memanfaatkan detail koneksi yang disediakan dalam parameter primary_conninfo dari recovery.conf dan menghubungkan ke server utama dengan memanfaatkan koneksi TCP/IP.
Untuk memulai streaming replikasi, frontend dapat mengirim parameter replikasi dalam pesan startup. Nilai Boolean true, yes, 1, atau ON memungkinkan backend mengetahui bahwa ia perlu masuk ke mode walsender replikasi fisik.
Pengirim WAL adalah proses lain yang berjalan di server utama dan bertanggung jawab mengirimkan catatan WAL ke server siaga saat dihasilkan. Penerima WAL menyimpan catatan WAL di WAL seolah-olah dibuat oleh aktivitas klien dari klien yang terhubung secara lokal.

Setelah catatan WAL mencapai file segmen WAL, server siaga terus-menerus memutar ulang WAL sehingga primer dan siaga diperbarui.
Elemen Replikasi PostgreSQL
Di bagian ini, Anda akan mendapatkan pemahaman yang lebih mendalam tentang model yang umum digunakan (replikasi master tunggal dan multi-master), jenis (replikasi fisik dan logika), dan mode (sinkron dan asinkron) replikasi PostgreSQL.
Model Replikasi Database PostgreSQL
Skalabilitas berarti menambahkan lebih banyak sumber daya / perangkat keras ke node yang ada untuk meningkatkan kemampuan database untuk menyimpan dan memproses lebih banyak data yang dapat dicapai secara horizontal dan vertikal. Replikasi PostgreSQL adalah contoh skalabilitas horizontal yang jauh lebih sulit diterapkan daripada skalabilitas vertikal. Kami dapat mencapai skalabilitas horizontal terutama dengan replikasi master tunggal (SMR) dan replikasi multi-master (MMR).
Replikasi master tunggal memungkinkan data untuk dimodifikasi hanya pada satu node, dan modifikasi ini direplikasi ke satu atau lebih node. Tabel yang direplikasi dalam database replika tidak diizinkan untuk menerima perubahan apa pun, kecuali yang berasal dari server utama. Bahkan jika mereka melakukannya, perubahan tidak direplikasi kembali ke server utama.
Sebagian besar waktu, SMR sudah cukup untuk aplikasi karena tidak terlalu rumit untuk dikonfigurasi dan dikelola serta tidak ada kemungkinan konflik. Replikasi master tunggal juga searah, karena data replikasi mengalir dalam satu arah terutama, dari basis data utama ke basis data replika.
Dalam beberapa kasus, SMR saja mungkin tidak cukup, dan Anda mungkin perlu menerapkan MMR. MMR memungkinkan lebih dari satu node untuk bertindak sebagai node utama. Perubahan baris tabel di lebih dari satu database utama yang ditunjuk direplikasi ke tabel rekan mereka di setiap database utama lainnya. Dalam model ini, skema resolusi konflik sering digunakan untuk menghindari masalah seperti duplikat kunci utama.
Ada beberapa keuntungan menggunakan MMR, yaitu:
- Dalam kasus kegagalan host, host lain masih dapat memberikan layanan pembaruan dan penyisipan.
- Node utama tersebar di beberapa lokasi yang berbeda, sehingga kemungkinan kegagalan semua node utama sangat kecil.
- Kemampuan untuk menggunakan jaringan area luas (WAN) dari basis data utama yang secara geografis dapat dekat dengan kelompok klien, namun tetap menjaga konsistensi data di seluruh jaringan.
Namun, kelemahan dari penerapan MMR adalah kerumitan dan kesulitannya untuk menyelesaikan konflik.
Beberapa cabang dan aplikasi menyediakan solusi MMR karena PostgreSQL tidak mendukungnya secara asli. Solusi ini mungkin open-source, gratis, atau berbayar. Salah satu ekstensi tersebut adalah replikasi dua arah (BDR) yang asinkron dan didasarkan pada fungsi decoding logis PostgreSQL.
Karena aplikasi BDR memutar ulang transaksi di node lain, operasi replay mungkin gagal jika ada konflik antara transaksi yang diterapkan dan transaksi yang dilakukan pada node penerima.
Jenis Replikasi PostgreSQL
Ada dua jenis replikasi PostgreSQL: replikasi logis dan fisik.
Operasi logis sederhana "initdb" akan melakukan operasi fisik untuk membuat direktori dasar untuk sebuah cluster. Demikian juga, operasi logis sederhana "CREATE DATABASE" akan melakukan operasi fisik untuk membuat subdirektori di direktori dasar.
Replikasi fisik biasanya berhubungan dengan file dan direktori. Itu tidak tahu apa yang diwakili oleh file dan direktori ini. Metode ini digunakan untuk memelihara salinan lengkap dari seluruh data dari satu cluster, biasanya pada komputer lain, dan dilakukan pada tingkat sistem file atau tingkat disk dan menggunakan alamat blok yang tepat.
Replikasi logis adalah cara mereproduksi entitas data dan modifikasinya, berdasarkan identitas replikasinya (biasanya kunci utama). Tidak seperti replikasi fisik, ini berhubungan dengan database, tabel, dan operasi DML dan dilakukan pada tingkat cluster database. Ini menggunakan model terbitkan dan berlangganan di mana satu atau lebih pelanggan berlangganan satu atau lebih publikasi di node penerbit .
Proses replikasi dimulai dengan mengambil snapshot data pada database penerbit dan kemudian menyalinnya ke pelanggan. Pelanggan menarik data dari publikasi yang mereka langgani dan dapat memublikasikan ulang data nanti untuk memungkinkan replikasi berjenjang atau konfigurasi yang lebih kompleks. Pelanggan menerapkan data dalam urutan yang sama seperti penerbit sehingga konsistensi transaksi dijamin untuk publikasi dalam satu langganan juga dikenal sebagai replikasi transaksional.
Kasus penggunaan khas untuk replikasi logis adalah:
- Mengirim perubahan tambahan dalam satu database (atau subset database) ke pelanggan saat terjadi.
- Berbagi subset database antara beberapa database.
- Memicu pengaktifan perubahan individual saat tiba di pelanggan.
- Menggabungkan beberapa database menjadi satu.
- Menyediakan akses ke data yang direplikasi ke berbagai kelompok pengguna.
Basis data pelanggan berperilaku dengan cara yang sama seperti instance PostgreSQL lainnya dan dapat digunakan sebagai penerbit untuk basis data lain dengan mendefinisikan publikasinya.
Ketika pelanggan diperlakukan sebagai hanya-baca oleh aplikasi, tidak akan ada konflik dari satu langganan. Di sisi lain, jika ada penulisan lain yang dilakukan oleh aplikasi atau pelanggan lain ke kumpulan tabel yang sama, konflik dapat muncul.
PostgreSQL mendukung kedua mekanisme secara bersamaan. Replikasi logis memungkinkan kontrol halus atas replikasi dan keamanan data.
Mode Replikasi
Ada dua mode utama replikasi PostgreSQL: sinkron dan asinkron. Replikasi sinkron memungkinkan data ditulis ke server primer dan sekunder secara bersamaan, sedangkan replikasi asinkron memastikan bahwa data pertama kali ditulis ke host dan kemudian disalin ke server sekunder.
Dalam replikasi mode sinkron, transaksi di database utama dianggap selesai hanya jika perubahan tersebut telah direplikasi ke semua replika. Semua server replika harus tersedia sepanjang waktu agar transaksi diselesaikan di server utama. Mode replikasi sinkron digunakan di lingkungan transaksional kelas atas dengan persyaratan failover segera.
Dalam mode asinkron, transaksi di server utama dapat dinyatakan selesai ketika perubahan telah dilakukan hanya pada server utama. Perubahan ini kemudian direplikasi dalam replika di kemudian hari. Server replika dapat tetap tidak sinkron selama durasi tertentu, yang disebut jeda replikasi. Dalam kasus crash, kehilangan data dapat terjadi, tetapi overhead yang disediakan oleh replikasi asinkron kecil, sehingga dapat diterima dalam banyak kasus (tidak membebani host). Failover dari database utama ke database sekunder membutuhkan waktu lebih lama dari replikasi sinkron.
Cara Mengatur Replikasi PostgreSQL
Untuk bagian ini, kami akan mendemonstrasikan cara mengatur proses replikasi PostgreSQL pada sistem operasi Linux. Untuk contoh ini, kami akan menggunakan Ubuntu 18.04 LTS dan PostgreSQL 10.
Mari kita menggali!
Instalasi
Anda akan mulai dengan menginstal PostgreSQL di Linux dengan langkah-langkah berikut:
- Pertama, Anda harus mengimpor kunci penandatanganan PostgreSQL dengan mengetikkan perintah di bawah ini di terminal:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Kemudian, tambahkan repositori PostgreSQL dengan mengetikkan perintah di bawah ini di terminal:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Perbarui Indeks Repositori dengan mengetikkan perintah berikut di terminal:
sudo apt-get update - Instal paket PostgreSQL menggunakan perintah apt:
sudo apt-get install -y postgresql-10 - Terakhir, atur kata sandi untuk pengguna PostgreSQL menggunakan perintah berikut:
sudo passwd postgres
Instalasi PostgreSQL adalah wajib untuk server primer dan sekunder sebelum memulai proses replikasi PostgreSQL.
Setelah Anda menyiapkan PostgreSQL untuk kedua server, Anda dapat melanjutkan ke pengaturan replikasi server primer dan sekunder.
Menyiapkan Replikasi di Server Utama
Lakukan langkah-langkah ini setelah Anda menginstal PostgreSQL di server primer dan sekunder.
- Pertama, masuk ke database PostgreSQL dengan perintah berikut:
su - postgres - Buat pengguna replikasi dengan perintah berikut:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Edit pg_hba.cnf dengan aplikasi nano apa pun di Ubuntu dan tambahkan konfigurasi berikut: perintah edit file
nano /etc/postgresql/10/main/pg_hba.confUntuk mengkonfigurasi file, gunakan perintah berikut:
host replication replication MasterIP/24 md5 - Buka dan edit postgresql.conf dan letakkan konfigurasi berikut di server utama:
nano /etc/postgresql/10/main/postgresql.confGunakan pengaturan konfigurasi berikut:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - Terakhir, restart PostgreSQL di server utama utama:
systemctl restart postgresqlAnda sekarang telah menyelesaikan penyiapan di server utama.
Menyiapkan Replikasi di Server Sekunder
Ikuti langkah-langkah berikut untuk menyiapkan replikasi di server sekunder:
- Login ke PostgreSQL RDMS dengan perintah di bawah ini:
su - postgres - Hentikan layanan PostgreSQL agar kami dapat mengerjakannya dengan perintah di bawah ini:
systemctl stop postgresql - Edit file pg_hba.conf dengan perintah ini dan tambahkan konfigurasi berikut:
Edit Perintahnano /etc/postgresql/10/main/pg_hba.confKonfigurasi
host replication replication MasterIP/24 md5 - Buka dan edit postgresql.conf di server sekunder dan masukkan konfigurasi berikut atau batalkan komentar jika dikomentari: Edit Command
Konfigurasinano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIP adalah alamat server sekunder
- Akses direktori data PostgreSQL di server sekunder dan hapus semuanya:
cd /var/lib/postgresql/10/mainrm -rfv * - Salin file direktori data server utama PostgreSQL ke direktori data server sekunder PostgreSQL dan tulis perintah ini di server sekunder:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - Masukkan kata sandi PostgreSQL server utama dan tekan enter. Selanjutnya, tambahkan perintah berikut untuk konfigurasi pemulihan: Edit Command
nano /var/lib/postgresql/10/main/recovery.confKonfigurasi
standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Di sini, YOUR_PASSWORD adalah kata sandi untuk pengguna replikasi di server utama yang dibuat PostgreSQL
- Setelah kata sandi ditetapkan, Anda harus memulai ulang database PostgreSQL sekunder sejak dihentikan:
systemctl start postgresqlMenguji Pengaturan Anda
Sekarang setelah kita melakukan langkah-langkahnya, mari kita uji proses replikasi dan amati database server sekunder. Untuk ini, kami membuat tabel di server utama dan mengamati apakah hal yang sama tercermin di server sekunder.
Mari kita lakukan.
- Karena kami membuat tabel di server utama, Anda harus masuk ke server utama:
su - postgres psql - Sekarang kita membuat tabel sederhana bernama 'testtable' dan memasukkan data ke tabel dengan menjalankan kueri PostgreSQL berikut di terminal:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Amati database server sekunder PostgreSQL dengan masuk ke server sekunder:
su - postgres psql - Sekarang, kami memeriksa apakah tabel 'testtable' ada, dan dapat mengembalikan data dengan menjalankan kueri PostgreSQL berikut di terminal. Perintah ini pada dasarnya menampilkan seluruh tabel.
select * from testtable;
Ini adalah output dari tabel pengujian:
| websites | ------------------- | section.com | | google.com | | github.com | --------------------Anda harus dapat mengamati data yang sama dengan yang ada di server utama.
Jika Anda melihat hal di atas, maka Anda telah berhasil melakukan proses replikasi!
Apa Langkah Failover Manual PostgreSQL?
Mari kita bahas langkah-langkah untuk failover manual PostgreSQL:
- Hancurkan server utama.
- Promosikan server siaga dengan menjalankan perintah berikut di server siaga:
./pg_ctl promote -D ../sb_data/ server promoting - Hubungkan ke server siaga yang dipromosikan dan masukkan baris:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values (4,'Four');
Jika insert berfungsi dengan baik, maka standby, yang sebelumnya merupakan server read-only, telah dipromosikan sebagai server utama baru.
Cara Mengotomatiskan Failover di PostgreSQL
Menyiapkan failover otomatis itu mudah.
Anda memerlukan EDB PostgreSQL failover manager (EFM). Setelah mengunduh dan menginstal EFM pada setiap node utama dan siaga, Anda dapat membuat Cluster EFM, yang terdiri dari node utama, satu atau lebih node Siaga, dan node Witness opsional yang mengonfirmasi pernyataan jika terjadi kegagalan.
EFM terus memantau kesehatan sistem dan mengirimkan peringatan email berdasarkan peristiwa sistem. Ketika terjadi kegagalan, secara otomatis beralih ke siaga terbaru dan mengkonfigurasi ulang semua server siaga lainnya untuk mengenali node utama baru.
Ini juga mengonfigurasi ulang penyeimbang beban (seperti pgPool) dan mencegah terjadinya “split-brain” (ketika dua node masing-masing menganggapnya utama).
Ringkasan
Karena jumlah data yang tinggi, skalabilitas dan keamanan telah menjadi dua kriteria terpenting dalam manajemen basis data, terutama dalam lingkungan transaksi. Meskipun kami dapat meningkatkan skalabilitas secara vertikal dengan menambahkan lebih banyak sumber daya/perangkat keras ke node yang ada, hal itu tidak selalu memungkinkan, seringkali karena biaya atau keterbatasan penambahan perangkat keras baru.
Oleh karena itu, skalabilitas horizontal diperlukan, yang berarti menambahkan lebih banyak node ke node jaringan yang ada daripada meningkatkan fungsionalitas node yang ada. Di sinilah replikasi PostgreSQL muncul.
Dalam artikel ini, kita telah membahas jenis replikasi PostgreSQL, manfaat, mode replikasi, instalasi, dan failover PostgreSQL Antara SMR dan MMR. Sekarang mari kita dengar dari Anda.
Mana yang biasanya Anda terapkan? Fitur database mana yang paling penting bagi Anda dan mengapa? Kami ingin membaca pemikiran Anda! Bagikan di bagian komentar di bawah.